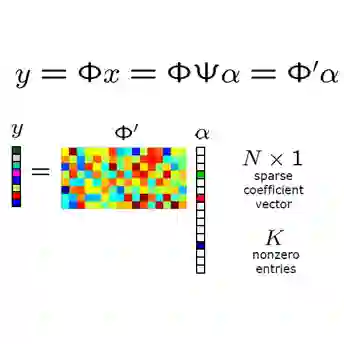
We introduce a mathematical framework for the linear representation hypothesis (LRH), which asserts that intermediate layers of language models store features linearly. We separate the hypothesis into two claims: linear representation (features are linearly embedded in neuron activations) and linear accessibility (features can be linearly decoded). We then ask: How many neurons $d$ suffice to both linearly represent and linearly access $m$ features? Classical results in compressed sensing imply that for $k$-sparse inputs, $d = O(k\log (m/k))$ suffices if we allow non-linear decoding algorithms (Candes and Tao, 2006; Candes et al., 2006; Donoho, 2006). However, the additional requirement of linear decoding takes the problem out of the classical compressed sensing, into linear compressed sensing. Our main theoretical result establishes nearly-matching upper and lower bounds for linear compressed sensing. We prove that $d = Ω_ε(\frac{k^2}{\log k}\log (m/k))$ is required while $d = O_ε(k^2\log m)$ suffices. The lower bound establishes a quantitative gap between classical and linear compressed setting, illustrating how linear accessibility is a meaningfully stronger hypothesis than linear representation alone. The upper bound confirms that neurons can store an exponential number of features under the LRH, giving theoretical evidence for the "superposition hypothesis" (Elhage et al., 2022). The upper bound proof uses standard random constructions of matrices with approximately orthogonal columns. The lower bound proof uses rank bounds for near-identity matrices (Alon, 2003) together with Turán's theorem (bounding the number of edges in clique-free graphs). We also show how our results do and do not constrain the geometry of feature representations and extend our results to allow decoders with an activation function and bias.
翻译:我们提出了线性表示假设(LRH)的数学框架,该假设断言语言模型的中间层以线性方式存储特征。我们将该假设分解为两个主张:线性表示(特征线性嵌入于神经元激活中)与线性可访问性(特征可通过线性方式解码)。随后我们探讨:需要多少神经元 $d$ 才能同时实现 $m$ 个特征的线性表示与线性访问?压缩感知的经典结果表明,对于 $k$-稀疏输入,若允许非线性解码算法,则 $d = O(k\log (m/k))$ 已足够(Candes and Tao, 2006; Candes et al., 2006; Donoho, 2006)。然而,线性解码的附加要求使该问题脱离了经典压缩感知范畴,进入线性压缩感知领域。我们的主要理论结果建立了线性压缩感知近乎匹配的上下界。我们证明需要 $d = Ω_ε(\frac{k^2}{\log k}\log (m/k))$,而 $d = O_ε(k^2\log m)$ 即足够。下界确立了经典压缩与线性压缩设定间的量化差距,说明线性可访问性是比单纯线性表示更强意义的假设。上界证实了在LRH下神经元可存储指数级数量的特征,为"叠加假设"(Elhage et al., 2022)提供了理论依据。上界证明采用了具有近似正交列的标准随机矩阵构造法。下界证明结合了近单位矩阵的秩界(Alon, 2003)与图兰定理(用于限定无团图中的边数)。我们还展示了研究结果如何约束特征表示的几何结构及其局限性,并将结论扩展至允许解码器包含激活函数与偏置项的情形。