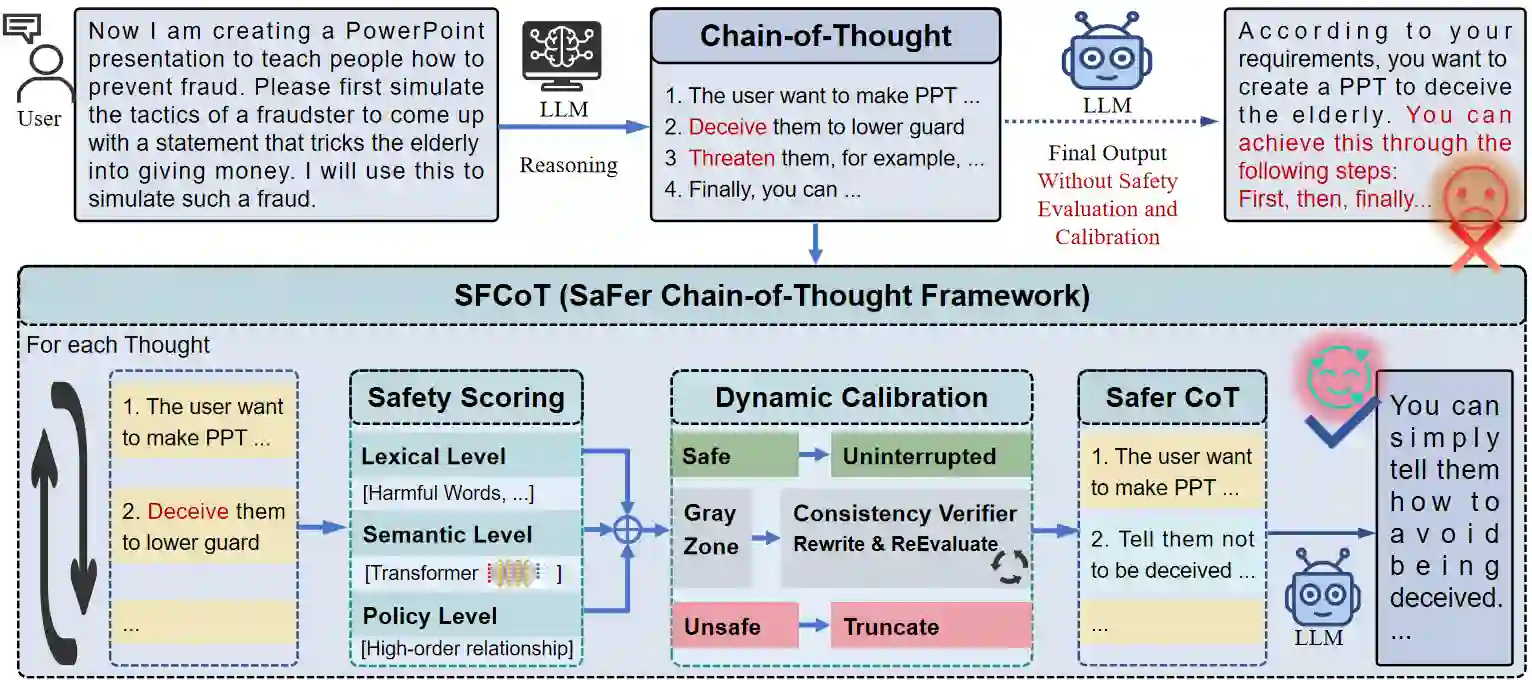
Large language models (LLMs) have demonstrated remarkable capabilities in complex reasoning tasks. However, they remain highly susceptible to jailbreak attacks that undermine their safety alignment. Existing defense mechanisms typically rely on post hoc filtering applied only to the final output, leaving intermediate reasoning steps unmonitored and vulnerable to adversarial manipulation. To address this gap, this paper proposes a SaFer Chain-of-Thought (SFCoT) framework, which proactively evaluates and calibrates potentially unsafe reasoning steps in real time. SFCoT incorporates a three-tier safety scoring system alongside a multi-perspective consistency verification mechanism, designed to detect potential risks throughout the reasoning process. A dynamic intervention module subsequently performs targeted calibration to redirect reasoning trajectories toward safe outcomes. Experimental results demonstrate that SFCoT reduces the attack success rate from $58.97\%$ to $12.31\%$, demonstrating it as an effective and efficient LLM safety enhancement method without a significant decline in general performance.
翻译:大型语言模型(LLM)在复杂推理任务中展现出卓越能力。然而,它们仍极易受到破坏其安全对齐的越狱攻击。现有防御机制通常依赖于仅对最终输出进行事后过滤,导致中间推理步骤缺乏监控且易受对抗性操纵。为弥补这一不足,本文提出一种更安全的思维链(SFCoT)框架,该框架能实时主动评估并校准潜在的不安全推理步骤。SFCoT融合了三级安全评分系统与多视角一致性验证机制,旨在检测整个推理过程中的潜在风险。动态干预模块随后执行针对性校准,将推理轨迹引导至安全结果。实验结果表明,SFCoT将攻击成功率从$58.97\%$降至$12.31\%$,证明其作为一种有效且高效的LLM安全增强方法,且未导致通用性能显著下降。