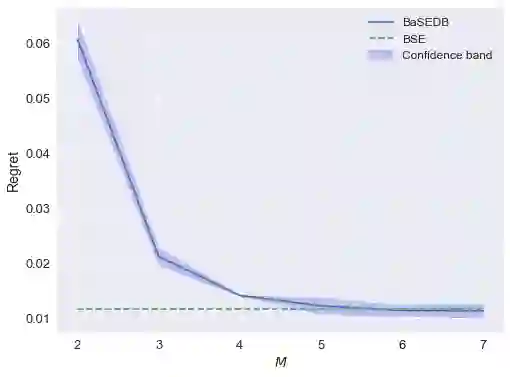
We study nonparametric contextual bandits under batch constraints, where the expected reward for each action is modeled as a smooth function of covariates, and the policy updates are made at the end of each batch of observations. We establish a minimax regret lower bound for this setting and propose Batched Successive Elimination with Dynamic Binning (BaSEDB) that achieves optimal regret (up to logarithmic factors). In essence, BaSEDB dynamically splits the covariate space into smaller bins, carefully aligning their widths with the batch size. We also show the suboptimality of static binning under batch constraints, highlighting the necessity of dynamic binning. Additionally, our results suggest that a nearly constant number of policy updates can attain optimal regret in the fully online setting.
翻译:我们研究了批量约束下的非参数上下文赌博机问题,其中每个动作的期望奖励被建模为协变量的光滑函数,策略更新在每批观测结束时执行。我们为该设定建立了极小化最坏遗憾下界,并提出了一种名为动态分箱的批量序贯消除算法(BaSEDB),该算法实现了最优遗憾(对数因子内)。本质上,BaSEDB动态地将协变量空间划分为更小的分箱,并精确调整分箱宽度以匹配批量大小。我们还证明了在批量约束下静态分箱的次优性,强调了动态分箱的必要性。此外,我们的结果表明,在全在线设定中,近乎恒定数量的策略更新即可达到最优遗憾。