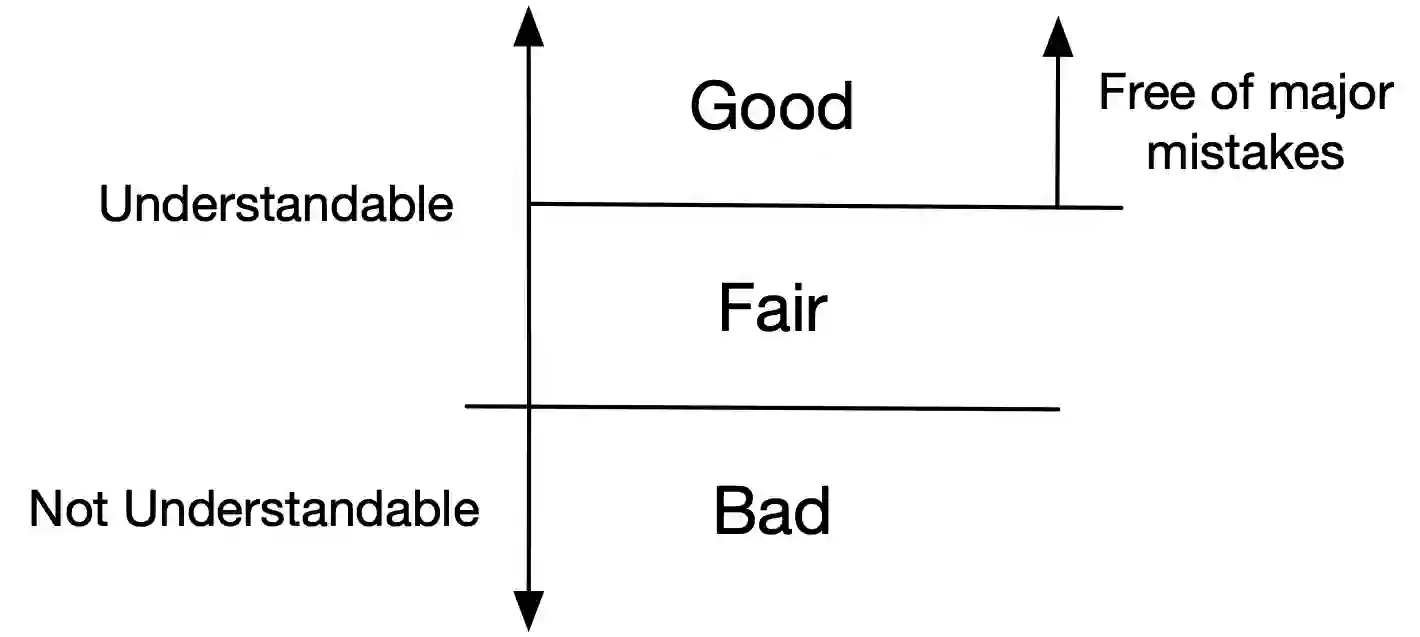
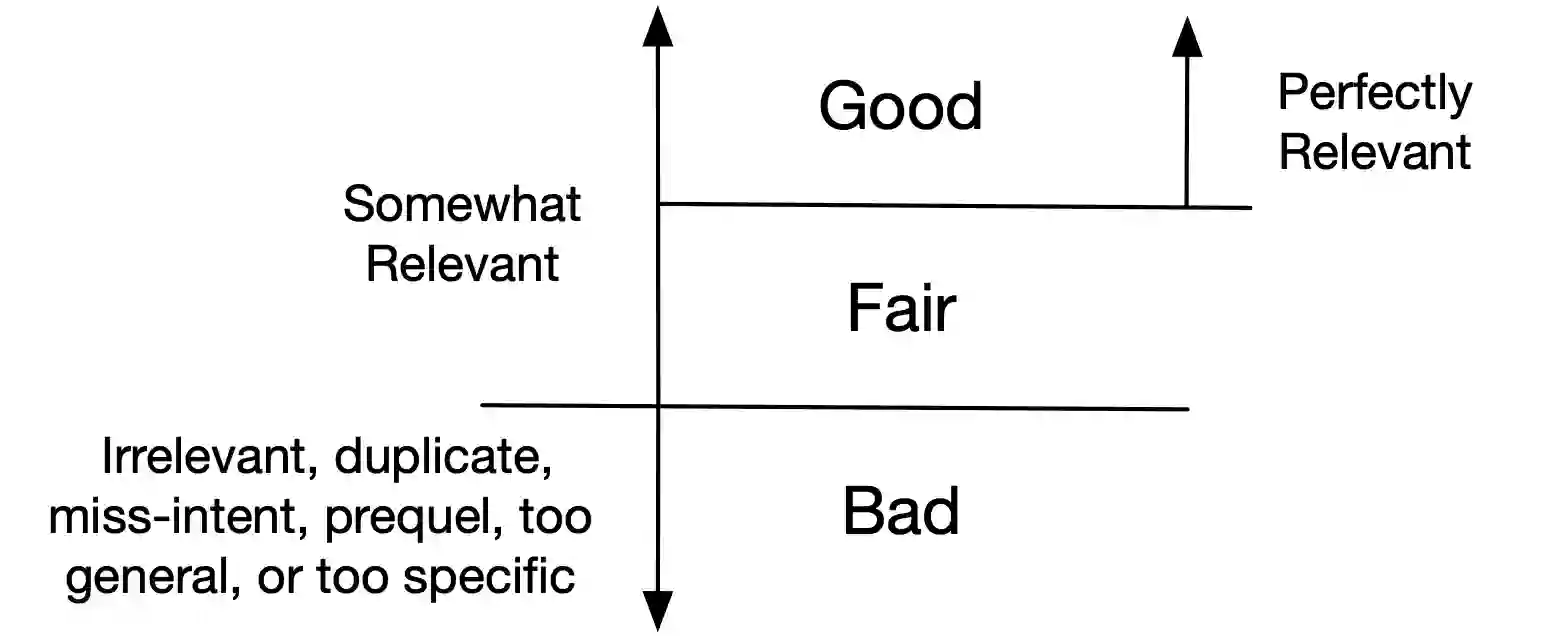
A long-standing challenge for search and conversational assistants is query intention detection in ambiguous queries. Asking clarifying questions in conversational search has been widely studied and considered an effective solution to resolve query ambiguity. Existing work have explored various approaches for clarifying question ranking and generation. However, due to the lack of real conversational search data, they have to use artificial datasets for training, which limits their generalizability to real-world search scenarios. As a result, the industry has shown reluctance to implement them in reality, further suspending the availability of real conversational search interaction data. The above dilemma can be formulated as a cold start problem of clarifying question generation and conversational search in general. Furthermore, even if we do have large-scale conversational logs, it is not realistic to gather training data that can comprehensively cover all possible queries and topics in open-domain search scenarios. The risk of fitting bias when training a clarifying question retrieval/generation model on incomprehensive dataset is thus another important challenge. In this work, we innovatively explore generating clarifying questions in a zero-shot setting to overcome the cold start problem and we propose a constrained clarifying question generation system which uses both question templates and query facets to guide the effective and precise question generation. The experiment results show that our method outperforms existing state-of-the-art zero-shot baselines by a large margin. Human annotations to our model outputs also indicate our method generates 25.2\% more natural questions, 18.1\% more useful questions, 6.1\% less unnatural and 4\% less useless questions.
翻译:对话式搜索与助手的长期挑战在于歧义查询的意图检测。在对话式搜索中提出澄清问题已被广泛研究,并被视为解决查询歧义的有效方案。现有工作探索了澄清问题排序和生成的多种方法。然而,由于缺乏真实的对话式搜索数据,研究者不得不使用人工构建的数据集进行训练,这限制了模型在真实搜索场景中的泛化能力。因此,行业在实际部署中表现出犹豫态度,进一步阻碍了真实对话式搜索互动数据的获取。上述困境可归纳为对话式搜索及澄清问题生成的冷启动问题。此外,即便拥有大规模对话日志,在开放域搜索场景中收集能全面覆盖所有可能的查询与主题的训练数据也不切实际。基于不完整数据集训练澄清问题检索/生成模型时存在的拟合偏差风险,是另一个重要挑战。本文创新性地探索了零样本场景下的澄清问题生成,以克服冷启动问题,并提出了一种基于约束的澄清问题生成系统,该系统通过问题模板与查询分面引导有效且精确的问题生成。实验结果表明,我们的方法在性能上大幅超越现有最先进的零样本基线模型。人工标注结果亦显示,我们的方法生成的自然问题数量增加25.2%,有用问题数量增加18.1%,不自然问题减少6.1%,无效问题减少4%。