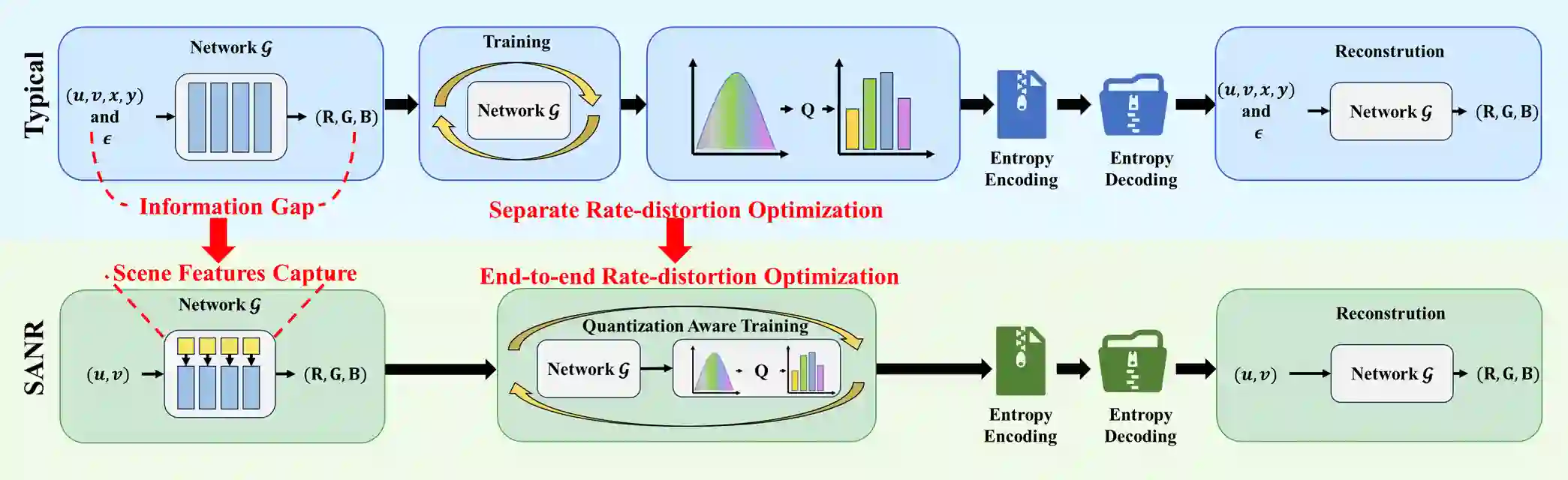
Light field images capture multi-view scene information and play a crucial role in 3D scene reconstruction. However, their high-dimensional nature results in enormous data volumes, posing a significant challenge for efficient compression in practical storage and transmission scenarios. Although neural representation-based methods have shown promise in light field image compression, most approaches rely on direct coordinate-to-pixel mapping through implicit neural representation (INR), often neglecting the explicit modeling of scene structure. Moreover, they typically lack end-to-end rate-distortion optimization, limiting their compression efficiency. To address these limitations, we propose SANR, a Scene-Aware Neural Representation framework for light field image compression with end-to-end rate-distortion optimization. For scene awareness, SANR introduces a hierarchical scene modeling block that leverages multi-scale latent codes to capture intrinsic scene structures, thereby reducing the information gap between INR input coordinates and the target light field image. From a compression perspective, SANR is the first to incorporate entropy-constrained quantization-aware training (QAT) into neural representation-based light field image compression, enabling end-to-end rate-distortion optimization. Extensive experiment results demonstrate that SANR significantly outperforms state-of-the-art techniques regarding rate-distortion performance with a 65.62\% BD-rate saving against HEVC.
翻译:光场图像能够捕获多视角场景信息,在三维场景重建中发挥着关键作用。然而,其高维特性导致数据量巨大,这为实际存储与传输场景中的高效压缩带来了重大挑战。尽管基于神经表示的方法在光场图像压缩中展现出潜力,但现有方法大多依赖通过隐式神经表示(INR)实现的坐标到像素的直接映射,往往忽略了对场景结构的显式建模。此外,这些方法通常缺乏端到端的率失真优化,限制了其压缩效率。为解决这些局限性,我们提出了SANR,一个具备端到端率失真优化的、面向光场图像压缩的感知场景神经表示框架。为实现场景感知,SANR引入了一个分层场景建模模块,该模块利用多尺度潜在编码来捕获场景的内在结构,从而减少INR输入坐标与目标光场图像之间的信息鸿沟。从压缩角度看,SANR首次将熵约束的量化感知训练(QAT)引入基于神经表示的光场图像压缩中,实现了端到端的率失真优化。大量实验结果表明,SANR在率失真性能上显著优于现有先进技术,相较于HEVC实现了65.62%的BD-rate节省。