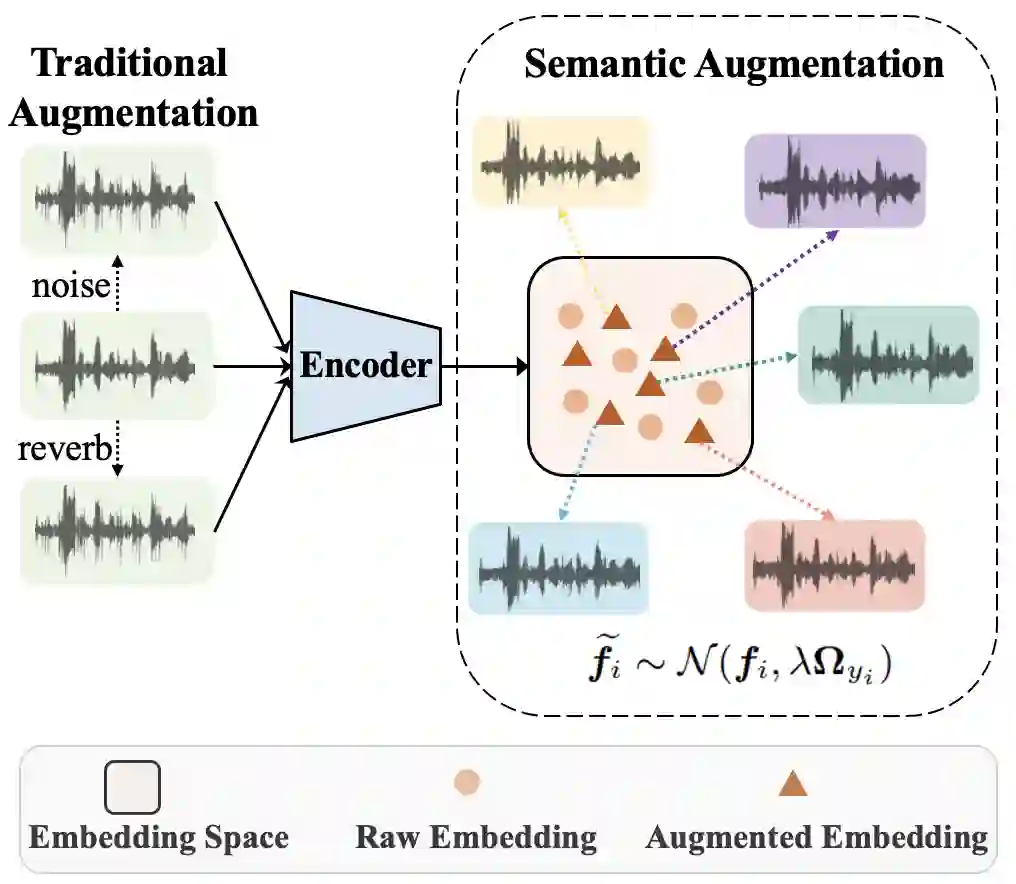
Data augmentation is vital to the generalization ability and robustness of deep neural networks (DNNs) models. Existing augmentation methods for speaker verification manipulate the raw signal, which are time-consuming and the augmented samples lack diversity. In this paper, we present a novel difficulty-aware semantic augmentation (DASA) approach for speaker verification, which can generate diversified training samples in speaker embedding space with negligible extra computing cost. Firstly, we augment training samples by perturbing speaker embeddings along semantic directions, which are obtained from speaker-wise covariance matrices. Secondly, accurate covariance matrices are estimated from robust speaker embeddings during training, so we introduce difficultyaware additive margin softmax (DAAM-Softmax) to obtain optimal speaker embeddings. Finally, we assume the number of augmented samples goes to infinity and derive a closed-form upper bound of the expected loss with DASA, which achieves compatibility and efficiency. Extensive experiments demonstrate the proposed approach can achieve a remarkable performance improvement. The best result achieves a 14.6% relative reduction in EER metric on CN-Celeb evaluation set.
翻译:数据增强对于深度神经网络模型的泛化能力和鲁棒性至关重要。现有针对说话人验证的增强方法多通过对原始信号进行操作,不仅耗时且生成的增强样本缺乏多样性。本文提出一种新颖的面向说话人验证的难度感知语义增强(DASA)方法,该方法能够在说话人嵌入空间中生成多样化的训练样本,且仅需极低的额外计算成本。首先,我们通过沿语义方向扰动说话人嵌入来增强训练样本,这些语义方向由说话人协方差矩阵获取;其次,在训练过程中,我们通过鲁棒的说话人嵌入估计精确的协方差矩阵,因此引入难度感知加性边界Softmax(DAAM-Softmax)以获得最优说话人嵌入;最后,假设增强样本数量趋于无穷大,我们推导出基于DASA的期望损失闭式上界,实现了兼容性与高效性。大量实验表明,所提方法能够实现显著的性能提升。在CN-Celeb评估集上,最佳结果使EER指标相对降低14.6%。