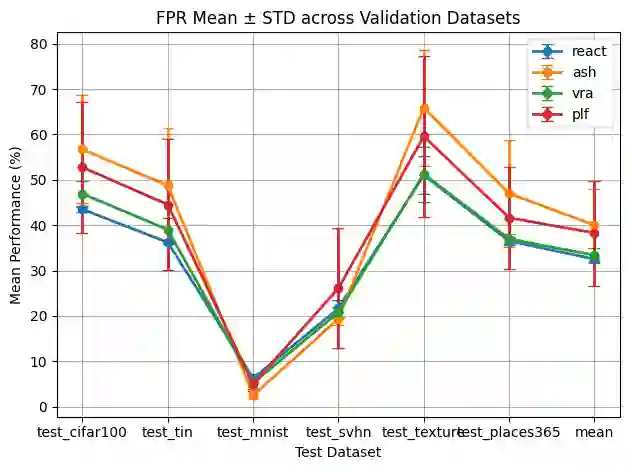
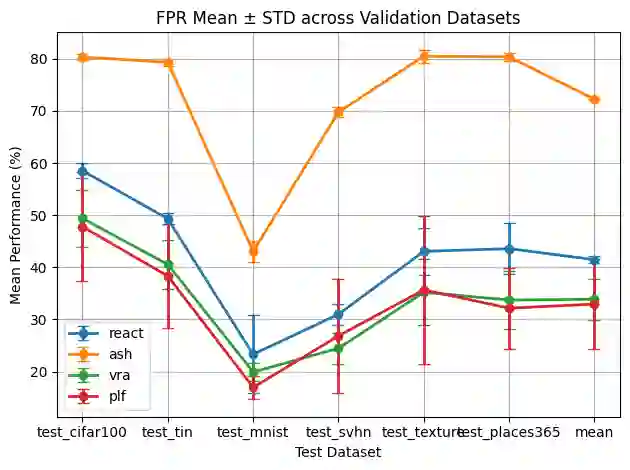
Existing out-of-distribution (OOD) detectors are often tuned by a separate dataset deemed OOD with respect to the training distribution of a neural network (NN). OOD detectors process the activations of NN layers and score the output, where parameters of the detectors are determined by fitting to an in-distribution (training) set and the aforementioned dataset chosen adhocly. At detector training time, this adhoc dataset may not be available or difficult to obtain, and even when it's available, it may not be representative of actual OOD data, which is often ''unknown unknowns." Current benchmarks may specify some left-out set from test OOD sets. We show that there can be significant variance in performance of detectors based on the adhoc dataset chosen in current literature, and thus even if such a dataset can be collected, the performance of the detector may be highly dependent on the choice. In this paper, we introduce and formalize the often neglected problem of tuning OOD detectors without a given ``OOD'' dataset. To this end, we present strong baselines as an attempt to approach this problem. Furthermore, we propose a new generic approach to OOD detector tuning that does not require any extra data other than those used to train the NN. We show that our approach improves over baseline methods consistently across higher-parameter OOD detector families, while being comparable across lower-parameter families.
翻译:现有的离群分布检测器通常通过一个相对于神经网络训练分布被视为离群分布的独立数据集进行调优。离群检测器处理神经网络各层的激活值并对其输出进行评分,其中检测器的参数通过拟合分布内数据(训练集)和前述临时选定的数据集来确定。在检测器训练阶段,这种临时数据集可能无法获取或难以获得,即使能够获得,也可能无法代表实际的离群数据——这些数据通常属于“未知的未知”。当前基准测试可能会指定从测试离群集中留出的某些子集。我们证明,基于现有文献中选定的临时数据集,检测器的性能可能存在显著差异,因此即使能够收集到此类数据集,检测器的性能也可能高度依赖于数据集的选择。本文针对这一常被忽视的问题——在未给定“离群”数据集的情况下调优离群检测器——进行了系统阐述与形式化定义。为此,我们提出了一系列强基线方法作为解决该问题的初步尝试。此外,我们提出了一种新的通用离群检测器调优方法,该方法仅需使用训练神经网络时所用的数据,无需任何额外数据。实验表明,我们的方法在高参数离群检测器家族中持续优于基线方法,同时在低参数家族中保持可比性能。