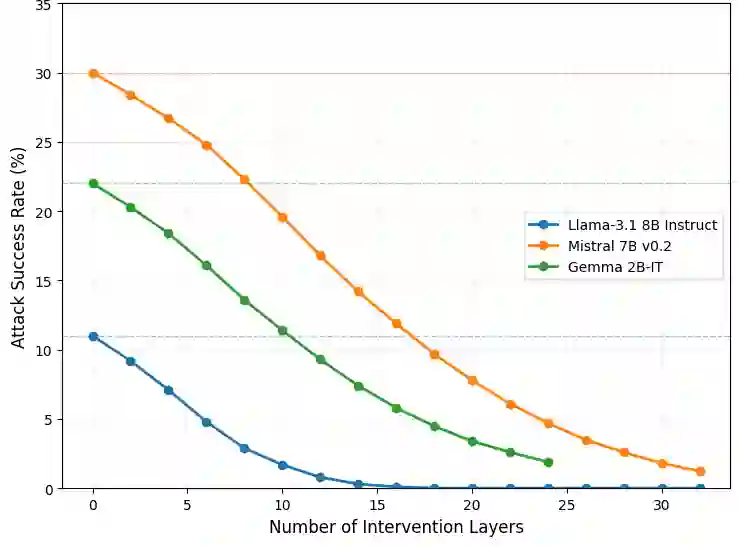
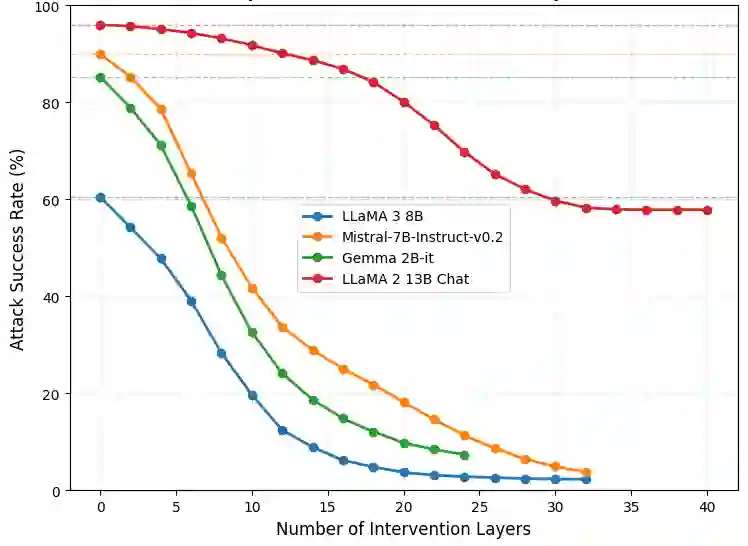
With the increasing adoption of Large Language Models (LLMs), more customization is needed to ensure privacy-preserving and safe generation. We address this objective from two critical aspects: unlearning of sensitive information and robustness to jail-breaking attacks. We investigate various constrained optimization formulations that address both aspects in a \emph{unified manner}, by finding the smallest possible interventions on LLM weights that either make a given vocabulary set unreachable or embed the LLM with robustness to tailored attacks by shifting part of the weights to a \emph{safer} region. Beyond unifying two key properties, this approach contrasts with previous work in that it doesn't require an oracle classifier that is typically not available or represents a computational overhead. Surprisingly, we find that the simplest point-wise constraint-based intervention we propose leads to better performance than max-min interventions, while having a lower computational cost. Comparison against state-of-the-art defense methods demonstrates superior performance of the proposed approach.
翻译:随着大型语言模型(LLMs)的日益普及,需要更多定制化方案来确保生成内容的隐私保护与安全性。我们从两个关键维度实现这一目标:敏感信息的遗忘与对越狱攻击的鲁棒性。我们研究了多种约束优化建模方法,通过寻找对LLM权重的最小干预——或使给定词汇集不可达,或将部分权重迁移至更安全区域以增强模型对定制化攻击的鲁棒性——以统一方式同时解决这两个问题。除了统一这两个关键特性外,本方法与先前研究的区别在于无需依赖通常不可用或带来计算开销的预言机分类器。令人惊讶的是,我们发现所提出的基于逐点约束的干预方法,在计算成本更低的同时,比最大最小干预获得了更优的性能。与现有先进防御方法的对比实验证明了所提方法的卓越性能。