
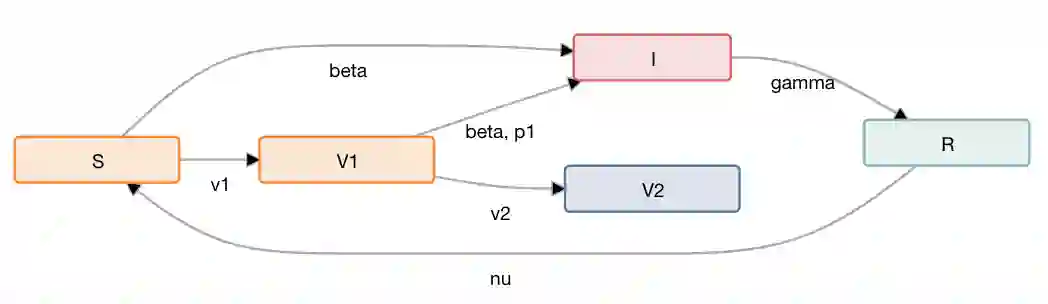
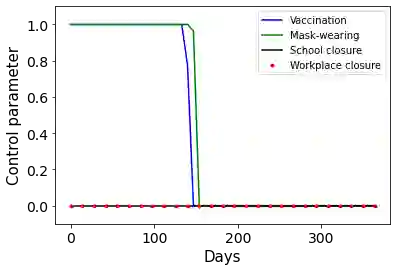
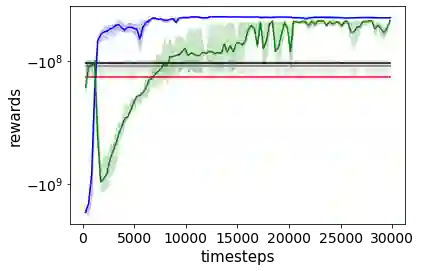
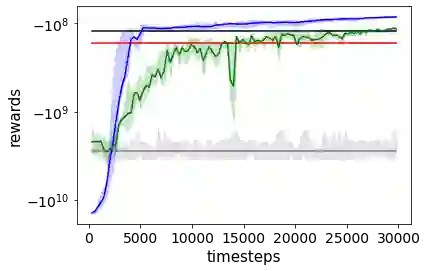
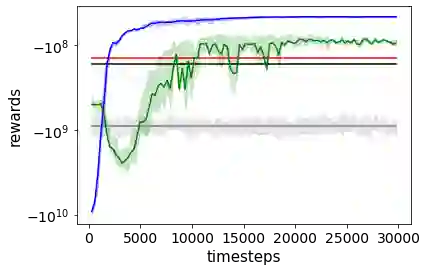
Combating an epidemic entails finding a plan that describes when and how to apply different interventions, such as mask-wearing mandates, vaccinations, school or workplace closures. An optimal plan will curb an epidemic with minimal loss of life, disease burden, and economic cost. Finding an optimal plan is an intractable computational problem in realistic settings. Policy-makers, however, would greatly benefit from tools that can efficiently search for plans that minimize disease and economic costs especially when considering multiple possible interventions over a continuous and complex action space given a continuous and equally complex state space. We formulate this problem as a Markov decision process. Our formulation is unique in its ability to represent multiple continuous interventions over any disease model defined by ordinary differential equations. We illustrate how to effectively apply state-of-the-art actor-critic reinforcement learning algorithms (PPO and SAC) to search for plans that minimize overall costs. We empirically evaluate the learning performance of these algorithms and compare their performance to hand-crafted baselines that mimic plans constructed by policy-makers. Our method outperforms baselines. Our work confirms the viability of a computational approach to support policy-makers
翻译:对抗流行病需要制定计划,描述何时及如何应用不同干预措施,例如口罩强制令、疫苗接种、学校或工作场所关闭。最优计划能够以最小的生命损失、疾病负担和经济成本遏制疫情。在现实场景中,寻找最优计划是一个难以解决的计算问题。然而,决策制定者将极大受益于能够高效搜索最小化疾病和经济成本计划的工具,尤其是在考虑多个干预措施、连续且复杂的动作空间以及同样连续且复杂的状态空间时。我们将此问题建模为马尔可夫决策过程。该公式的独特性在于能够表示任何由常微分方程定义的疾病模型上的多个连续干预措施。我们展示了如何有效应用最先进的actor-critic强化学习算法(PPO和SAC)来搜索最小化总成本的计划。我们通过实验评估了这些算法的学习性能,并将其与模拟决策制定者手工制定的基线计划进行对比。我们的方法优于基线方法。该工作证实了支持决策制定者的计算方法的可行性。
相关内容

Source: Apple - iOS 8

