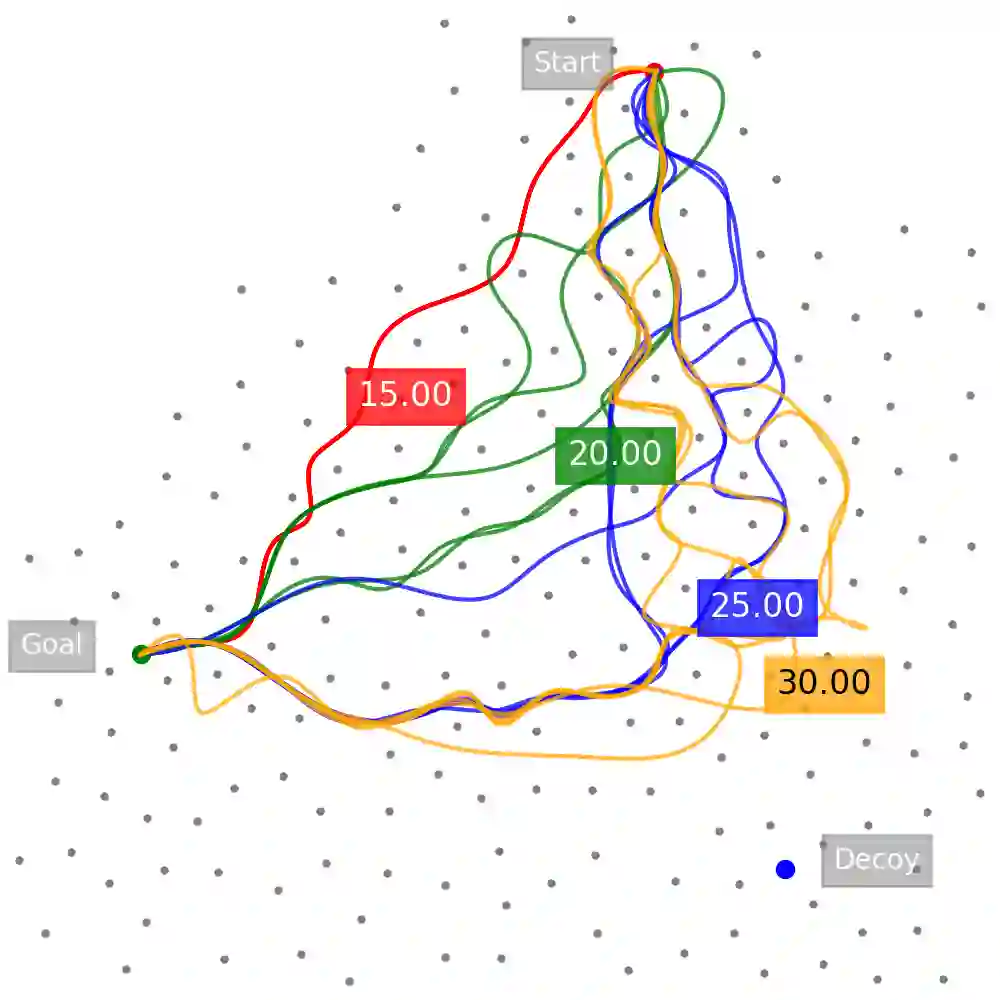
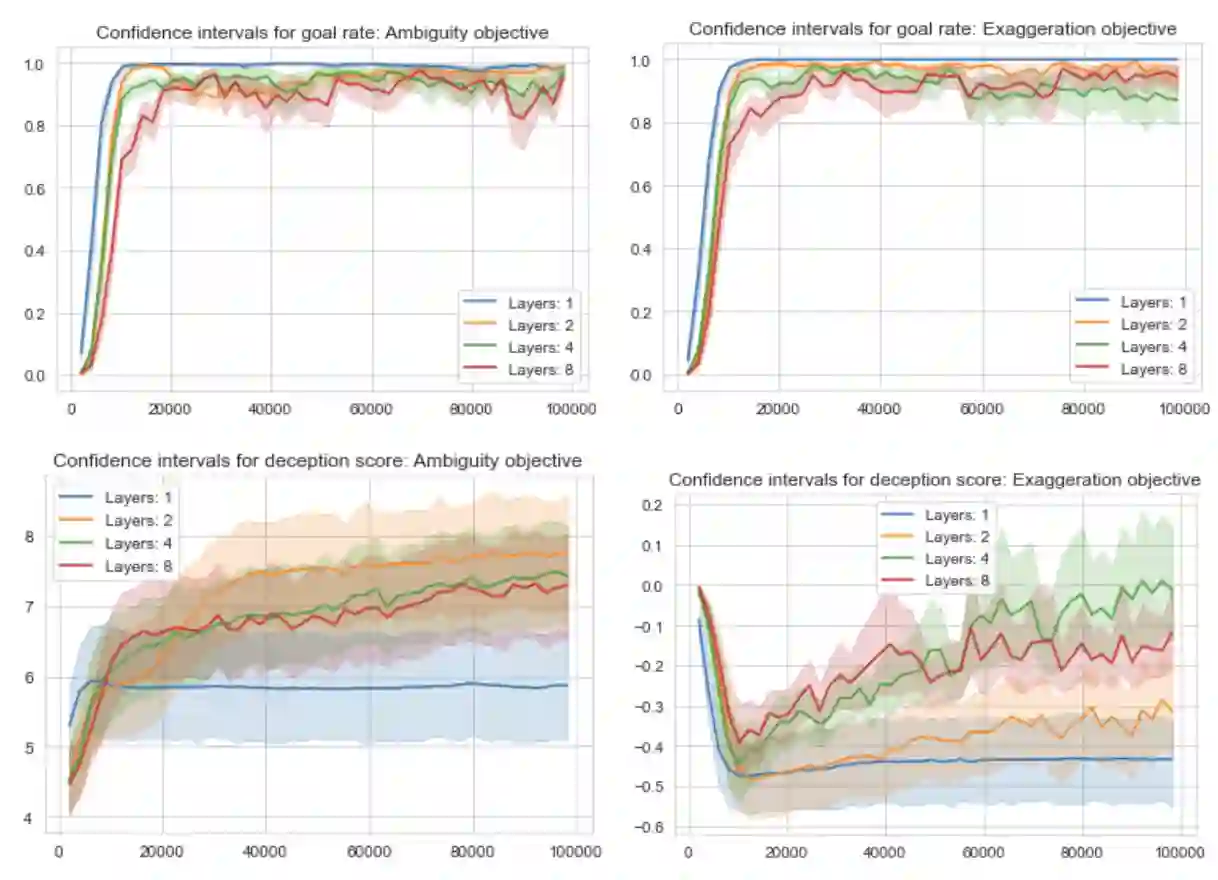
Deceptive path planning (DPP) is the problem of designing a path that hides its true goal from an outside observer. Existing methods for DPP rely on unrealistic assumptions, such as global state observability and perfect model knowledge, and are typically problem-specific, meaning that even minor changes to a previously solved problem can force expensive computation of an entirely new solution. Given these drawbacks, such methods do not generalize to unseen problem instances, lack scalability to realistic problem sizes, and preclude both on-the-fly tunability of deception levels and real-time adaptivity to changing environments. In this paper, we propose a reinforcement learning (RL)-based scheme for training policies to perform DPP over arbitrary weighted graphs that overcomes these issues. The core of our approach is the introduction of a local perception model for the agent, a new state space representation distilling the key components of the DPP problem, the use of graph neural network-based policies to facilitate generalization and scaling, and the introduction of new deception bonuses that translate the deception objectives of classical methods to the RL setting. Through extensive experimentation we show that, without additional fine-tuning, at test time the resulting policies successfully generalize, scale, enjoy tunable levels of deception, and adapt in real-time to changes in the environment.
翻译:欺骗性路径规划(DPP)旨在设计一条能对外部观察者隐藏其真实目标的路径。现有DPP方法依赖于不切实际的假设,如全局状态可观测性和完美模型知识,且通常针对特定问题设计,这意味着即使对已解决问题进行微小修改,也可能导致需要重新计算全新的解决方案,耗费大量算力。鉴于这些缺陷,此类方法无法泛化到未见问题实例、缺乏对现实问题规模的可扩展性,并且无法实现欺骗程度的在线可调性及对动态环境的实时适应能力。本文提出一种基于强化学习(RL)的方案,用于在任意加权图上训练策略以执行DPP,从而克服上述问题。该方法的核心包括:为智能体引入局部感知模型、提炼DPP问题关键要素的新状态空间表征、采用基于图神经网络的策略架构以促进泛化与扩展性,以及引入将传统方法欺骗目标转化为强化学习框架的新型欺骗奖励机制。大量实验表明,无需额外微调,所得策略在测试阶段即可成功实现泛化与扩展,具备可调节的欺骗程度,并能实时适应环境变化。