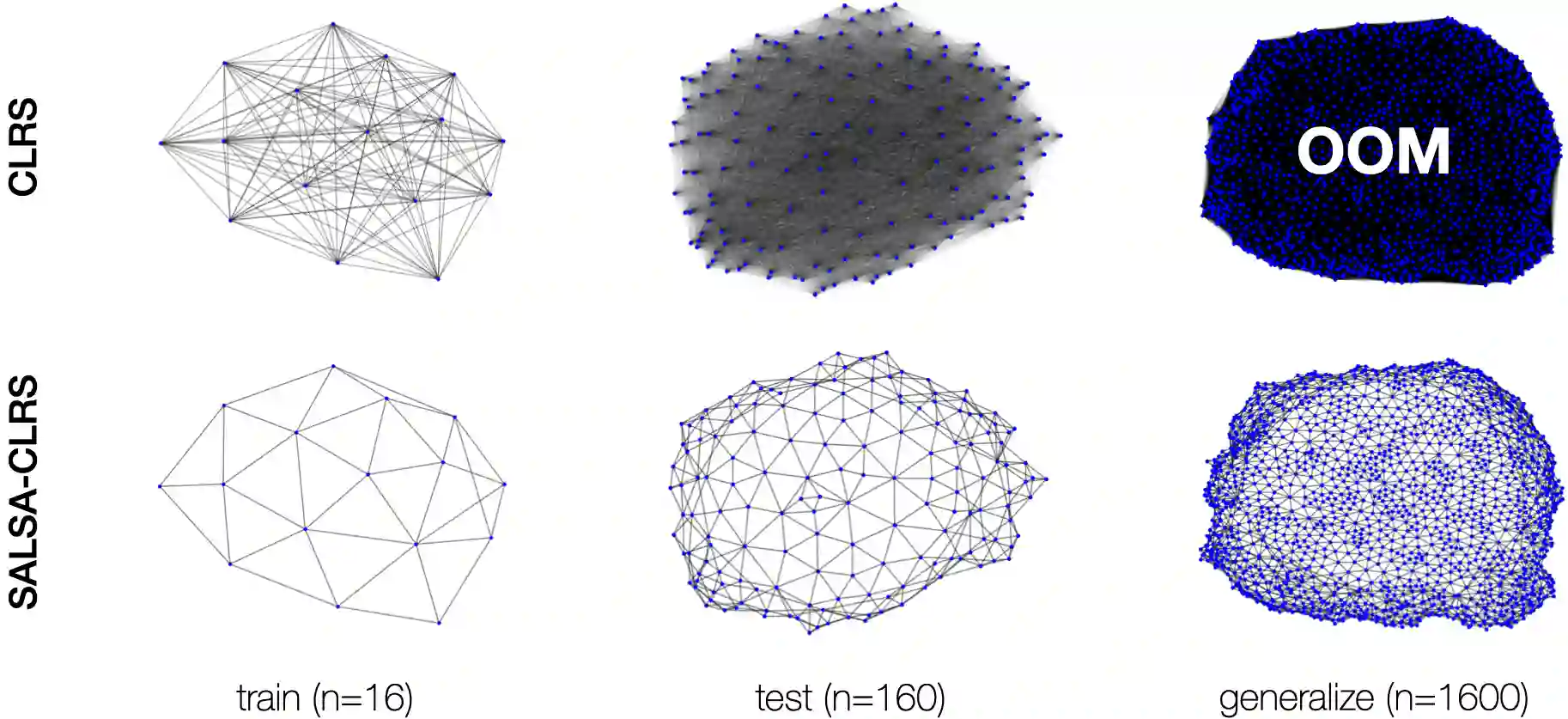
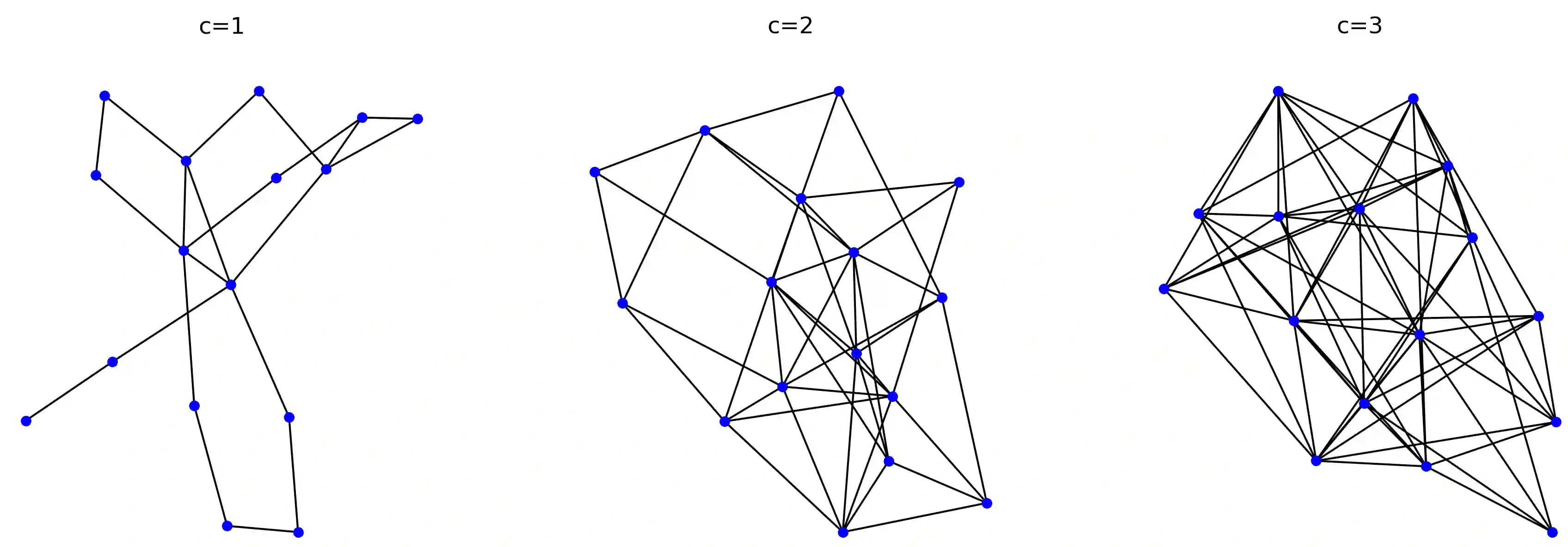
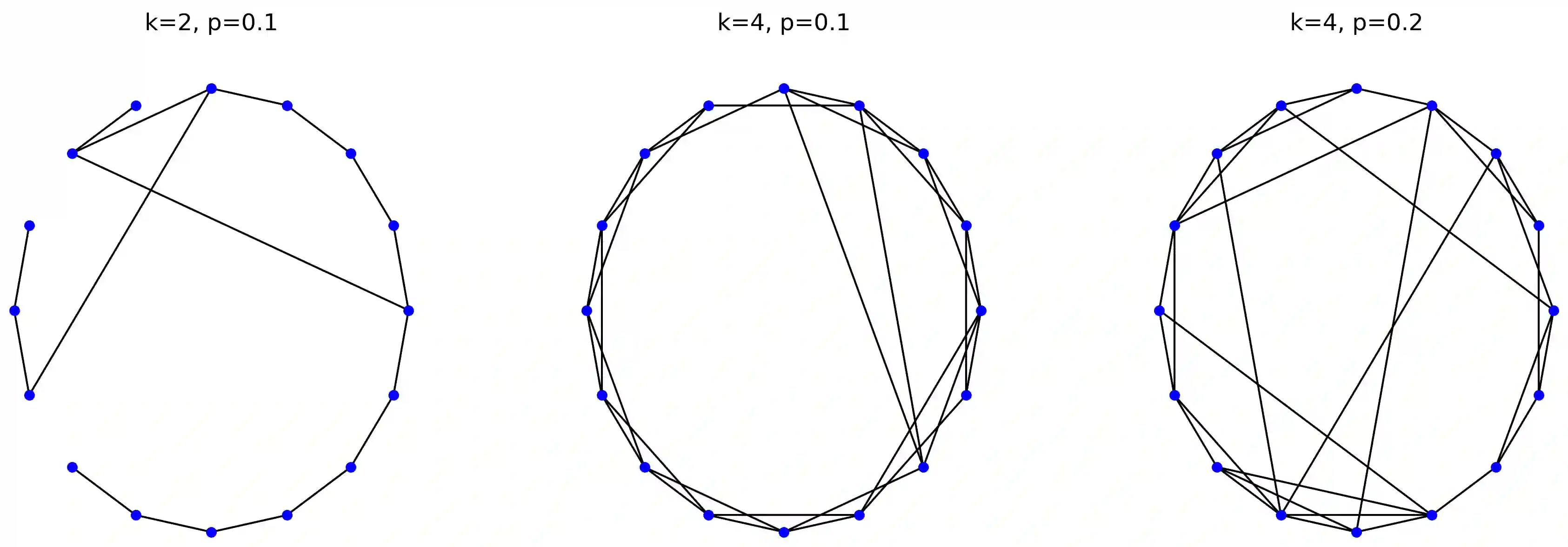
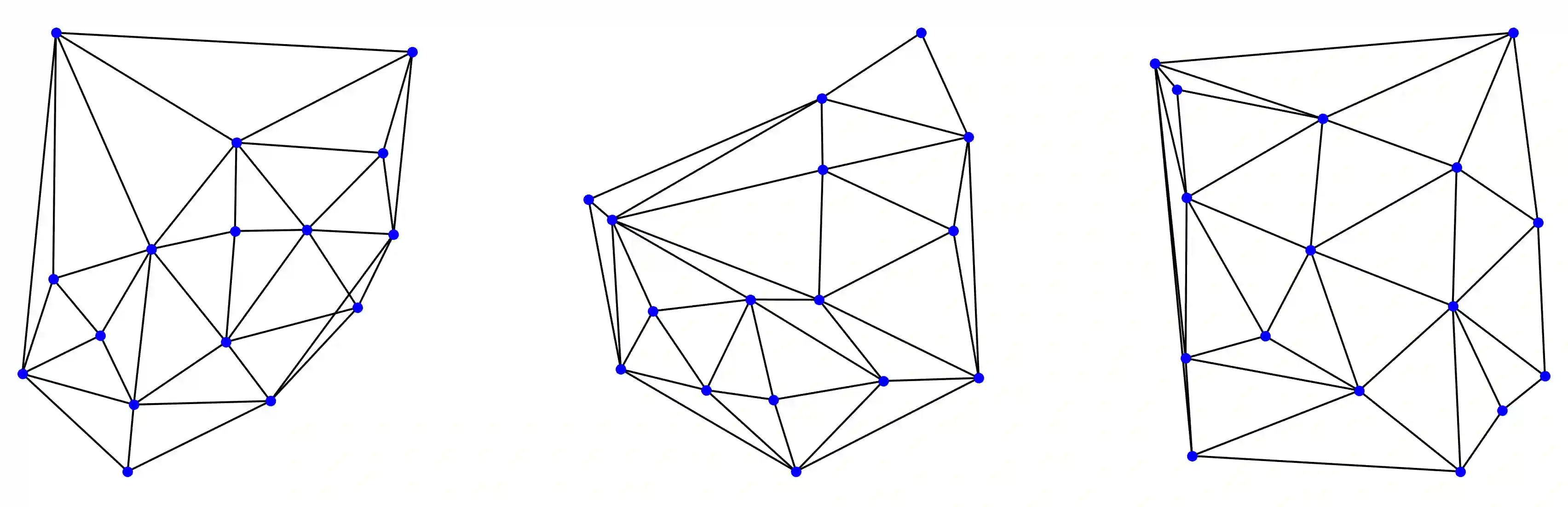
We introduce an extension to the CLRS algorithmic learning benchmark, prioritizing scalability and the utilization of sparse representations. Many algorithms in CLRS require global memory or information exchange, mirrored in its execution model, which constructs fully connected (not sparse) graphs based on the underlying problem. Despite CLRS's aim of assessing how effectively learned algorithms can generalize to larger instances, the existing execution model becomes a significant constraint due to its demanding memory requirements and runtime (hard to scale). However, many important algorithms do not demand a fully connected graph; these algorithms, primarily distributed in nature, align closely with the message-passing paradigm employed by Graph Neural Networks. Hence, we propose SALSA-CLRS, an extension of the current CLRS benchmark specifically with scalability and sparseness in mind. Our approach includes adapted algorithms from the original CLRS benchmark and introduces new problems from distributed and randomized algorithms. Moreover, we perform a thorough empirical evaluation of our benchmark. Code is publicly available at https://github.com/jkminder/SALSA-CLRS.
翻译:我们提出对CLRS算法学习基准的扩展,优先考虑可扩展性与稀疏表示的利用。CLRS中的许多算法需要全局内存或信息交换,这在其执行模型中得以体现——该模型基于底层问题构建全连接(而非稀疏)图。尽管CLRS旨在评估学习算法对不同规模实例的泛化能力,但现有执行模型因内存需求和运行时间要求过高(难以扩展)而成为显著限制。然而,许多重要算法并不需要全连接图;这些以分布式为主的算法与图神经网络采用的“消息传递”范式高度契合。为此,我们提出SALSA-CLRS——一个专为可扩展性与稀疏性设计的CLRS基准扩展。我们的方案包含对原始CLRS基准中算法的适配,并引入分布式与随机化算法领域的新问题。此外,我们对该基准进行了全面的实证评估。代码已公开于https://github.com/jkminder/SALSA-CLRS。