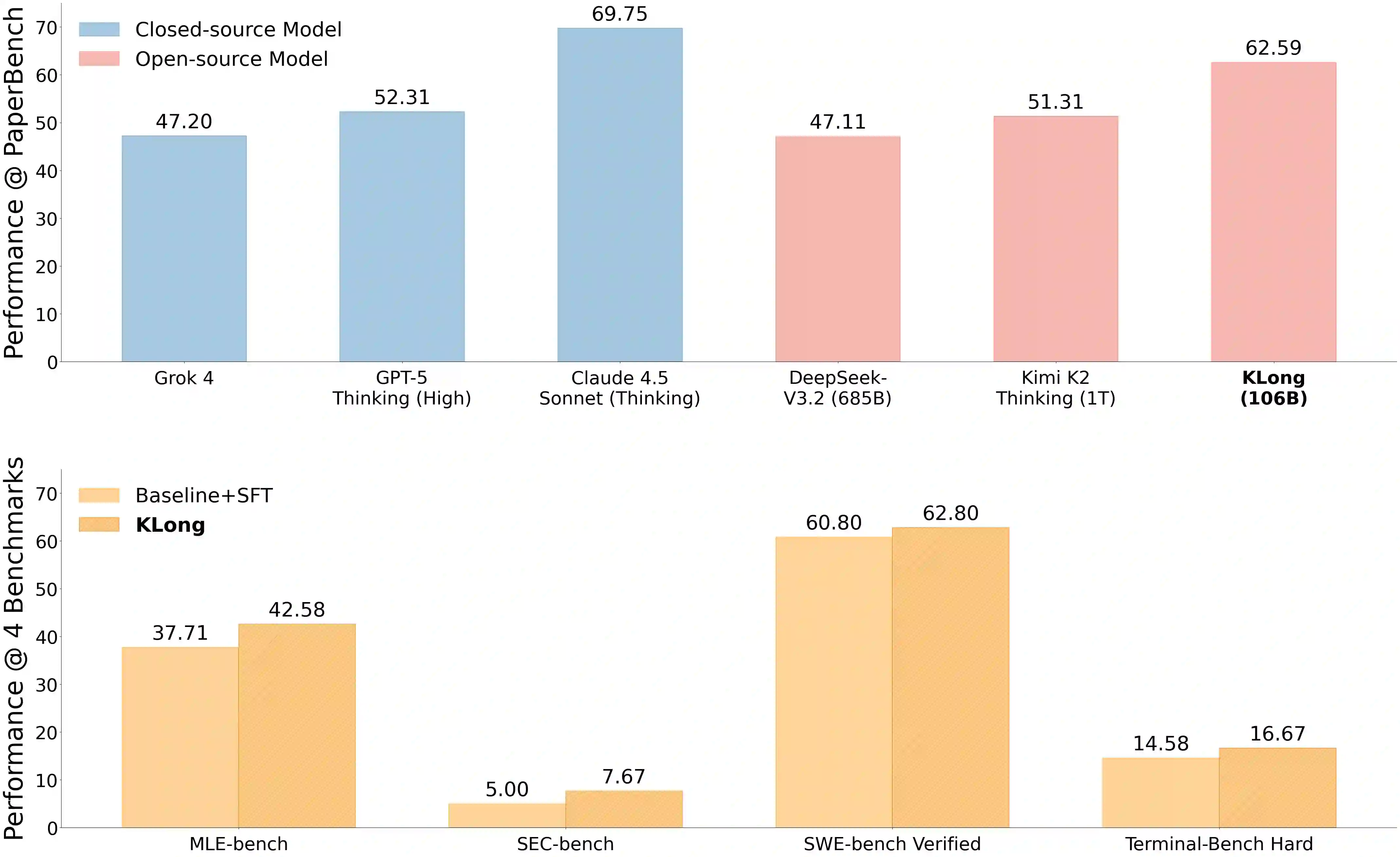
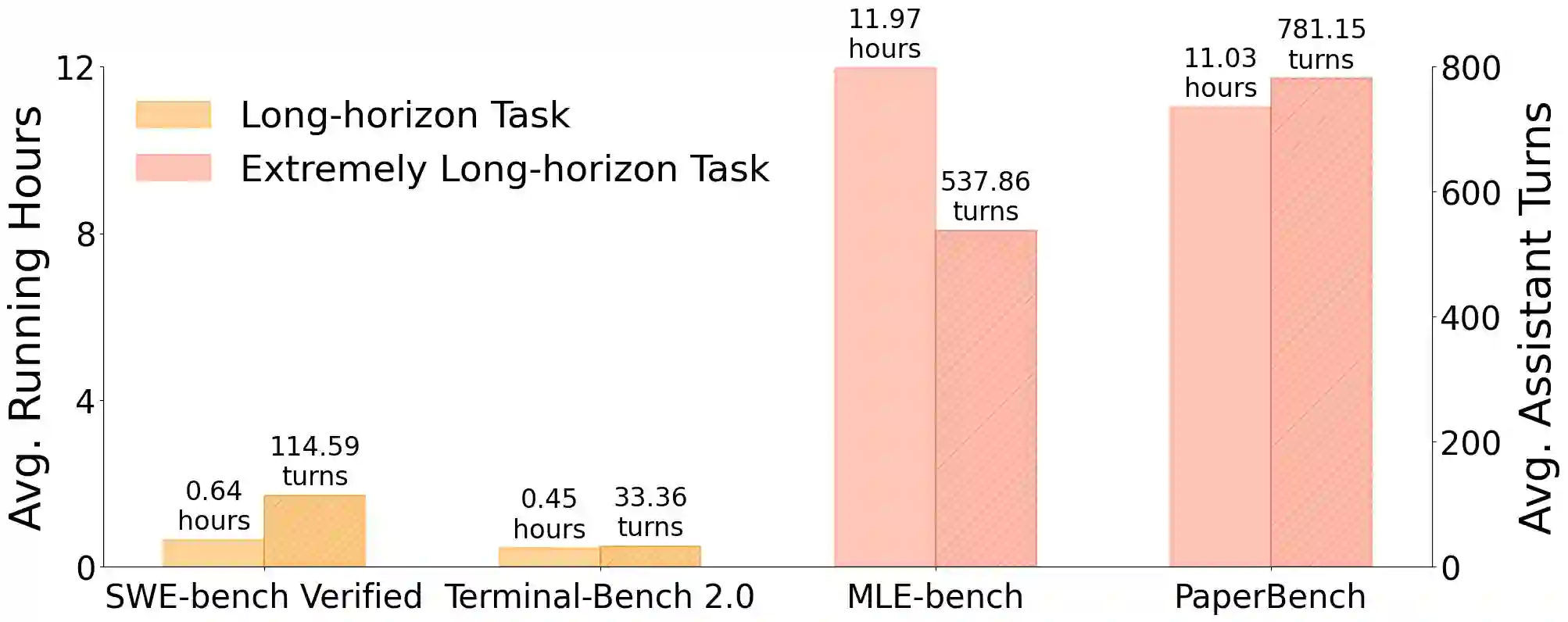
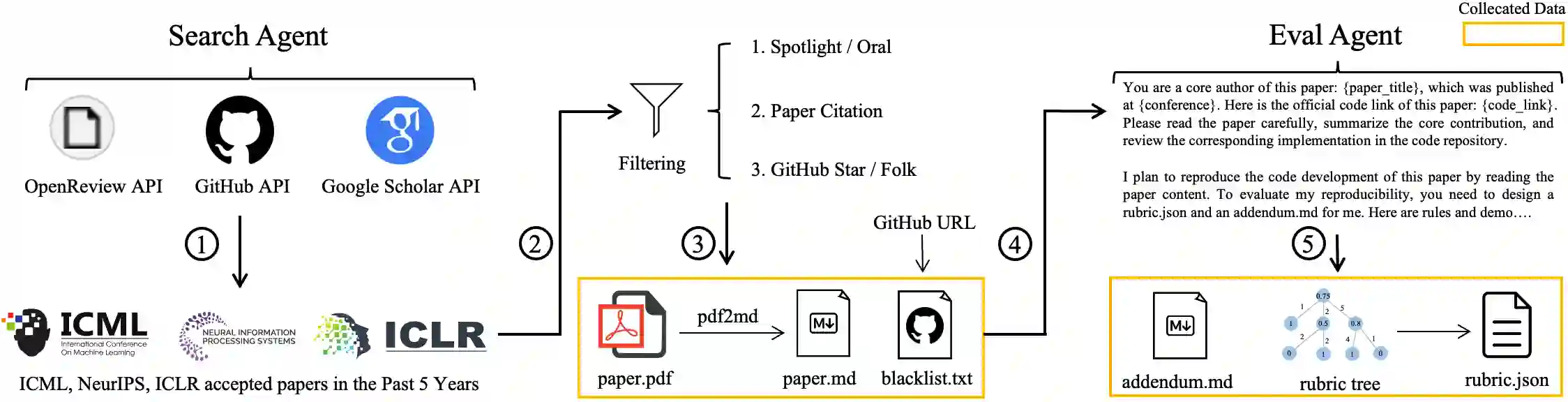
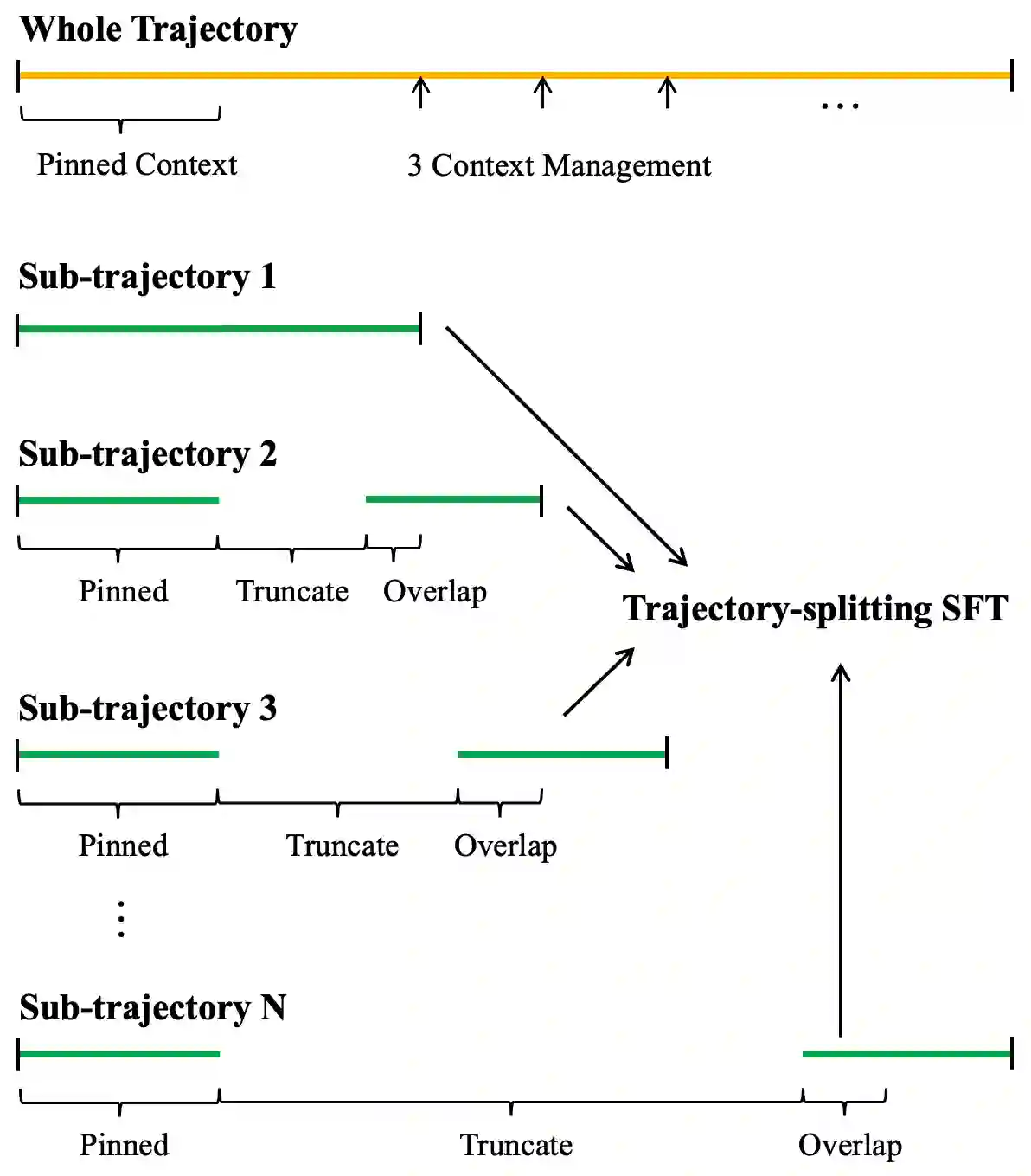
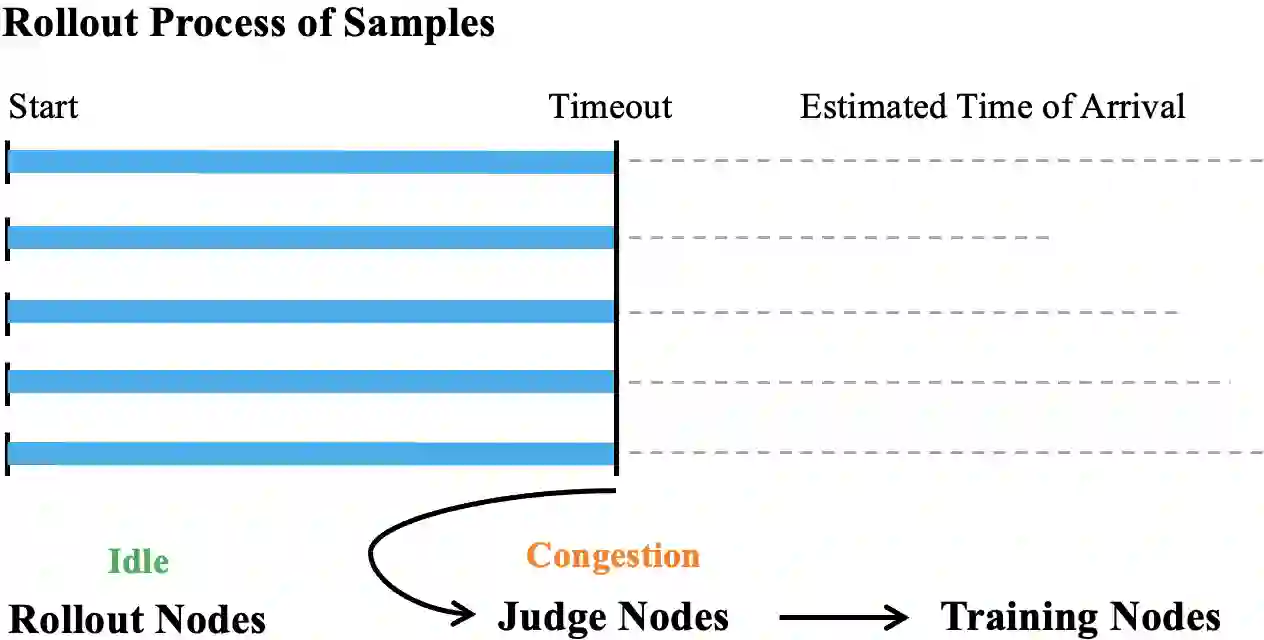
This paper introduces KLong, an open-source LLM agent trained to solve extremely long-horizon tasks. The principle is to first cold-start the model via trajectory-splitting SFT, then scale it via progressive RL training. Specifically, we first activate basic agentic abilities of a base model with a comprehensive SFT recipe. Then, we introduce Research-Factory, an automated pipeline that generates high-quality training data by collecting research papers and constructing evaluation rubrics. Using this pipeline, we build thousands of long-horizon trajectories distilled from Claude 4.5 Sonnet (Thinking). To train with these extremely long trajectories, we propose a new trajectory-splitting SFT, which preserves early context, progressively truncates later context, and maintains overlap between sub-trajectories. In addition, to further improve long-horizon task-solving capability, we propose a novel progressive RL, which schedules training into multiple stages with progressively extended timeouts. Experiments demonstrate the superiority and generalization of KLong, as shown in Figure 1. Notably, our proposed KLong (106B) surpasses Kimi K2 Thinking (1T) by 11.28% on PaperBench, and the performance improvement generalizes to other coding benchmarks like SWE-bench Verified and MLE-bench.
翻译:本文介绍KLong,一种用于解决超长程任务的开源LLM智能体。其核心原理是首先通过轨迹分割监督微调实现冷启动,随后通过渐进式强化学习进行规模化训练。具体而言,我们首先通过综合性的监督微调方案激活基础模型的基础智能体能力。随后,我们引入Research-Factory——一个通过收集研究论文并构建评估准则来自动生成高质量训练数据的流水线。利用该流水线,我们从Claude 4.5 Sonnet(思考版)中蒸馏构建了数千条长程轨迹。为处理这些超长轨迹的训练,我们提出了一种新的轨迹分割监督微调方法,该方法保留早期上下文,逐步截断后续上下文,并保持子轨迹间的重叠部分。此外,为进一步提升长程任务解决能力,我们提出了一种新颖的渐进式强化学习方法,该方法将训练规划为多个阶段,并逐步延长超时阈值。实验证明了KLong的优越性与泛化能力,如图1所示。值得注意的是,我们提出的KLong(106B)在PaperBench上以11.28%的优势超越Kimi K2 Thinking(1T),且性能提升可泛化至SWE-bench Verified和MLE-bench等其他代码评测基准。