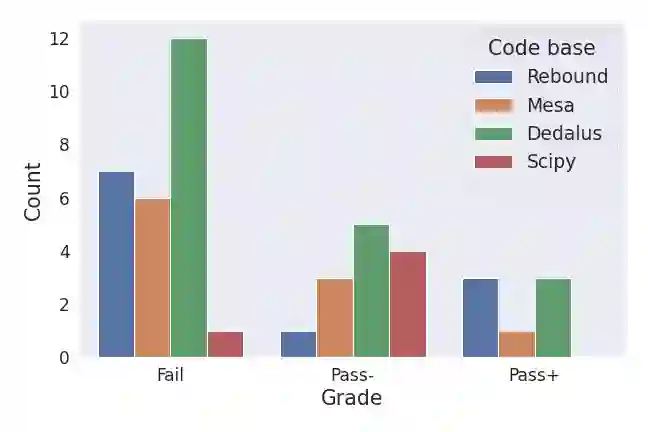
[Abridged abstract] Large Language Models (LLMs) can solve some undergraduate-level to graduate-level physics textbook problems and are proficient at coding. Combining these two capabilities could one day enable AI systems to simulate and predict the physical world. We present an evaluation of state-of-the-art (SOTA) LLMs on PhD-level to research-level computational physics problems. We condition LLM generation on the use of well-documented and widely-used packages to elicit coding capabilities in the physics and astrophysics domains. We contribute $\sim 50$ original and challenging problems in celestial mechanics (with REBOUND), stellar physics (with MESA), 1D fluid dynamics (with Dedalus) and non-linear dynamics (with SciPy). Since our problems do not admit unique solutions, we evaluate LLM performance on several soft metrics: counts of lines that contain different types of errors (coding, physics, necessity and sufficiency) as well as a more "educational" Pass-Fail metric focused on capturing the salient physical ingredients of the problem at hand. As expected, today's SOTA LLM (GPT4) zero-shot fails most of our problems, although about 40\% of the solutions could plausibly get a passing grade. About $70-90 \%$ of the code lines produced are necessary, sufficient and correct (coding \& physics). Physics and coding errors are the most common, with some unnecessary or insufficient lines. We observe significant variations across problem class and difficulty. We identify several failure modes of GPT4 in the computational physics domain. Our reconnaissance work provides a snapshot of current computational capabilities in classical physics and points to obvious improvement targets if AI systems are ever to reach a basic level of autonomy in physics simulation capabilities.
翻译:大型语言模型(LLMs)能够解决部分本科至研究生级别的物理教科书问题,并擅长编程。若将这两项能力结合,未来或可令AI系统模拟并预测物理世界。本文评估了最先进(SOTA)LLM在博士级至研究级计算物理问题上的表现。我们引导LLM在物理与天体物理领域使用文档完善且广泛应用的代码包,以激发其编程能力。我们贡献了约50个原创且具有挑战性的问题,涵盖天体力学(使用REBOUND)、恒星物理(使用MESA)、一维流体动力学(使用Dedalus)及非线性动力学(使用SciPy)。由于这些问题没有唯一解,我们通过多个软性指标评估LLM性能:包含不同类型错误(编程、物理、必要性与充分性)的代码行数,以及更“教育导向”的“通过/不通过”指标,侧重捕捉问题核心物理要素。正如预期,当前SOTA LLM(GPT4)在零样本条件下未能解决大部分问题,但约40%的解决方案可能勉强及格。约70-90%的代码行具有必要性、充分性与正确性(编程与物理)。编程和物理错误最为常见,同时存在少量不必要或不充分的代码行。我们观察到不同问题类别与难度之间存在显著差异,并识别了GPT4在计算物理领域的若干失败模式。本探索性工作呈现了经典物理学当前计算能力的快照,并为AI系统未来需达成的物理模拟基本自主水平指明了明确的改进方向。