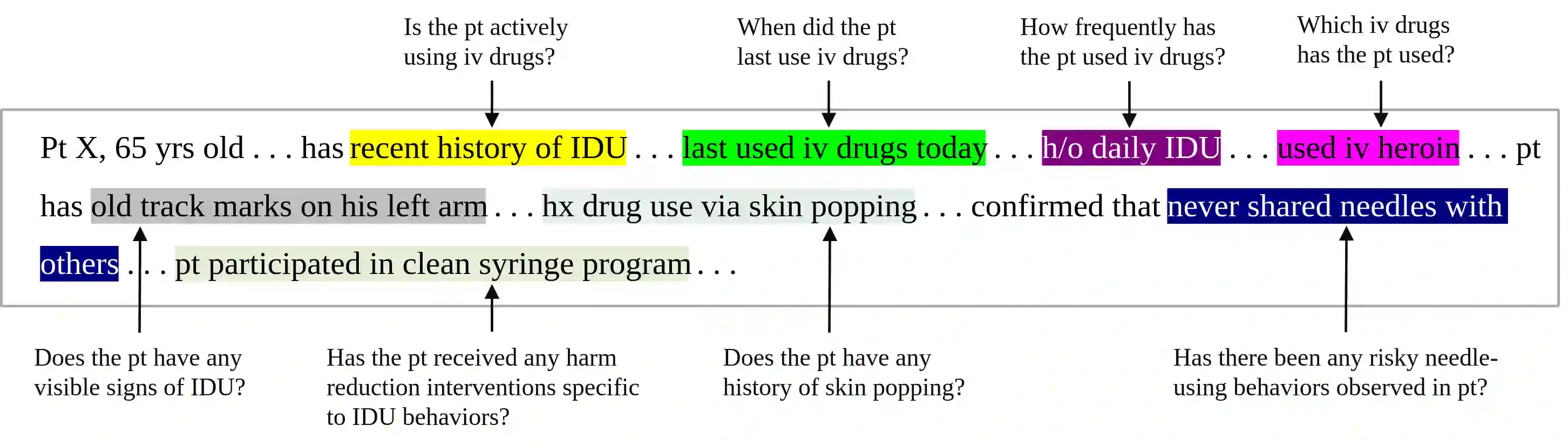
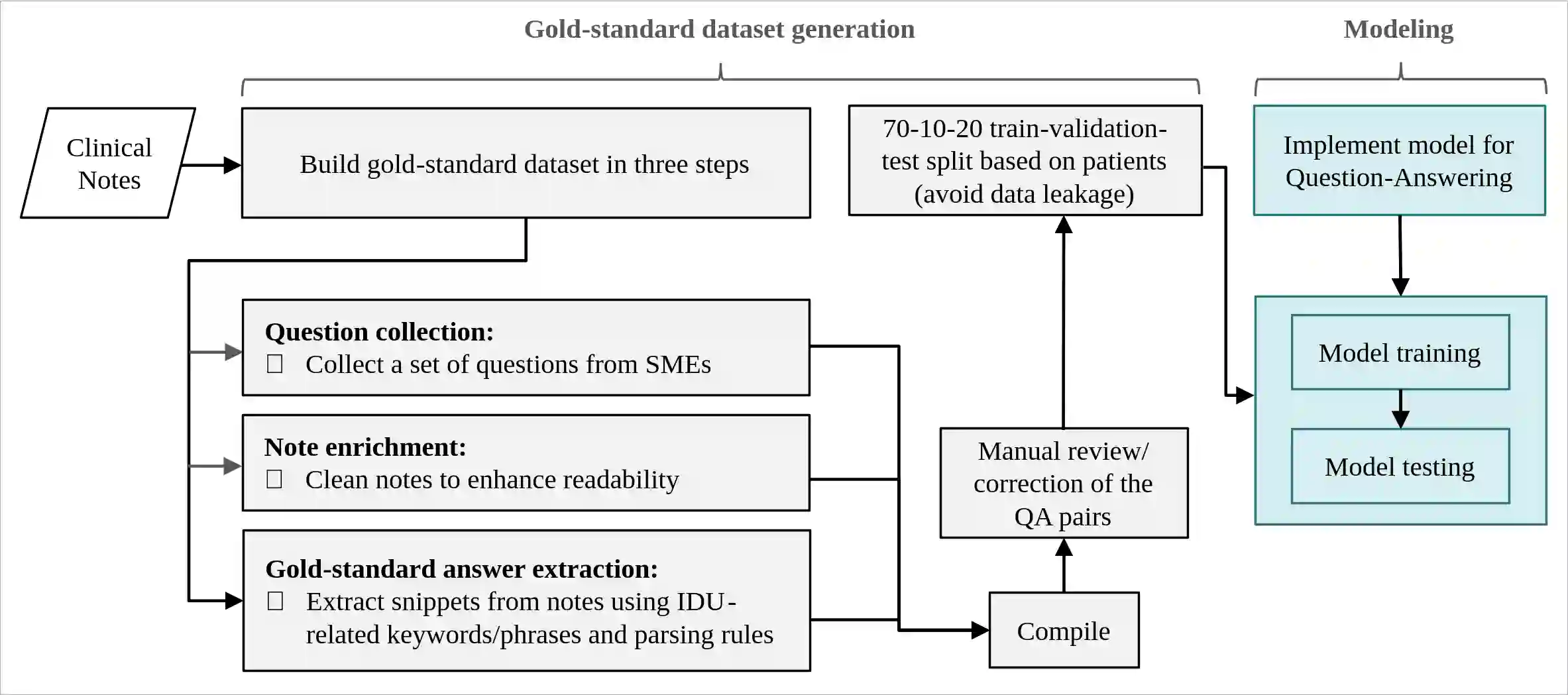
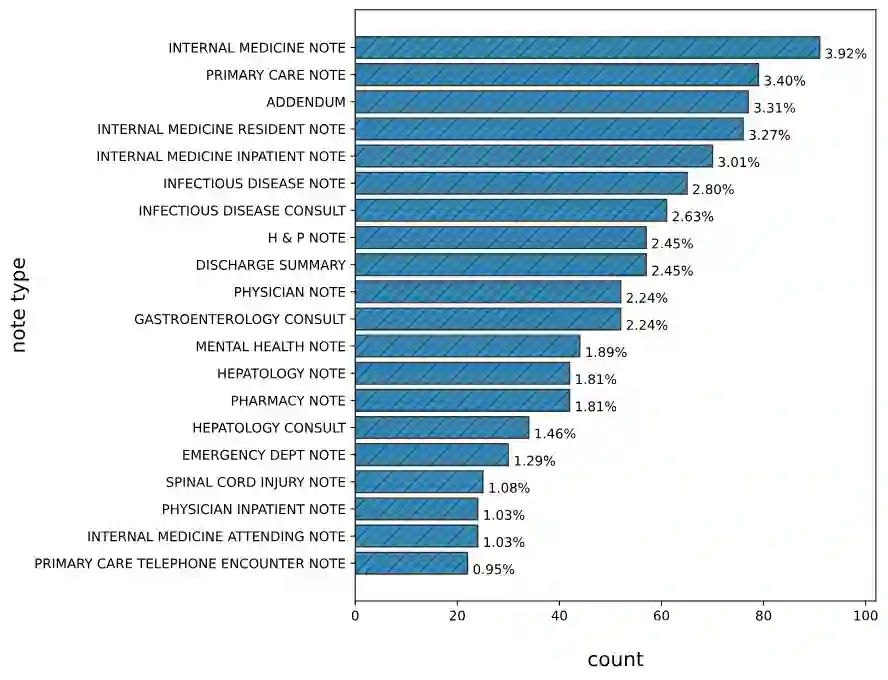
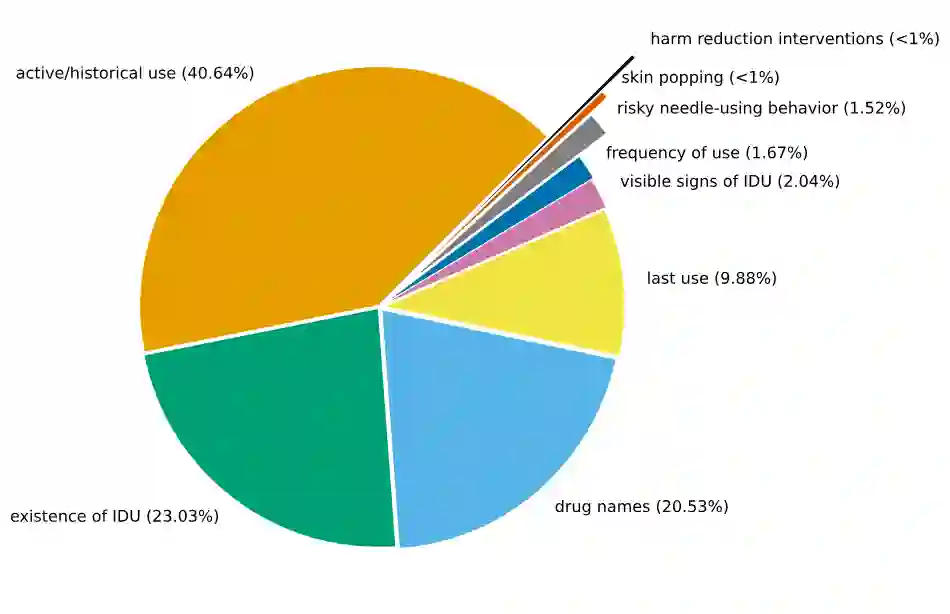
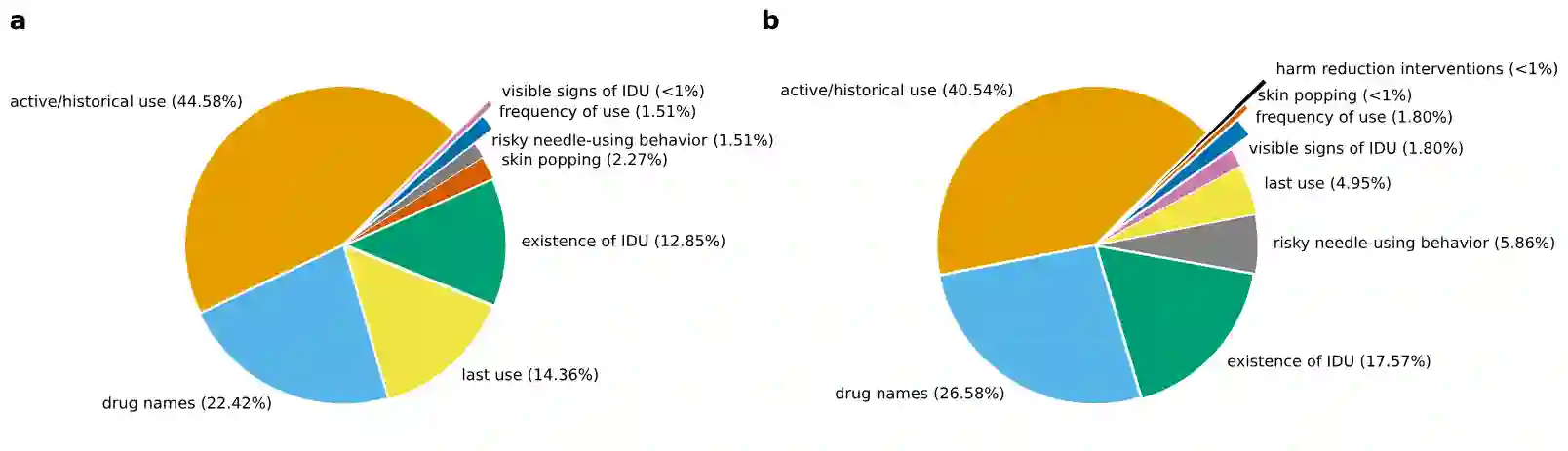
Background: Injection drug use (IDU) is a dangerous health behavior that increases mortality and morbidity. Identifying IDU early and initiating harm reduction interventions can benefit individuals at risk. However, extracting IDU behaviors from patients' electronic health records (EHR) is difficult because there is no International Classification of Disease (ICD) code and the only place IDU information can be indicated is unstructured free-text clinical notes. Although natural language processing can efficiently extract this information from unstructured data, there are no validated tools. Methods: To address this gap in clinical information, we design and demonstrate a question-answering (QA) framework to extract information on IDU from clinical notes. Our framework involves two main steps: (1) generating a gold-standard QA dataset and (2) developing and testing the QA model. We utilize 2323 clinical notes of 1145 patients sourced from the VA Corporate Data Warehouse to construct the gold-standard dataset for developing and evaluating the QA model. We also demonstrate the QA model's ability to extract IDU-related information on temporally out-of-distribution data. Results: Here we show that for a strict match between gold-standard and predicted answers, the QA model achieves 51.65% F1 score. For a relaxed match between the gold-standard and predicted answers, the QA model obtains 78.03% F1 score, along with 85.38% Precision and 79.02% Recall scores. Moreover, the QA model demonstrates consistent performance when subjected to temporally out-of-distribution data. Conclusions: Our study introduces a QA framework designed to extract IDU information from clinical notes, aiming to enhance the accurate and efficient detection of people who inject drugs, extract relevant information, and ultimately facilitate informed patient care.
翻译:背景:注射吸毒(IDU)是一种增加死亡率和发病率的危险健康行为。早期识别IDU并实施减害干预可使高危人群受益。然而,从患者电子健康记录(EHR)中提取IDU行为存在困难,因为缺乏国际疾病分类(ICD)代码,且IDU信息仅能记录在非结构化的自由文本临床笔记中。尽管自然语言处理技术可高效从非结构化数据中提取此类信息,但目前尚无经过验证的工具。方法:为填补这一临床信息缺口,我们设计并验证了一套基于问答(QA)框架的方法,用于从临床笔记中提取IDU信息。该框架包含两个主要步骤:(1)构建黄金标准QA数据集;(2)开发并测试QA模型。我们利用来自VA企业数据仓库的1145名患者的2323份临床笔记,构建用于开发和评估QA模型的黄金标准数据集。此外,我们验证了该QA模型在时间分布外数据上提取IDU相关信息的性能。结果:在黄金标准答案与预测答案严格匹配的条件下,QA模型的F1得分为51.65%。在宽松匹配条件下,QA模型的F1得分为78.03%,精确率为85.38%,召回率为79.02%。此外,该模型在时间分布外数据上表现出稳定的性能。结论:本研究提出了一套旨在从临床笔记中提取IDU信息的QA框架,以期提高注射吸毒人群的精准检测效率,提取相关临床信息,最终促进个体化医疗决策。