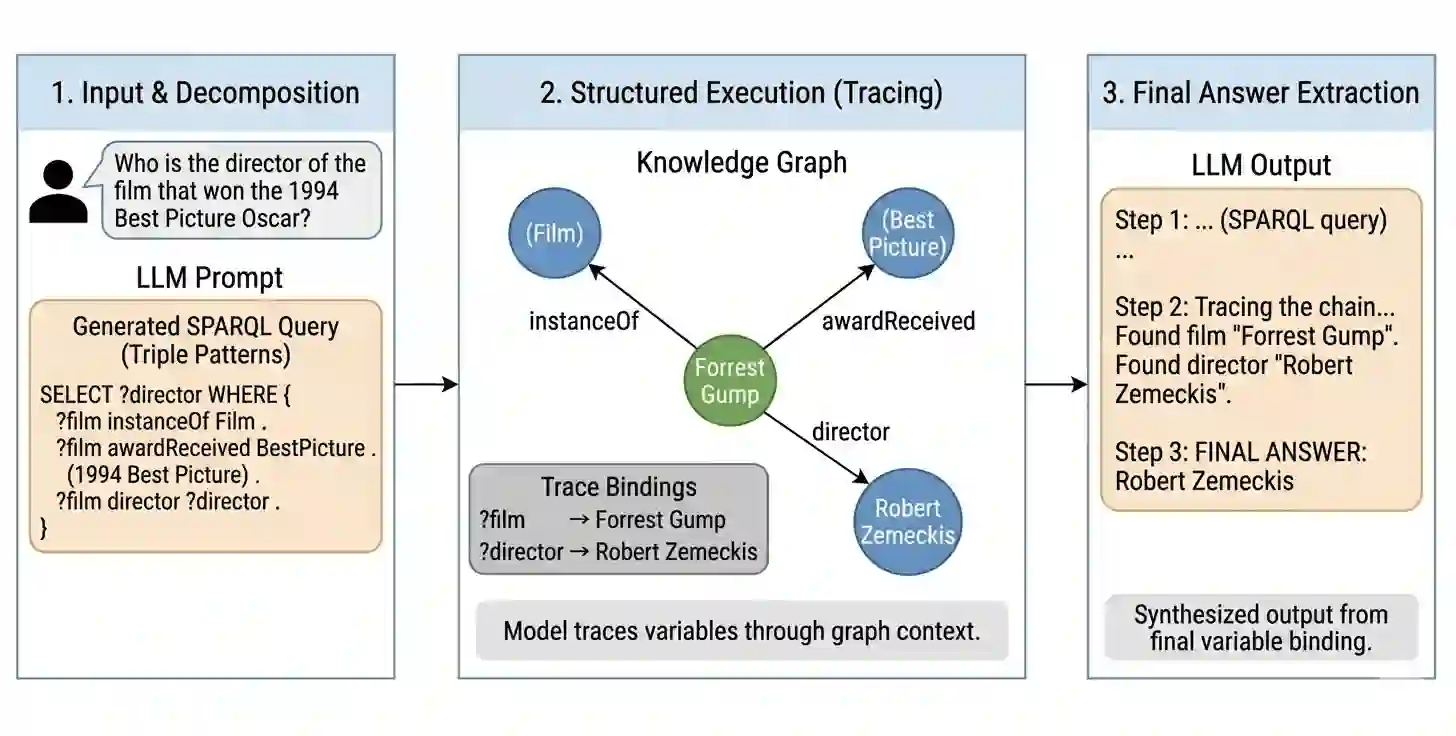
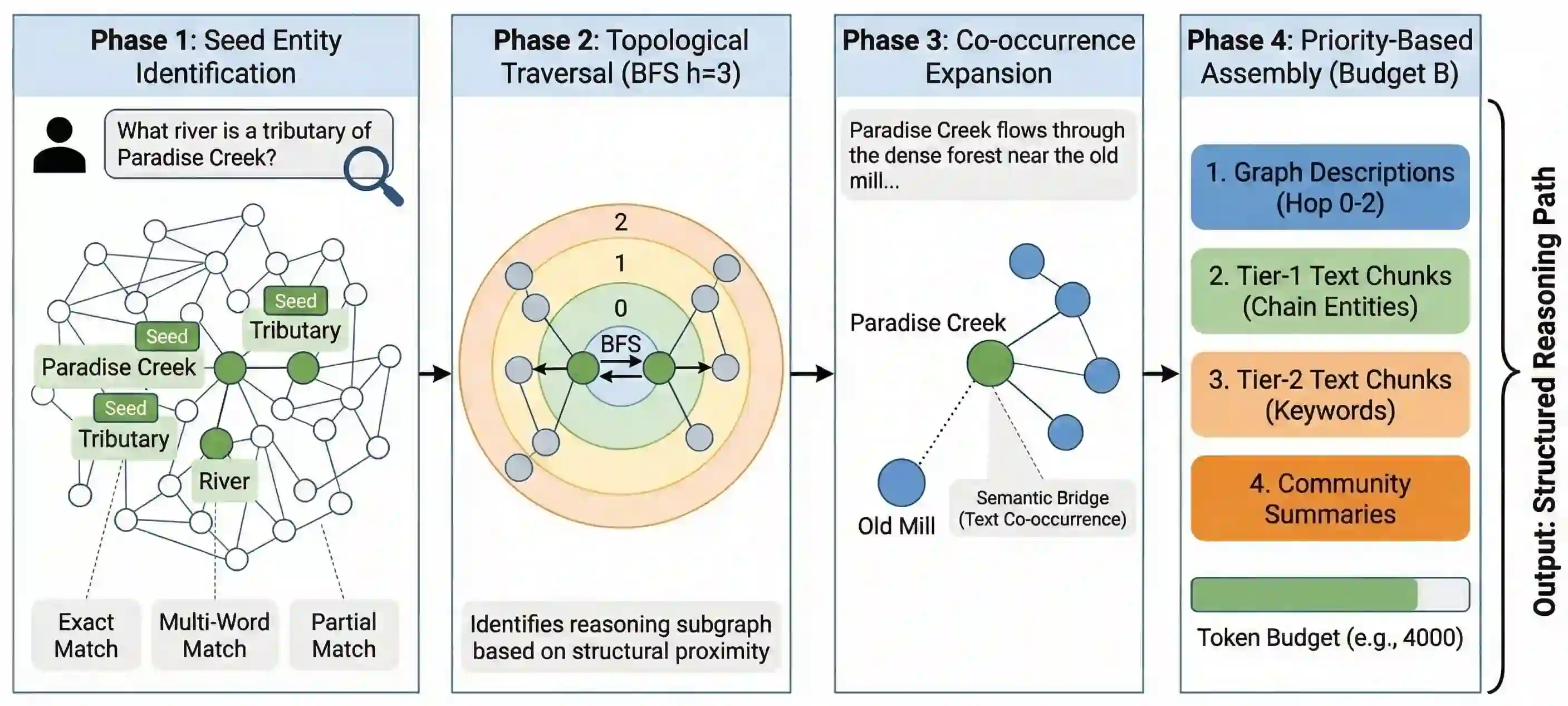
Graph-RAG systems achieve strong multi-hop question answering by indexing documents into knowledge graphs, but strong retrieval does not guarantee strong answers. Evaluating KET-RAG, a leading Graph-RAG system, on three multi-hop QA benchmarks (HotpotQA, MuSiQue, 2WikiMultiHopQA), we find that 77% to 91% of questions have the gold answer in the retrieved context, yet accuracy is only 35% to 78%, and 73% to 84% of errors are reasoning failures. We propose two augmentations: (i) SPARQL chain-of-thought prompting, which decomposes questions into triple-pattern queries aligned with the entity-relationship context, and (ii) graph-walk compression, which compresses the context by ~60% via knowledge-graph traversal with no LLM calls. SPARQL CoT improves accuracy by +2 to +14 pp; graph-walk compression adds +6 pp on average when paired with structured prompting on smaller models. Surprisingly, we show that, with question-type routing, a fully augmented budget open-weight Llama-8B model matches or exceeds the unaugmented Llama-70B baseline on all three benchmarks at ~12x lower cost. A replication on LightRAG confirms that our augmentations transfer across Graph-RAG systems.
翻译:图检索增强生成系统通过将文档索引为知识图谱,在多跳问答任务中表现出色,但强大的检索能力并不能保证生成优质答案。我们在三个多跳问答基准数据集(HotpotQA、MuSiQue、2WikiMultiHopQA)上评估领先的图检索增强生成系统KET-RAG,发现77%至91%的问题其标准答案已存在于检索上下文中,但准确率仅为35%至78%,且73%至84%的错误源于推理失败。我们提出两种增强方案:(i)SPARQL思维链提示,将问题分解为与实体关系上下文对齐的三元组查询模式;(ii)图游走压缩,通过知识图谱遍历将上下文压缩约60%且无需调用大语言模型。SPARQL思维链提示将准确率提升2至14个百分点;当与结构化提示结合应用于较小模型时,图游走压缩平均带来6个百分点的增益。值得注意的是,通过问题类型路由机制,完全增强的轻量化开源模型Llama-8B在三个基准测试中均达到或超越未增强的Llama-70B基线性能,而成本降低约12倍。在LightRAG上的复现实验证实,我们的增强方案可迁移至其他图检索增强生成系统。