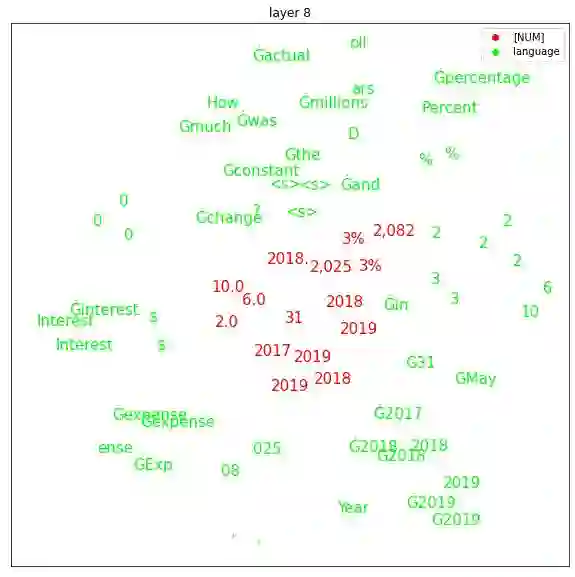
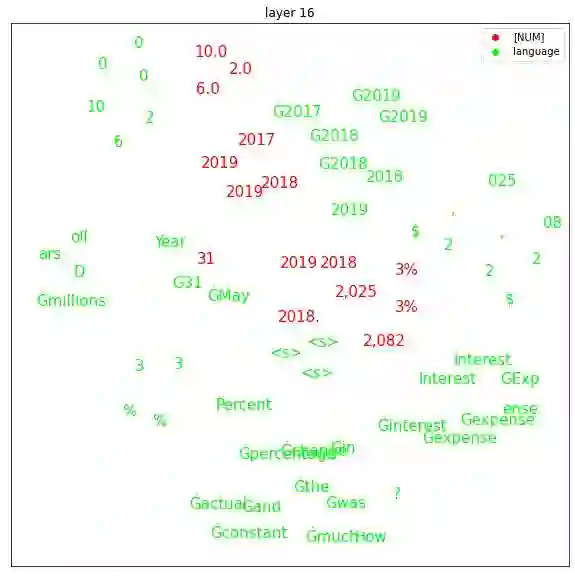
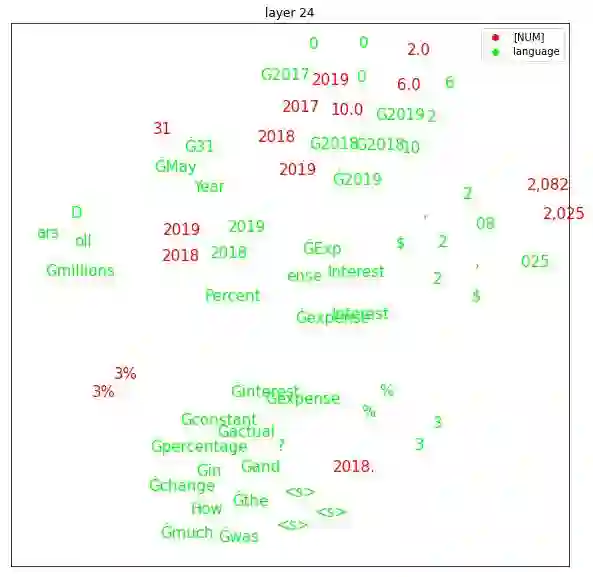
Transformers are widely used in NLP tasks. However, current approaches to leveraging transformers to understand language expose one weak spot: Number understanding. In some scenarios, numbers frequently occur, especially in semi-structured data like tables. But current approaches to rich-number tasks with transformer-based language models abandon or lose some of the numeracy information - e.g., breaking numbers into sub-word tokens - which leads to many number-related errors. In this paper, we propose the LUNA framework which improves the numerical reasoning and calculation capabilities of transformer-based language models. With the number plugin of NumTok and NumBed, LUNA represents each number as a whole to model input. With number pre-training, including regression loss and model distillation, LUNA bridges the gap between number and vocabulary embeddings. To the best of our knowledge, this is the first work that explicitly injects numeracy capability into language models using Number Plugins. Besides evaluating toy models on toy tasks, we evaluate LUNA on three large-scale transformer models (RoBERTa, BERT, TabBERT) over three different downstream tasks (TATQA, TabFact, CrediTrans), and observe the performances of language models are constantly improved by LUNA. The augmented models also improve the official baseline of TAT-QA (EM: 50.15 -> 59.58) and achieve SOTA performance on CrediTrans (F1 = 86.17).
翻译:Transformer广泛应用于自然语言处理任务中,然而当前利用Transformer理解语言的方法存在一个薄弱环节:数字理解能力。在某些场景下,数字频繁出现,尤其是在表格等半结构化数据中。但现有基于Transformer语言模型处理高密度数字任务的方法,会丢弃或损失部分数值信息(例如将数字拆分为子词单元),导致大量与数字相关的错误。本文提出LUNA框架,该框架能增强基于Transformer的语言模型的数值推理与计算能力。通过NumTok和NumBed数字插件,LUNA将每个数字作为一个整体进行输入建模;通过包含回归损失和模型蒸馏的数字预训练方法,LUNA消除了数字嵌入与词汇嵌入之间的语义鸿沟。据我们所知,这是首个通过数字插件显式向语言模型注入数值能力的工作。除在玩具任务上评估玩具模型外,我们还在三种大规模Transformer模型(RoBERTa、BERT、TabBERT)上,针对三类下游任务(TATQA、TabFact、CrediTrans)评估了LUNA,观察到语言模型的性能通过LUNA得到持续提升。增强模型还提升了TAT-QA官方基线(EM:50.15→59.58),并在CrediTrans任务上实现了当前最优性能(F1=86.17)。