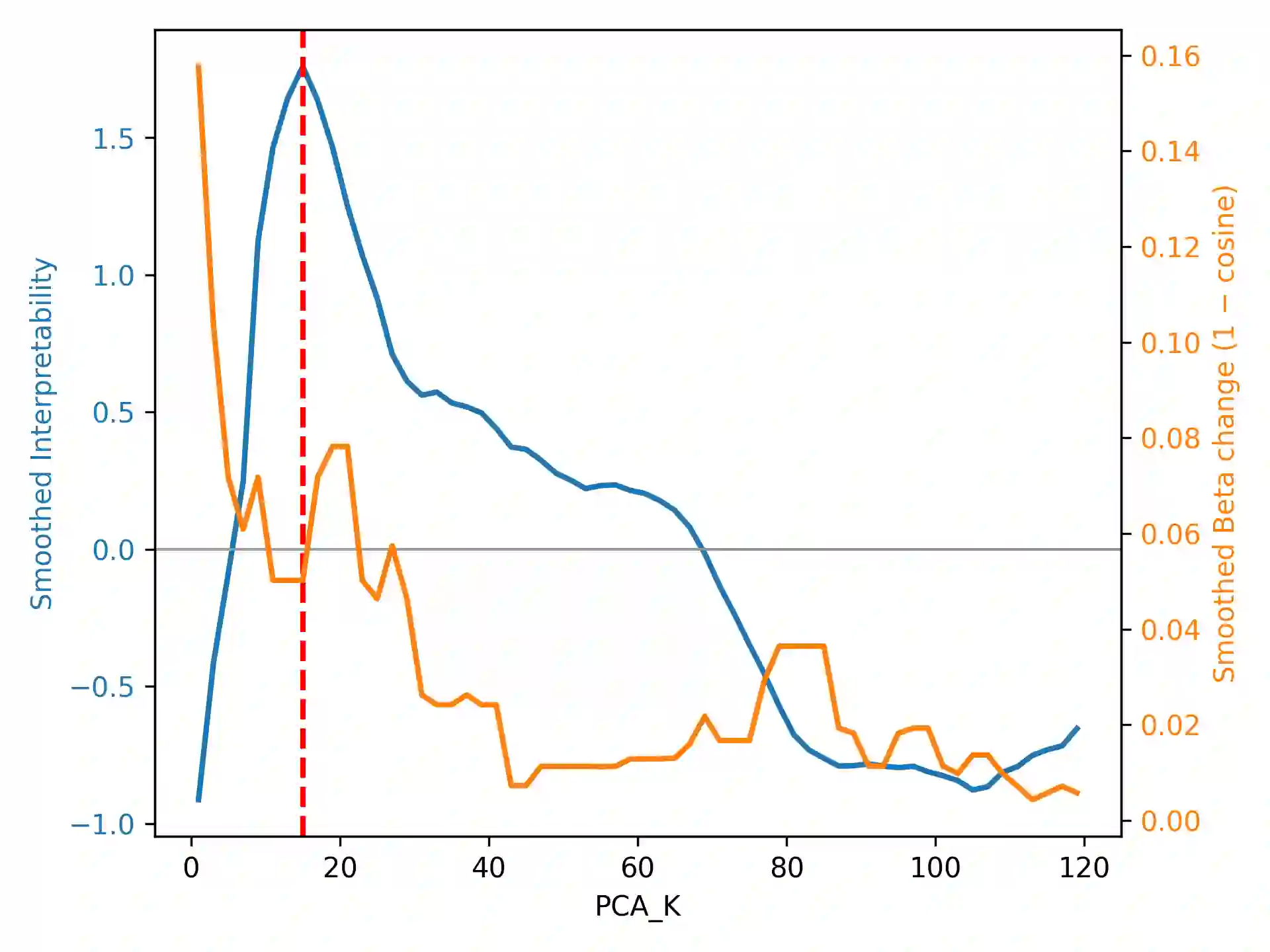
Supervised Semantic Differential (SSD) is a mixed quantitative-interpretive method that models how text meaning varies with continuous individual-difference variables by estimating a semantic gradient in an embedding space and interpreting its poles through clustering and text retrieval. SSD applies PCA before regression, but currently no systematic method exists for choosing the number of retained components, introducing avoidable researcher degrees of freedom in the analysis pipeline. We propose a PCA sweep procedure that treats dimensionality selection as a joint criterion over representation capacity, gradient interpretability, and stability across nearby values of K. We illustrate the method on a corpus of short posts about artificial intelligence written by Prolific participants who also completed Admiration and Rivalry narcissism scales. The sweep yields a stable, interpretable Admiration-related gradient contrasting optimistic, collaborative framings of AI with distrustful and derisive discourse, while no robust alignment emerges for Rivalry. We also show that a counterfactual using a high-PCA dimension solution heuristic produces diffuse, weakly structured clusters instead, reinforcing the value of the sweep-based choice of K. The case study shows how the PCA sweep constrains researcher degrees of freedom while preserving SSD's interpretive aims, supporting transparent and psychologically meaningful analyses of connotative meaning.
翻译:监督语义差异(SSD)是一种定量与解释相结合的混合方法,它通过在嵌入空间中估计语义梯度并借助聚类与文本检索技术解释其两极,从而建模文本意义如何随连续个体差异变量变化。SSD在回归分析前应用主成分分析(PCA),但目前尚无系统方法确定保留的主成分数量,这导致分析流程中引入了本可避免的研究者自由度。我们提出一种PCA扫描程序,将维度选择视为表征能力、梯度可解释性及相邻K值间稳定性的联合判据。我们在一个由Prolific平台参与者撰写的关于人工智能的短帖语料库上演示该方法,这些参与者同时完成了钦佩型与对抗型自恋量表。扫描过程产生了一个稳定且可解释的与钦佩维度相关的语义梯度,其两极分别对应乐观协作的AI论述框架与充满不信任及嘲弄的话语模式,而对抗型维度则未呈现稳健的语义对齐。我们还证明,若采用高PCA维度的解决方案启发式进行反事实分析,则会产生分散且结构松散的聚类结果,这进一步印证了基于扫描选择K值的价值。本案例研究表明,PCA扫描方法能在保持SSD解释目标的同时有效约束研究者自由度,从而支持对内涵意义进行透明且具有心理学意义的分析。