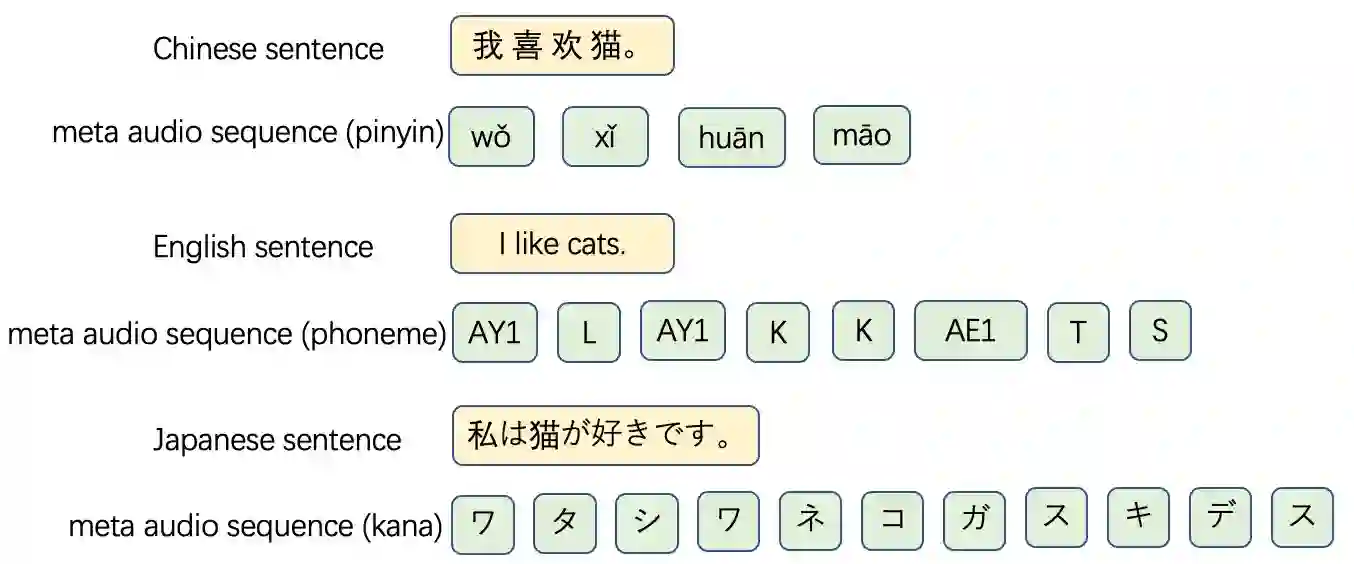
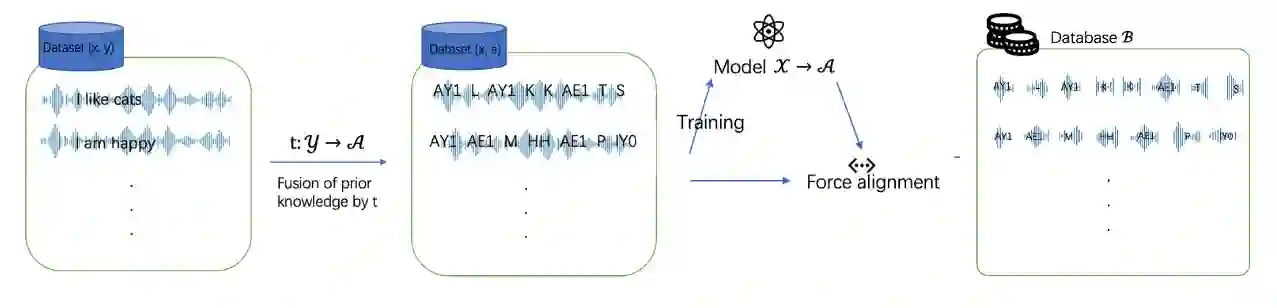
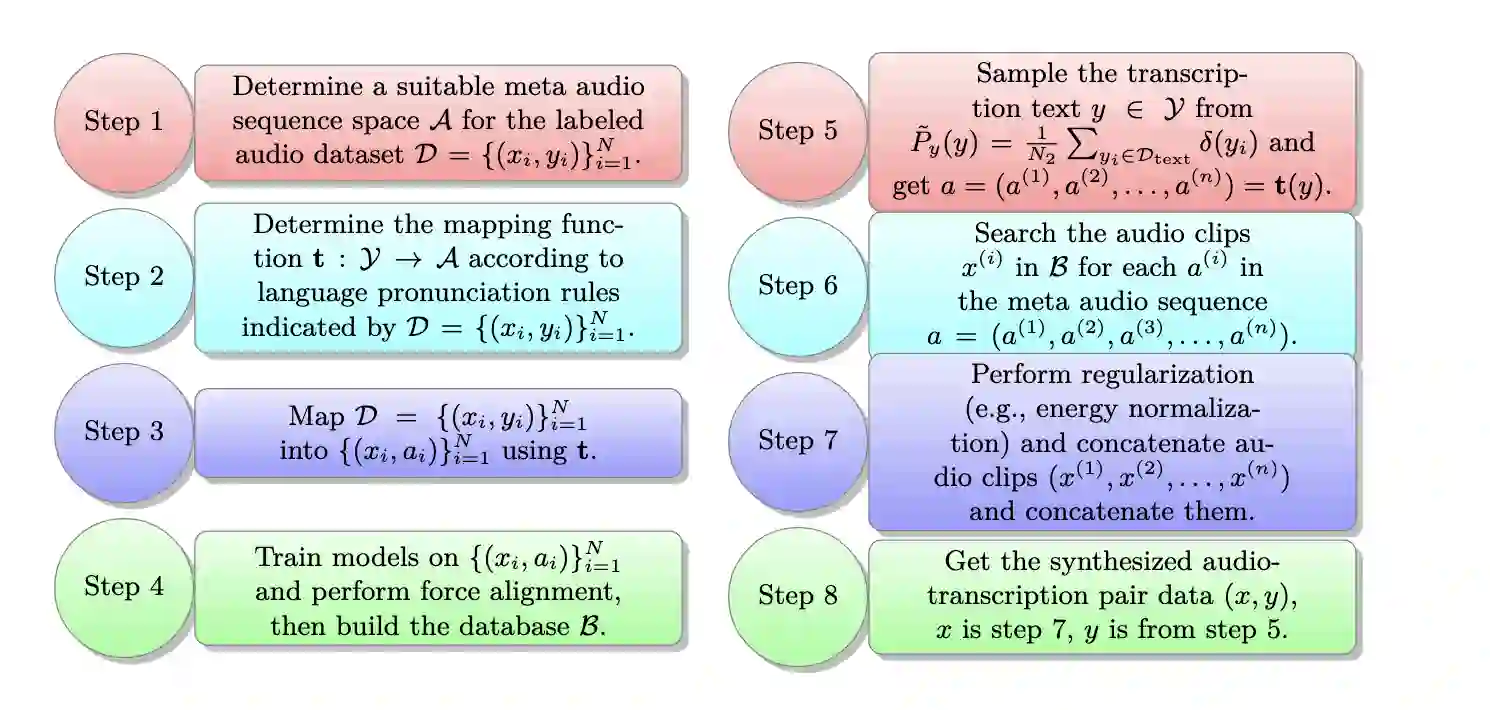
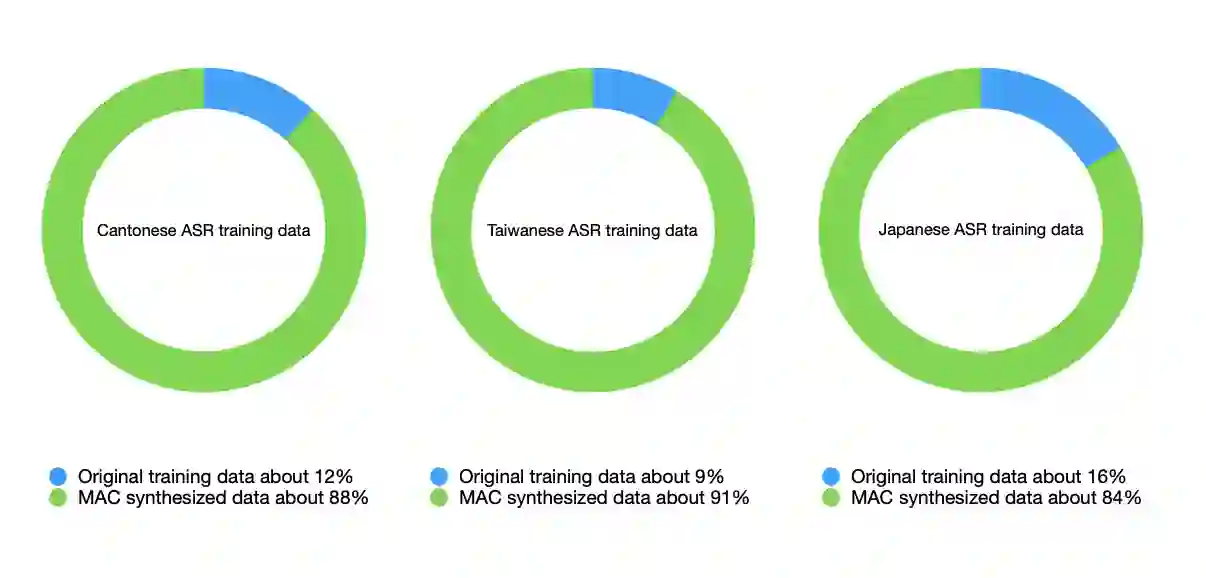
We propose a unified framework for low resource automatic speech recognition tasks named meta audio concatenation (MAC). It is easy to implement and can be carried out in extremely low resource environments. Mathematically, we give a clear description of MAC framework from the perspective of bayesian sampling. In this framework, we leverage a novel concatenative synthesis text-to-speech system to boost the low resource ASR task. By the concatenative synthesis text-to-speech system, we can integrate language pronunciation rules and adjust the TTS process. Furthermore, we propose a broad notion of meta audio set to meet the modeling needs of different languages and different scenes when using the system. Extensive experiments have demonstrated the great effectiveness of MAC on low resource ASR tasks. For CTC greedy search, CTC prefix, attention, and attention rescoring decode mode in Cantonese ASR task, Taiwanese ASR task, and Japanese ASR task the MAC method can reduce the CER by more than 15\%. Furthermore, in the ASR task, MAC beats wav2vec2 (with fine-tuning) on common voice datasets of Cantonese and gets really competitive results on common voice datasets of Taiwanese and Japanese. Among them, it is worth mentioning that we achieve a \textbf{10.9\%} character error rate (CER) on the common voice Cantonese ASR task, bringing about \textbf{30\%} relative improvement compared to the wav2vec2 (with fine-tuning).
翻译:我们提出了一种用于低资源自动语音识别任务的统一框架,名为元音频拼接(Meta Audio Concatenation,MAC)。该框架易于实现,并可在极低资源环境下运行。从数学角度,我们通过贝叶斯采样的视角对MAC框架进行了清晰描述。在此框架中,我们利用一种创新的拼接式合成文本转语音系统来增强低资源ASR任务。通过该拼接式合成文本转语音系统,我们可以整合语言发音规则并调整TTS过程。此外,我们提出了一个广义的元音频集概念,以满足使用该系统时不同语言和不同场景的建模需求。大量实验证明了MAC在低资源ASR任务中的显著有效性。在粤语ASR任务、台语ASR任务和日语ASR任务中,针对CTC贪婪搜索、CTC前缀、注意力及注意力重评分解码模式,MAC方法可将字符错误率(CER)降低超过15%。此外,在ASR任务中,MAC在粤语的Common Voice数据集上击败了wav2vec2(经微调),并在台语和日语的Common Voice数据集上取得了极具竞争力的结果。其中,值得一提的是,我们在Common Voice粤语ASR任务上实现了\textbf{10.9\%}的字符错误率(CER),相比wav2vec2(经微调)带来了约\textbf{30\%}的相对提升。