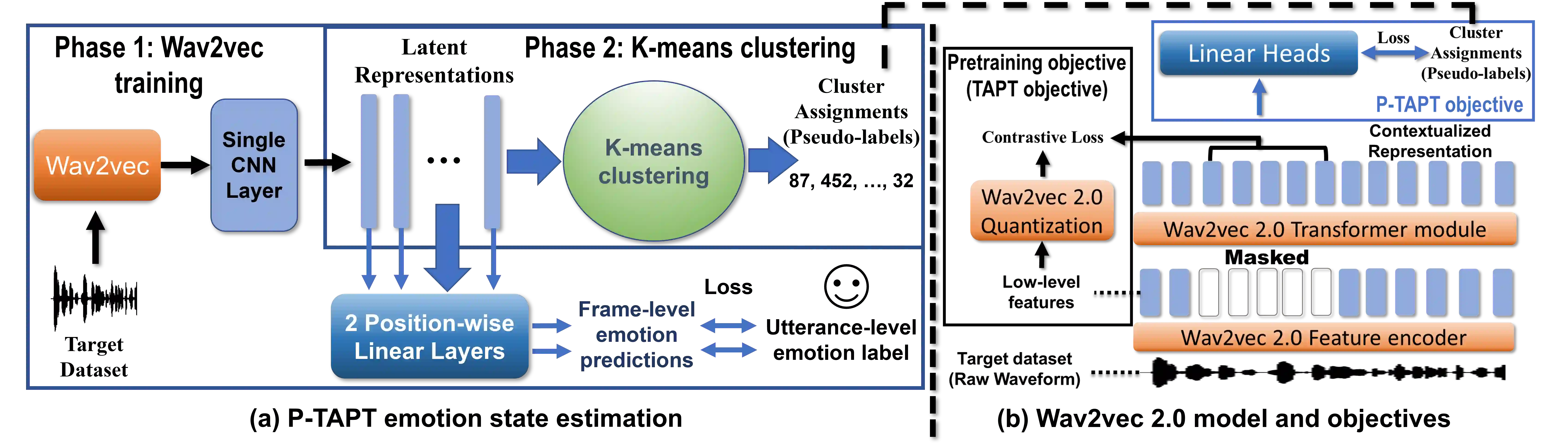
While Wav2Vec 2.0 has been proposed for speech recognition (ASR), it can also be used for speech emotion recognition (SER); its performance can be significantly improved using different fine-tuning strategies. Two baseline methods, vanilla fine-tuning (V-FT) and task adaptive pretraining (TAPT) are first presented. We show that V-FT is able to outperform state-of-the-art models on the IEMOCAP dataset. TAPT, an existing NLP fine-tuning strategy, further improves the performance on SER. We also introduce a novel fine-tuning method termed P-TAPT, which modifies the TAPT objective to learn contextualized emotion representations. Experiments show that P-TAPT performs better than TAPT, especially under low-resource settings. Compared to prior works in this literature, our top-line system achieved a 7.4\% absolute improvement in unweighted accuracy (UA) over the state-of-the-art performance on IEMOCAP. Our code is publicly available.
翻译:尽管Wav2Vec 2.0最初是为语音识别任务提出的,但亦可应用于语音情感识别领域;通过采用不同的微调策略,其性能可得到显著提升。本文首先介绍两种基线方法:原始微调与任务自适应预训练。实验表明,原始微调方法在IEMOCAP数据集上能够超越现有最优模型。任务自适应预训练作为一种自然语言处理领域已有的微调策略,能进一步提升语音情感识别的性能。我们提出了一种创新的微调方法P-TAPT,该方法通过修改任务自适应预训练的目标函数来学习情境化的情感表征。实验结果显示,P-TAPT方法的表现优于任务自适应预训练,尤其是在低资源场景下。与既有文献工作相比,我们的最优系统在IEMOCAP数据集上的非加权准确率相较于当前最优性能获得了7.4%的绝对提升。相关代码已开源供研究者使用。