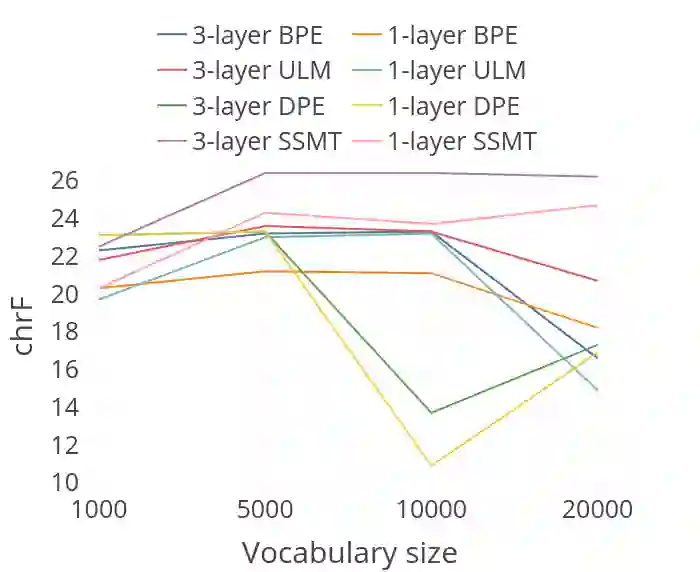
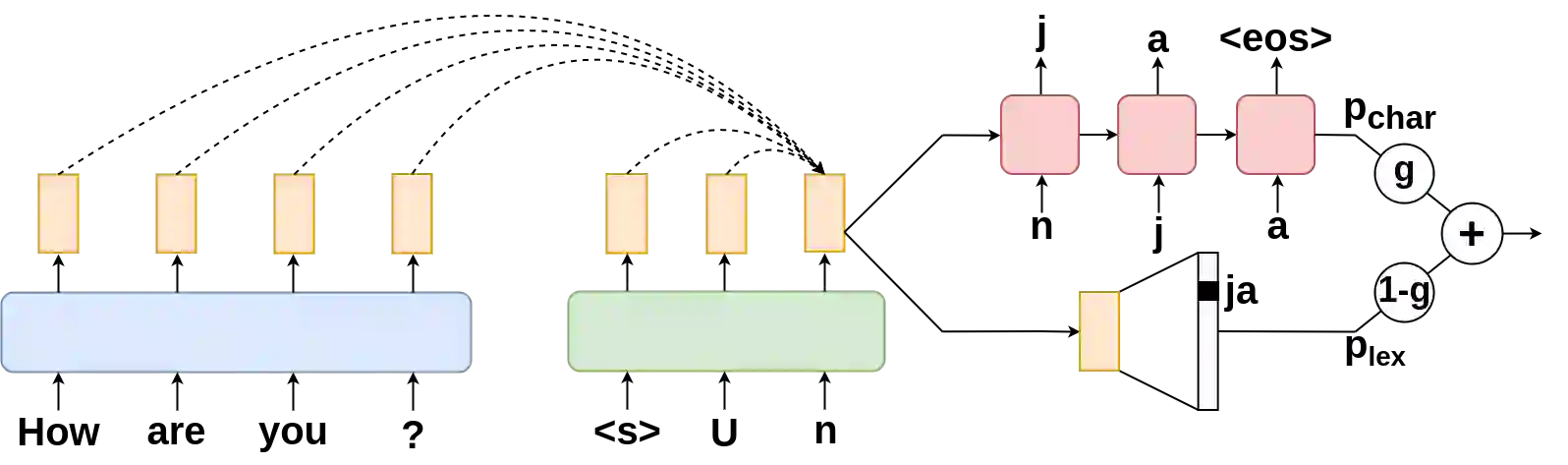Subword segmenters like BPE operate as a preprocessing step in neural machine translation and other (conditional) language models. They are applied to datasets before training, so translation or text generation quality relies on the quality of segmentations. We propose a departure from this paradigm, called subword segmental machine translation (SSMT). SSMT unifies subword segmentation and MT in a single trainable model. It learns to segment target sentence words while jointly learning to generate target sentences. To use SSMT during inference we propose dynamic decoding, a text generation algorithm that adapts segmentations as it generates translations. Experiments across 6 translation directions show that SSMT improves chrF scores for morphologically rich agglutinative languages. Gains are strongest in the very low-resource scenario. SSMT also learns subwords that are closer to morphemes compared to baselines and proves more robust on a test set constructed for evaluating morphological compositional generalisation.
翻译:子词分段器(如BPE)在神经机器翻译及其他(条件)语言模型中作为预处理步骤运行。由于这些分段器在训练前应用于数据集,翻译或文本生成质量依赖于分段的优劣。我们提出一种脱离该范式的方法,称为子词分段机器翻译(SSMT)。SSMT将子词分段与机器翻译统一于单个可训练模型中,在联合学习生成目标句子的同时,学习对目标句单词进行分段。为在推理阶段使用SSMT,我们提出动态解码算法——一种在生成翻译时自适应分段的文本生成算法。在6个翻译方向上的实验表明,SSMT提升了形态丰富的黏着语言的chrF分数,尤其在极低资源场景下增益最为显著。相较于基线方法,SSMT习得的子词更接近语素,并在为评估形态组合泛化能力构建的测试集上展现出更强的鲁棒性。