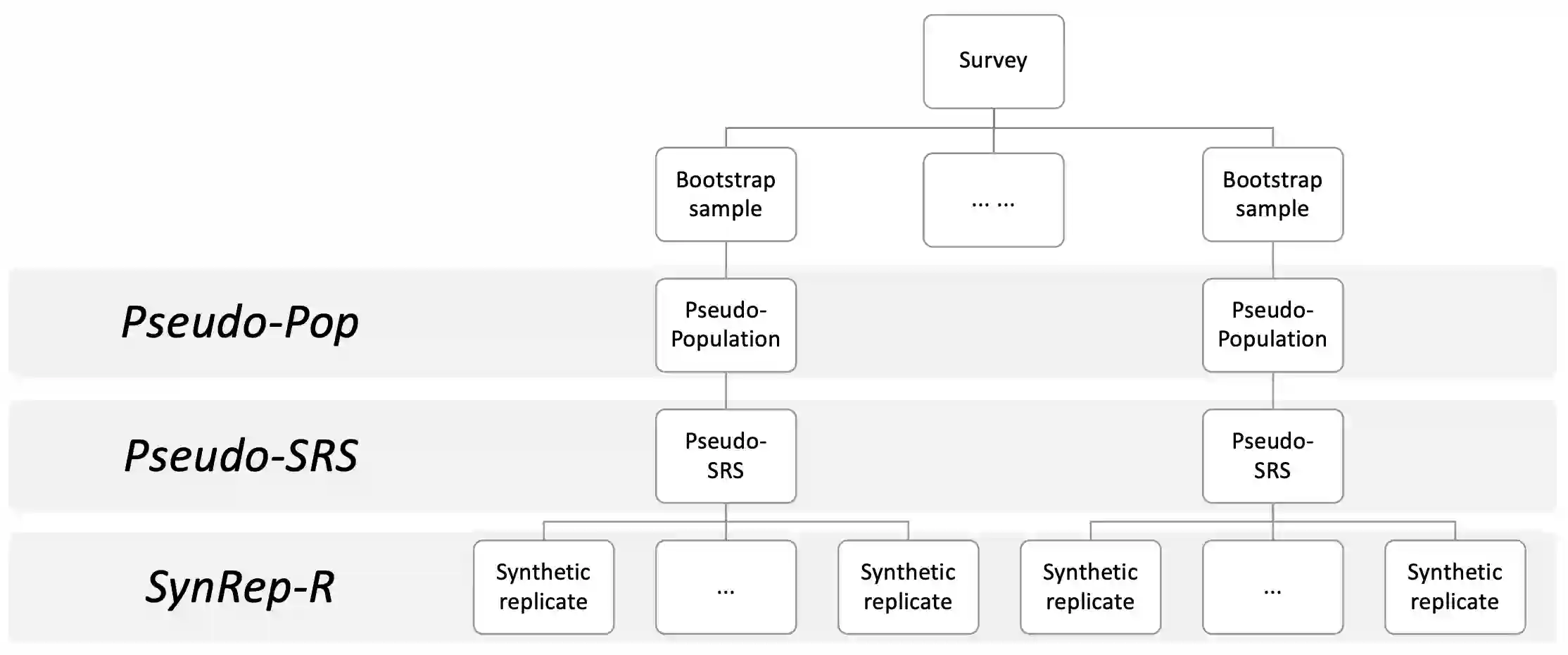
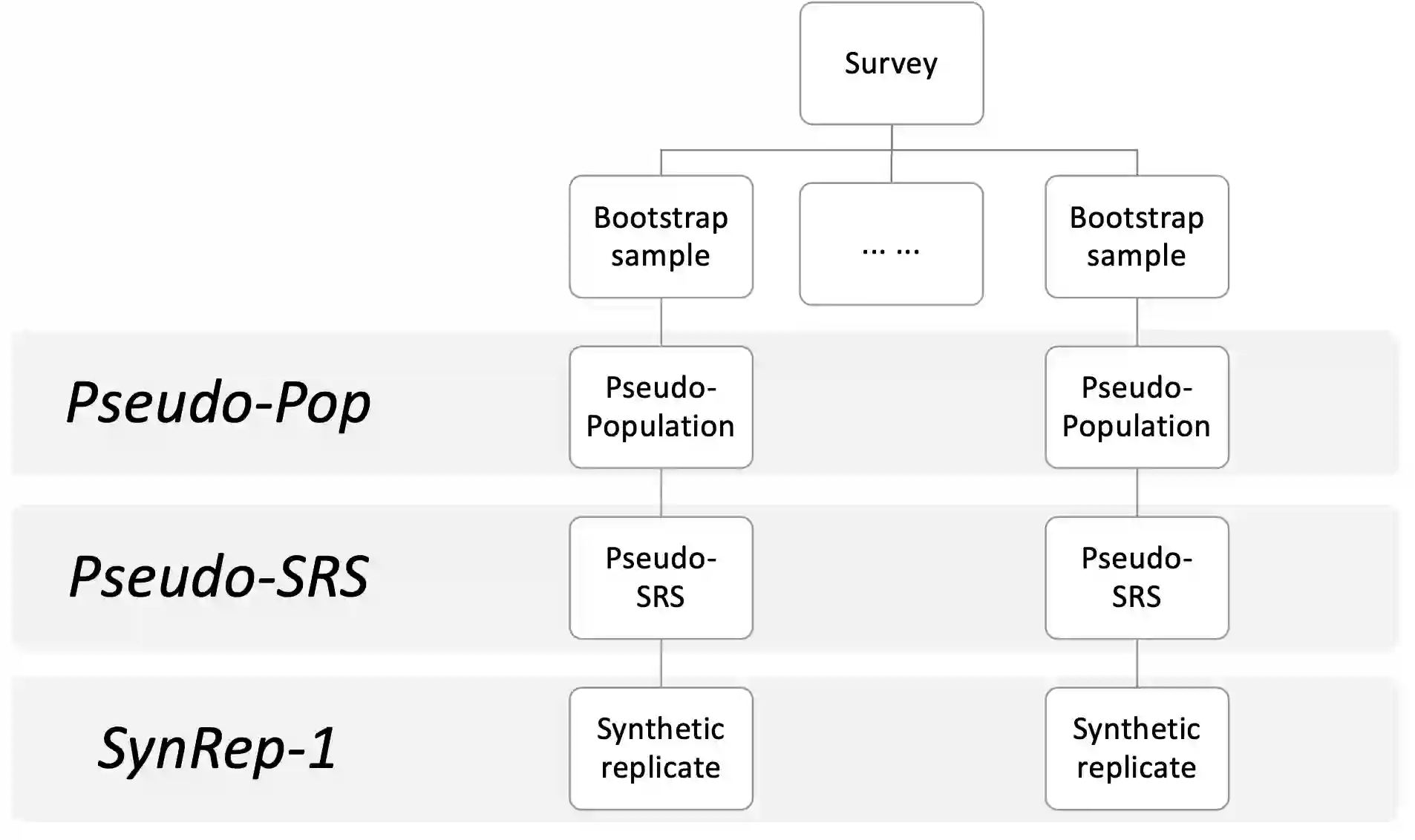
When seeking to release public use files for confidential data, statistical agencies can generate fully synthetic data. We propose an approach for making fully synthetic data from surveys collected with complex sampling designs. Specifically, we generate pseudo-populations by applying the weighted finite population Bayesian bootstrap to account for survey weights, take simple random samples from those pseudo-populations, estimate synthesis models using these simple random samples, and release simulated data drawn from the models as the public use files. We use the framework of multiple imputation to enable variance estimation using two data generation strategies. In the first, we generate multiple data sets from each simple random sample, whereas in the second, we generate a single synthetic data set from each simple random sample. We present multiple imputation combining rules for each setting. We illustrate each approach and the repeated sampling properties of the combining rules using simulation studies.
翻译:在寻求发布机密数据的公共使用文件时,统计机构可以生成完全合成数据。我们提出了一种方法,用于从采用复杂抽样设计收集的调查中生成完全合成数据。具体而言,我们通过应用加权有限总体贝叶斯自助法来处理调查权重,从而生成伪总体;从这些伪总体中抽取简单随机样本;利用这些简单随机样本估计合成模型;并发布从模型中模拟得到的数据作为公共使用文件。我们采用多重插补框架,通过两种数据生成策略实现方差估计。第一种策略中,我们从每个简单随机样本生成多个数据集;而第二种策略中,我们从每个简单随机样本仅生成一个合成数据集。我们针对每种情形给出了多重插补的组合规则。通过模拟研究,我们展示了每种方法以及组合规则的重复抽样性质。