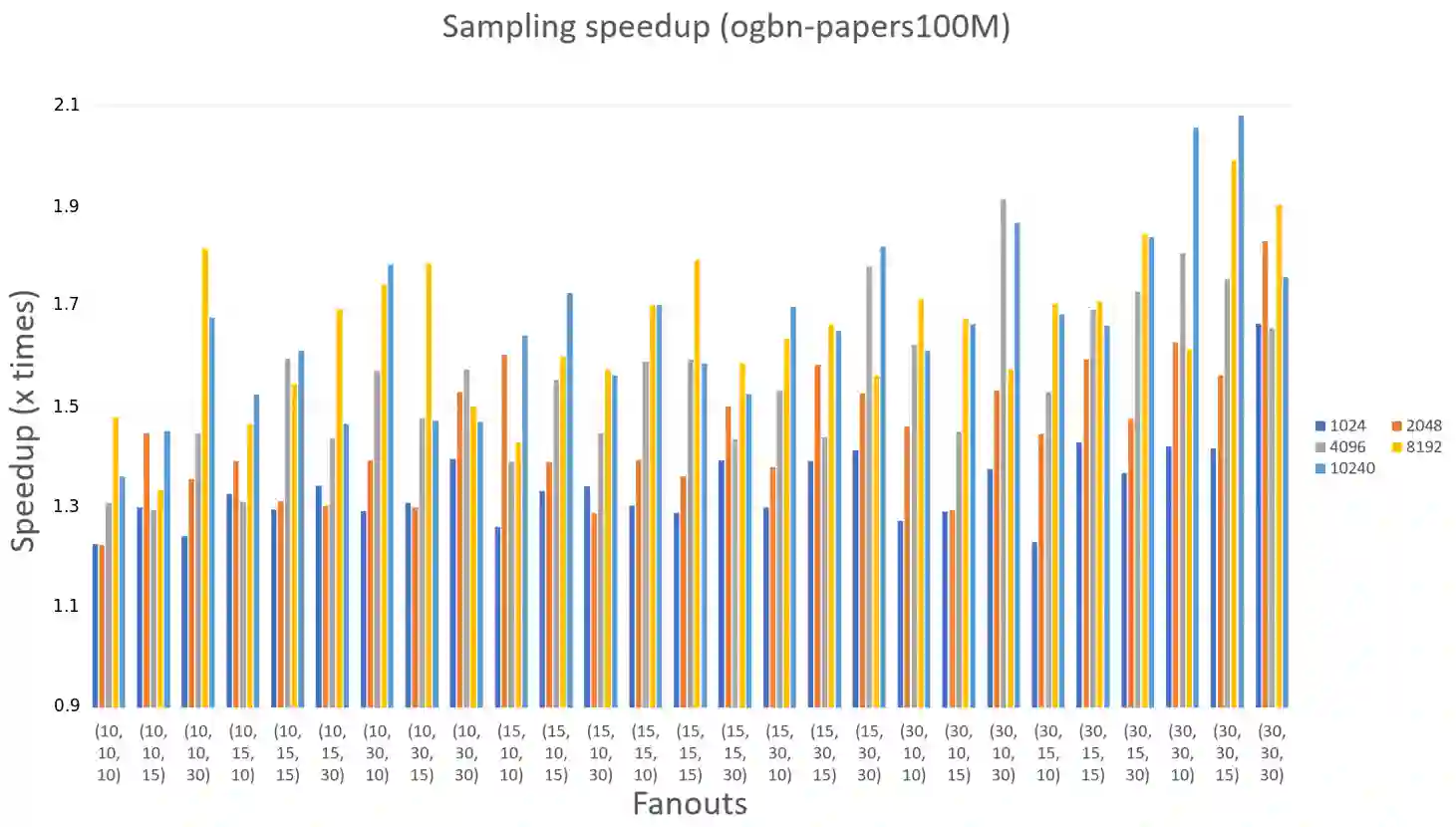
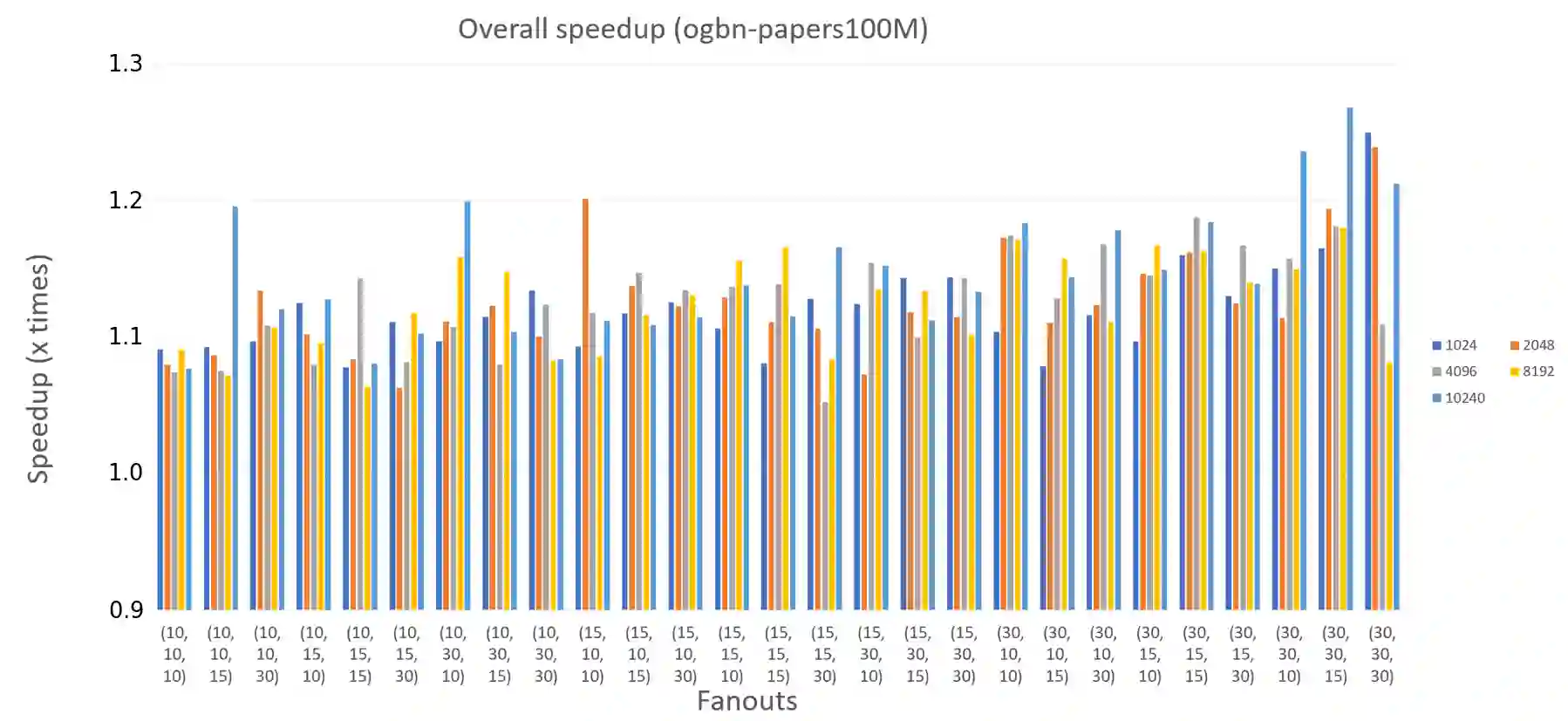
Training Graph Neural Networks(GNNs) on a large monolithic graph presents unique challenges as the graph cannot fit within a single machine and it cannot be decomposed into smaller disconnected components. Distributed sampling-based training distributes the graph across multiple machines and trains the GNN on small parts of the graph that are randomly sampled every training iteration. We show that in a distributed environment, the sampling overhead is a significant component of the training time for large-scale graphs. We propose FastSample which is composed of two synergistic techniques that greatly reduce the distributed sampling time: 1)a new graph partitioning method that eliminates most of the communication rounds in distributed sampling , 2)a novel highly optimized sampling kernel that reduces memory movement during sampling. We test FastSample on large-scale graph benchmarks and show that FastSample speeds up distributed sampling-based GNN training by up to 2x with no loss in accuracy.
翻译:在大型单体图上训练图神经网络(GNN)面临着独特挑战,因为该图既无法装载到单台机器中,也无法分解为更小的独立连通组件。基于分布式采样的训练方法将图分布至多台机器,并在每个训练迭代中随机采样的图子集上训练GNN。我们证明在分布式环境中,对于大规模图而言,采样开销是训练时间的重要组成部分。为此提出FastSample,它包含两种协同技术以大幅降低分布式采样时间:1)一种新型图分区方法,可消除分布式采样中的大部分通信轮次;2)一种创新的高度优化采样核,可减少采样过程中的内存移动。我们在大规模图基准测试上检验FastSample,结果表明FastSample在保持精度不变的前提下,可将基于分布式采样的GNN训练速度提升高达2倍。