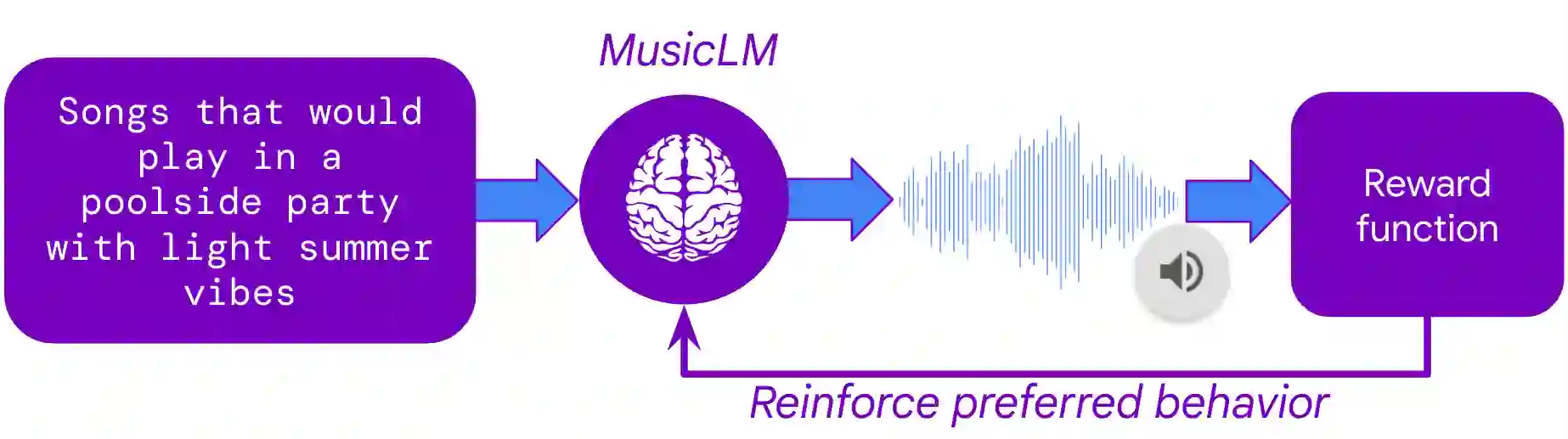
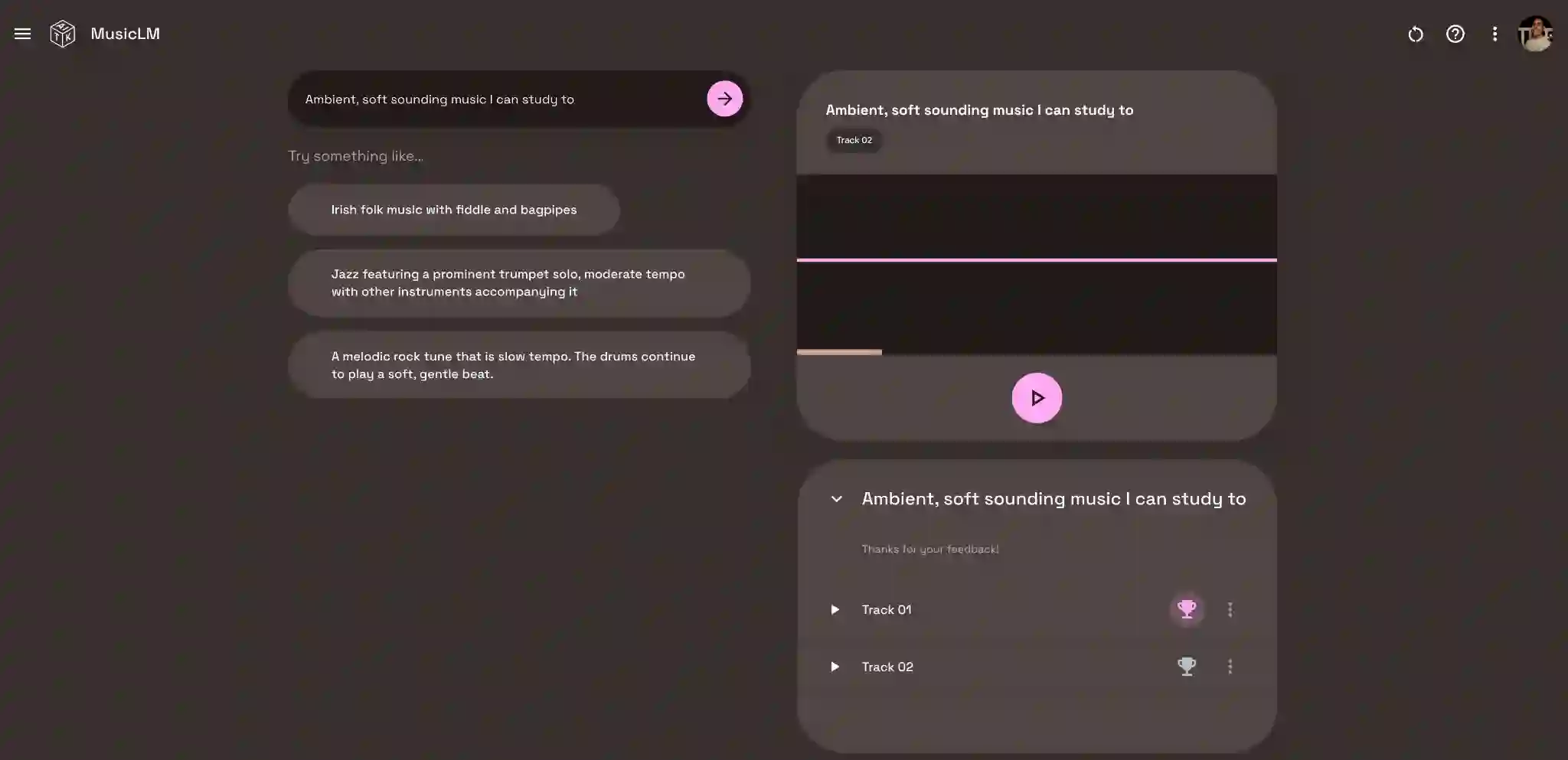
We propose MusicRL, the first music generation system finetuned from human feedback. Appreciation of text-to-music models is particularly subjective since the concept of musicality as well as the specific intention behind a caption are user-dependent (e.g. a caption such as "upbeat work-out music" can map to a retro guitar solo or a techno pop beat). Not only this makes supervised training of such models challenging, but it also calls for integrating continuous human feedback in their post-deployment finetuning. MusicRL is a pretrained autoregressive MusicLM (Agostinelli et al., 2023) model of discrete audio tokens finetuned with reinforcement learning to maximise sequence-level rewards. We design reward functions related specifically to text-adherence and audio quality with the help from selected raters, and use those to finetune MusicLM into MusicRL-R. We deploy MusicLM to users and collect a substantial dataset comprising 300,000 pairwise preferences. Using Reinforcement Learning from Human Feedback (RLHF), we train MusicRL-U, the first text-to-music model that incorporates human feedback at scale. Human evaluations show that both MusicRL-R and MusicRL-U are preferred to the baseline. Ultimately, MusicRL-RU combines the two approaches and results in the best model according to human raters. Ablation studies shed light on the musical attributes influencing human preferences, indicating that text adherence and quality only account for a part of it. This underscores the prevalence of subjectivity in musical appreciation and calls for further involvement of human listeners in the finetuning of music generation models.
翻译:我们提出MusicRL,这是首个基于人类反馈微调的音乐生成系统。文本到音乐模型的鉴赏尤其具有主观性,因为音乐性的概念以及特定文本描述背后的意图均依赖于用户(例如,"快节奏健身音乐"这样的描述可能对应复古吉他独奏或电子流行节拍)。这不仅使得此类模型的监督训练具有挑战性,还要求在其部署后的微调过程中整合持续的人类反馈。MusicRL是一个预训练的自回归MusicLM(Agostinelli等人,2023)模型,该模型对离散音频令牌进行强化学习微调以最大化序列级奖励。我们借助选定的标注员设计了与文本一致性和音频质量相关的奖励函数,并利用这些函数将MusicLM微调为MusicRL-R。我们将MusicLM部署给用户,并收集了包含30万个成对偏好的大规模数据集。通过基于人类反馈的强化学习(RLHF),我们训练了首个大规模整合人类反馈的文本到音乐模型MusicRL-U。人类评估表明,MusicRL-R和MusicRL-U均优于基线模型。最终,MusicRL-RU结合了两种方法,根据人类评估员的判断获得了最佳模型。消融研究揭示了影响人类偏好的音乐属性,表明文本一致性和音频质量仅解释了其中一部分因素。这凸显了音乐欣赏中主观性的普遍性,并呼吁在音乐生成模型的微调中进一步纳入人类听众的参与。