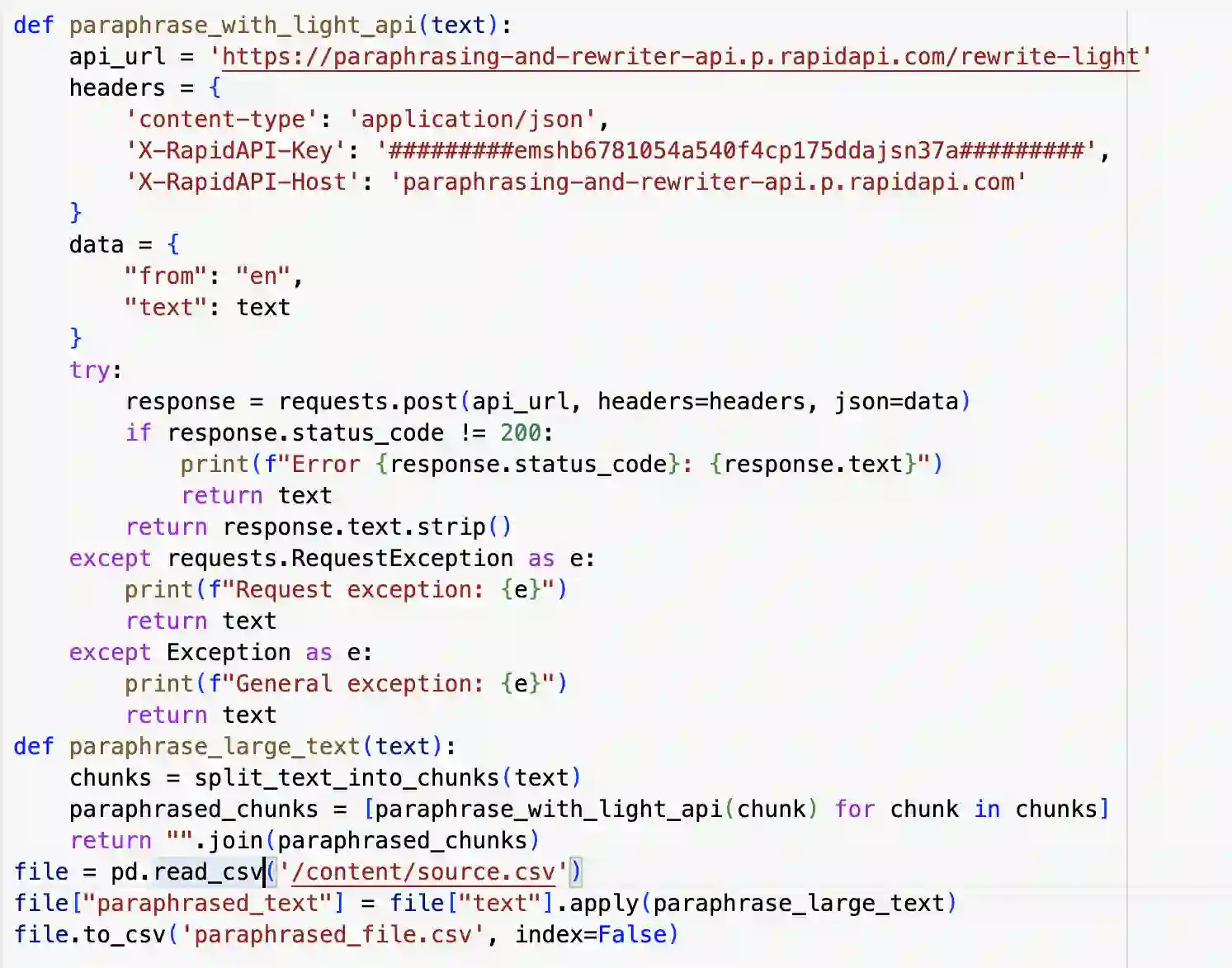
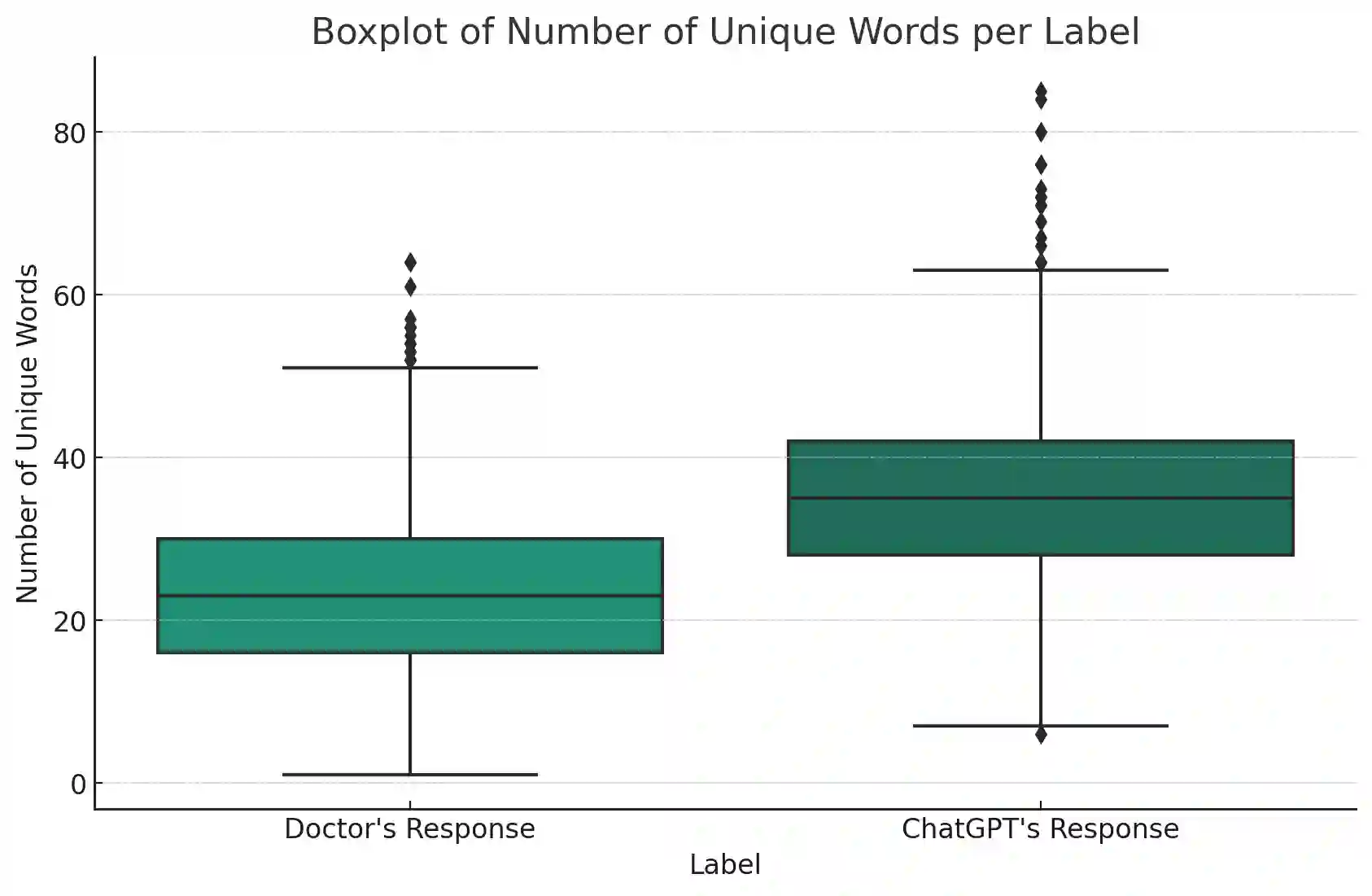
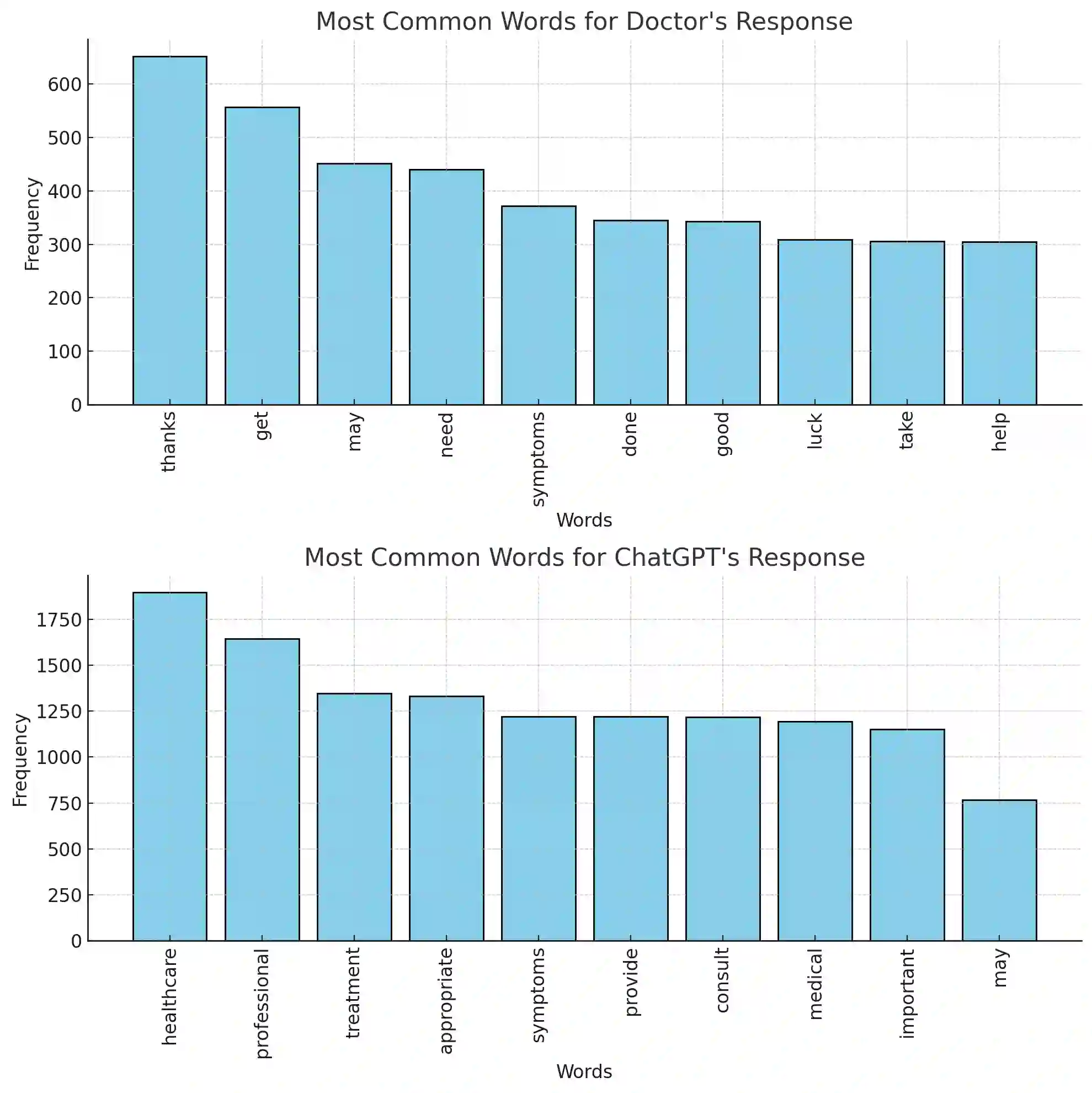
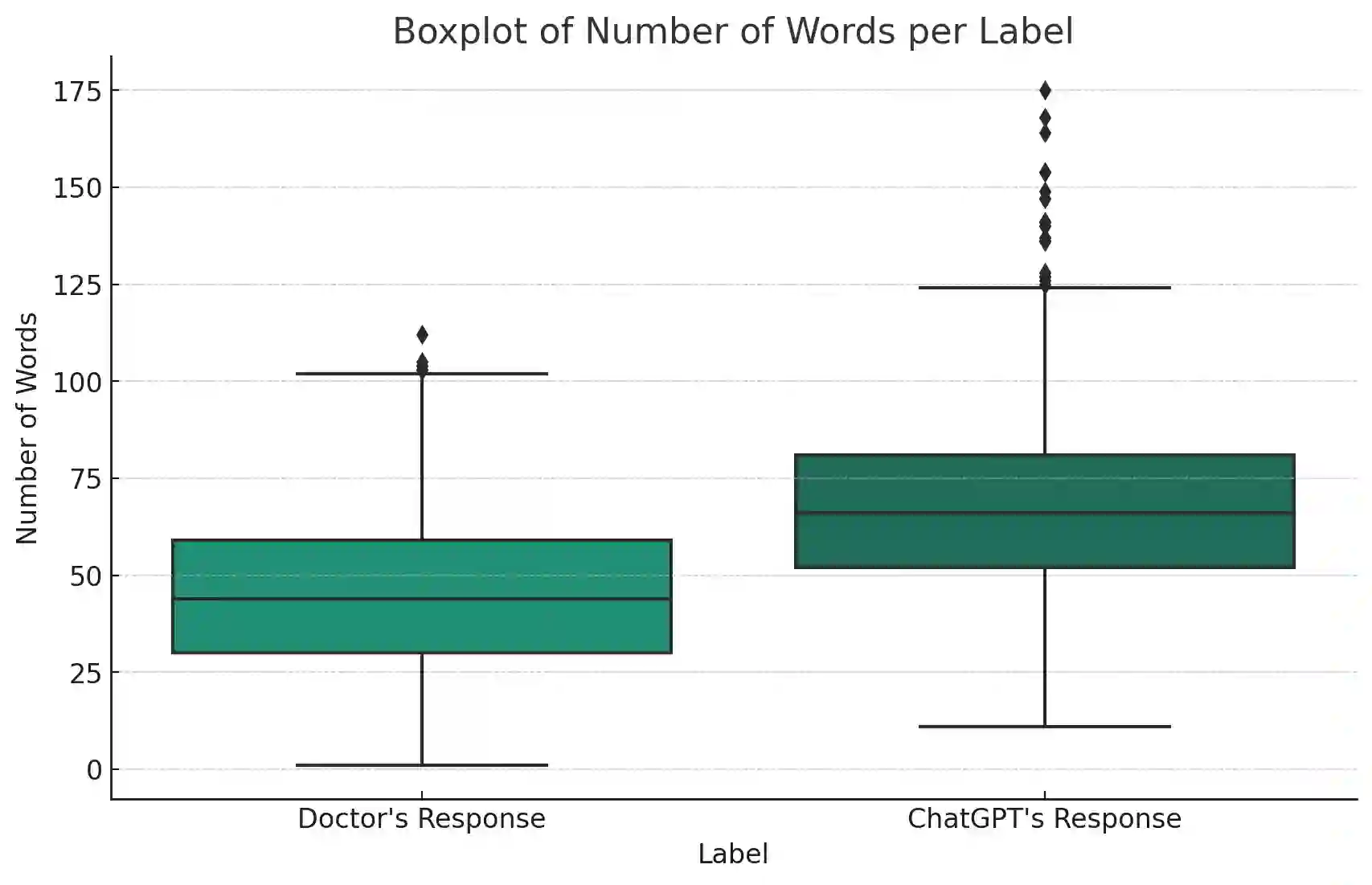
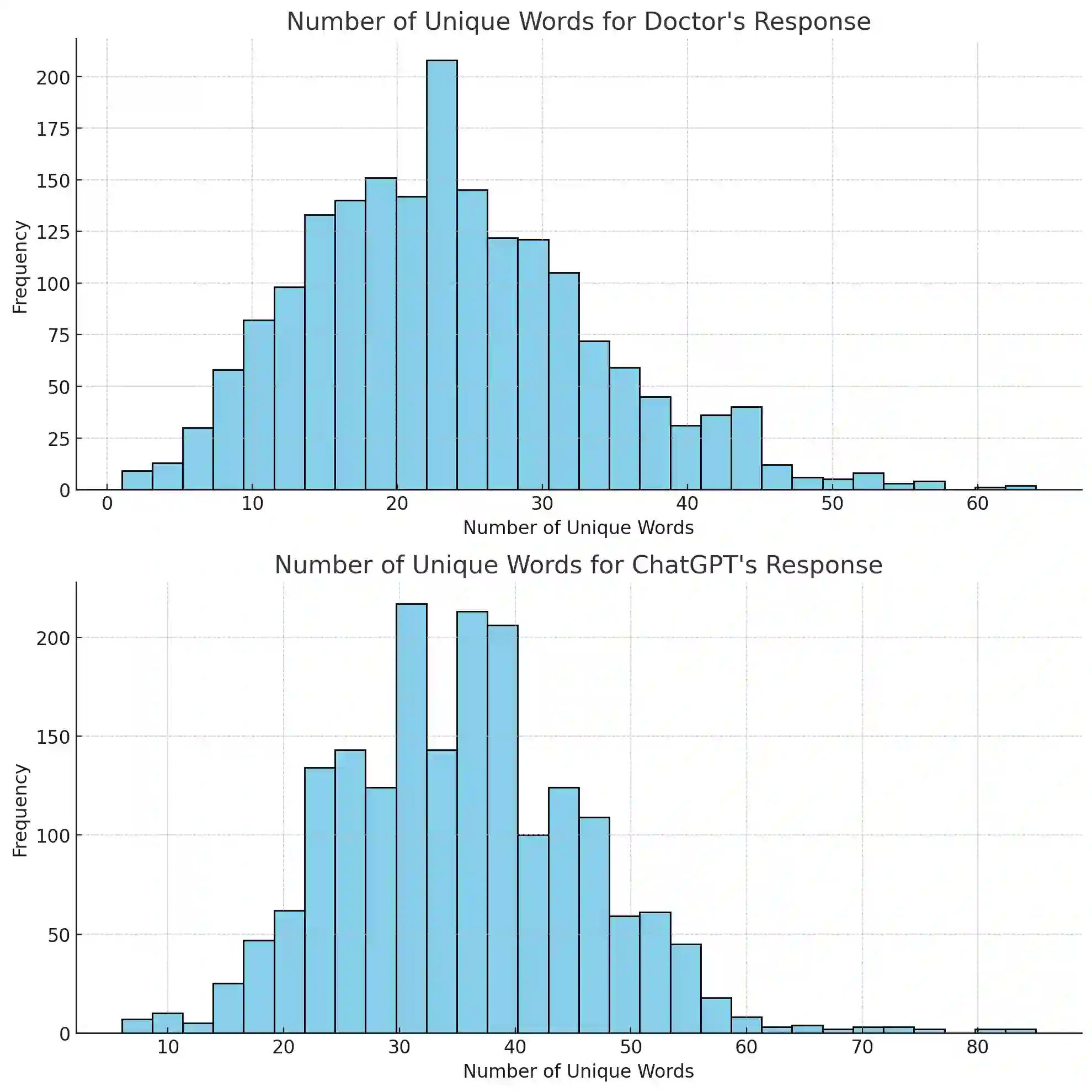
Zero-shot classification enables text to be classified into classes not seen during training. In this research, we investigate the effectiveness of pre-trained language models to accurately classify responses from Doctors and AI in health consultations through zero-shot learning. Our study aims to determine whether these models can effectively detect if a text originates from human or AI models without specific corpus training. We collect responses from doctors to patient inquiries about their health and pose the same question/response to AI models. While zero-shot language models show a good understanding of language in general, they have limitations in classifying doctor and AI responses in healthcare consultations. This research lays the groundwork for further research into this field of medical text classification, informing the development of more effective approaches to accurately classify doctor-generated and AI-generated text in health consultations.
翻译:零样本分类能够对训练阶段未见过的类别文本进行分类。本研究探究预训练语言模型通过零样本学习准确区分医疗咨询中医生与AI回答的有效性。我们旨在确定这些模型在无需特定语料库训练的情况下,能否有效检测文本源自人类还是AI模型。我们收集了医生对患者健康问题的回复,并将相同问题与回答输入AI模型。尽管零样本语言模型通常展现出良好的语言理解能力,但在医疗咨询中区分医生与AI回答方面仍存在局限性。本研究为该医学文本分类领域奠定了研究基础,有助于开发更有效的方法来准确分类医疗咨询中医生生成与AI生成的文本。