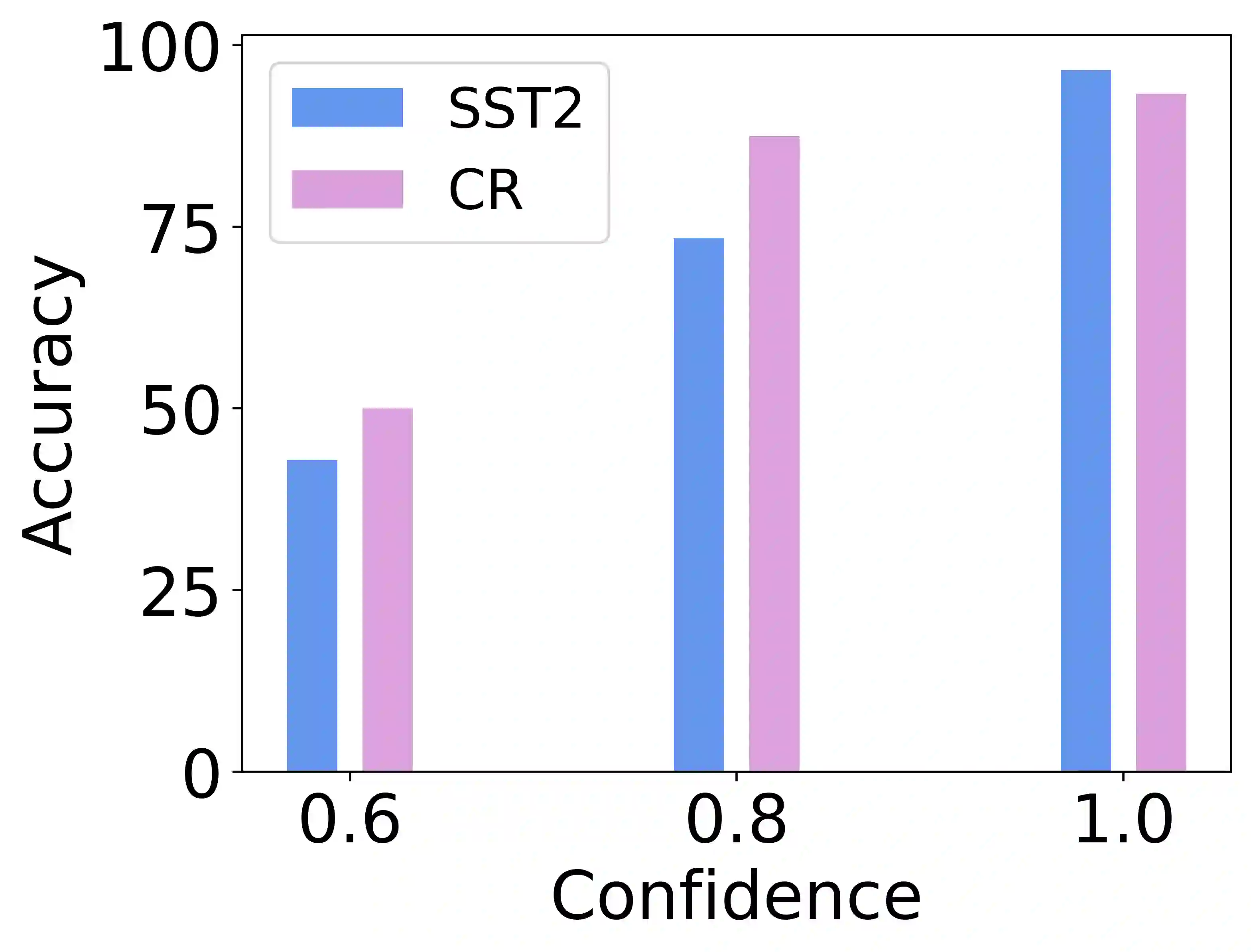
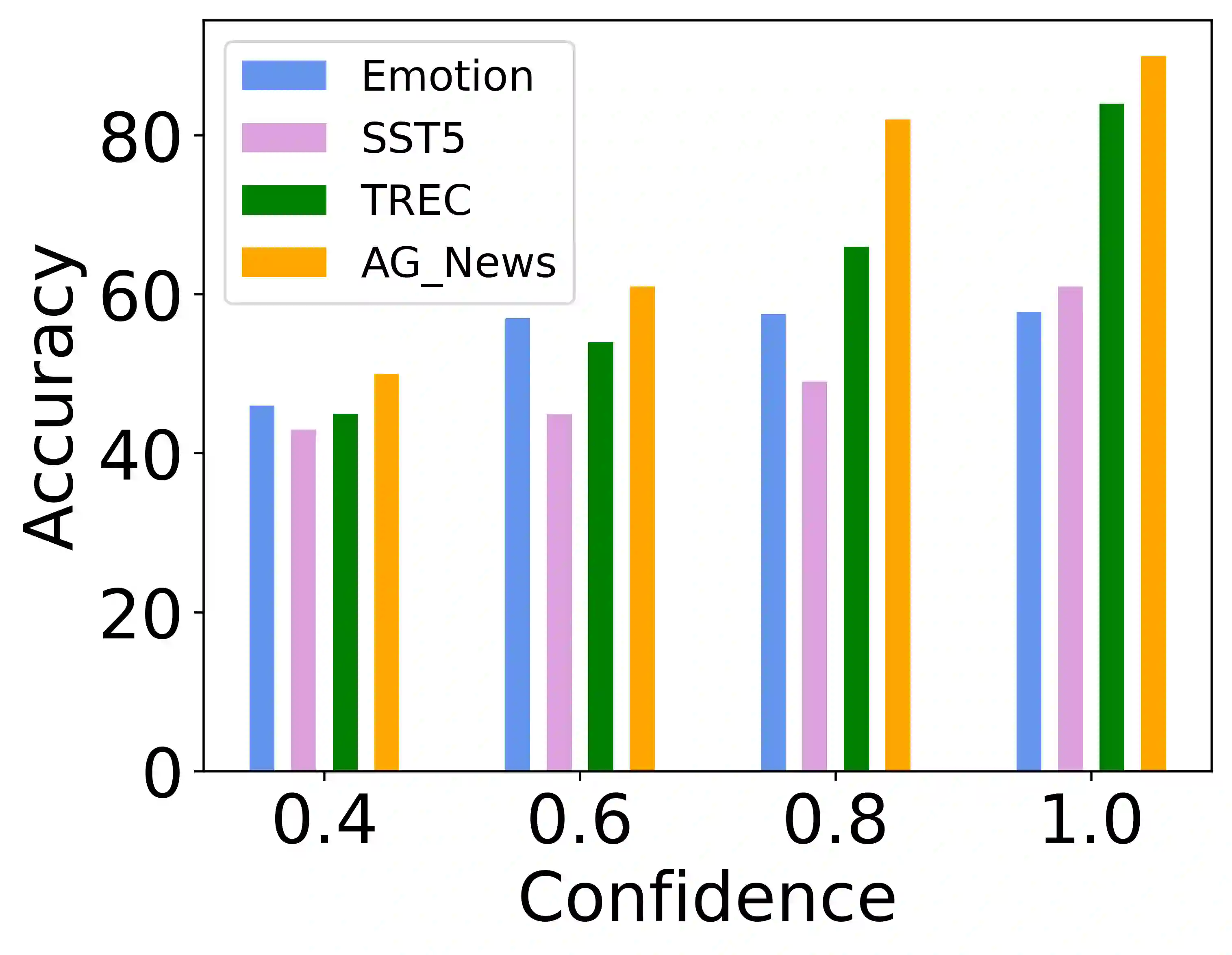
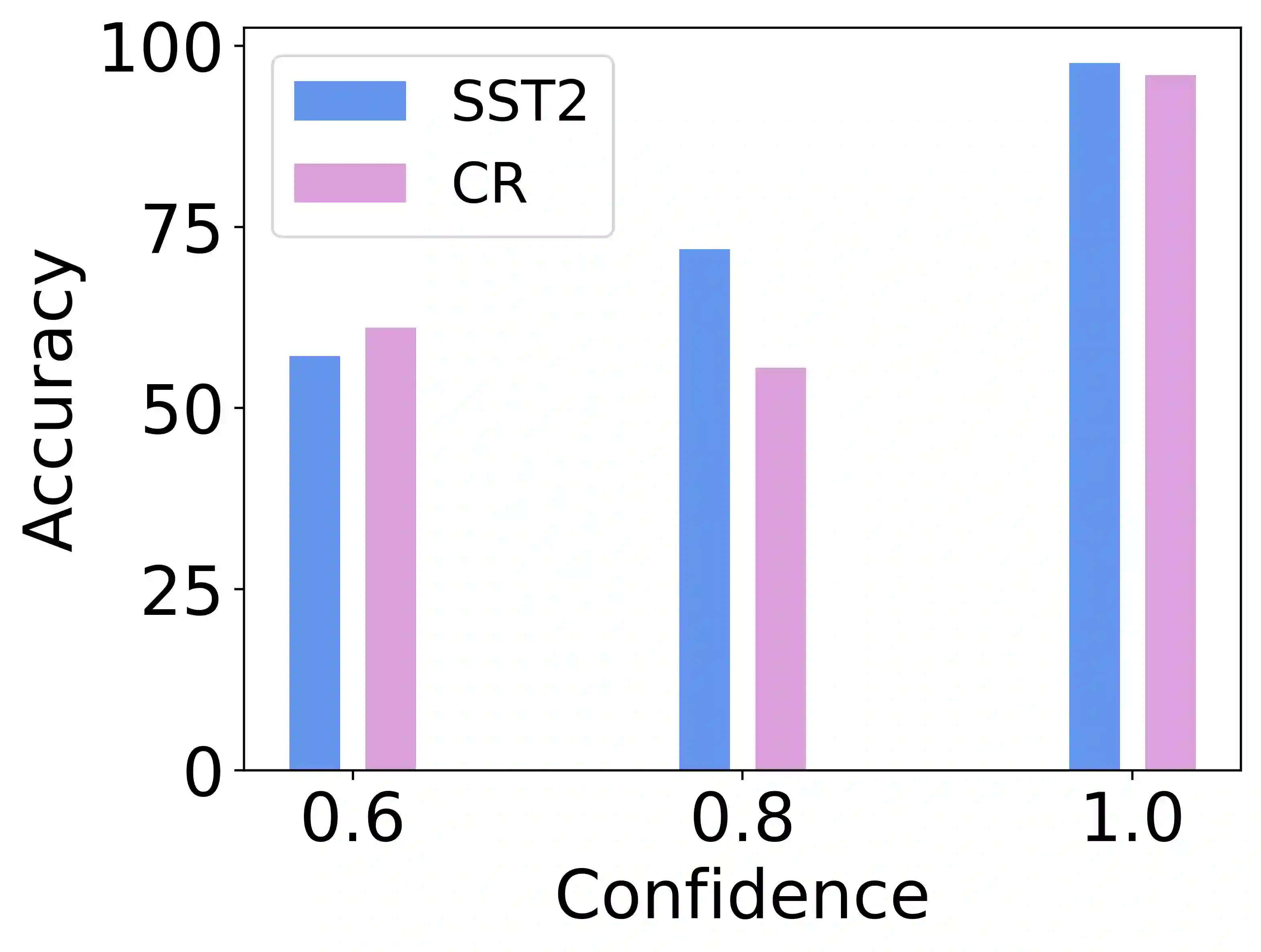
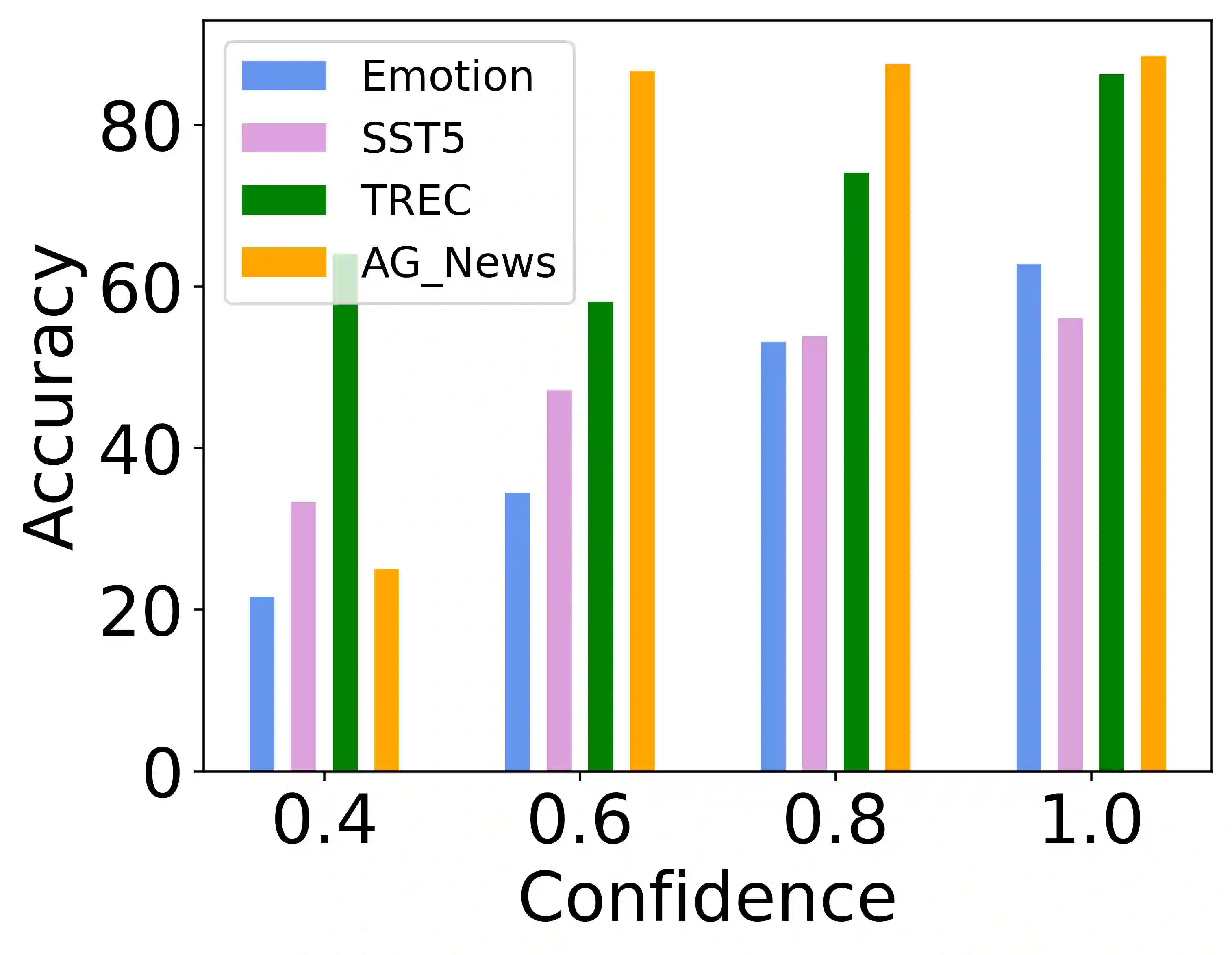
In-Context Learning (ICL) combined with pre-trained large language models has achieved promising results on various NLP tasks. However, ICL requires high-quality annotated demonstrations which might not be available in real-world scenarios. To overcome this limitation, we propose \textbf{D}ata \textbf{A}ugmentation for \textbf{I}n-Context \textbf{L}earning (\textbf{DAIL}). DAIL leverages the intuition that large language models are more familiar with the content generated by themselves. It first utilizes the language model to generate paraphrases of the test sample and employs majority voting to determine the final result based on individual predictions. Our extensive empirical evaluation shows that DAIL outperforms the standard ICL method and other ensemble-based methods in the low-resource scenario. Additionally, we explore the use of voting consistency as a confidence score of the model when the logits of predictions are inaccessible. We believe our work will stimulate further research on ICL in low-resource settings.
翻译:上下文学习结合预训练大语言模型已在多种自然语言处理任务上取得了显著成果。然而,上下文学习需要高质量的标注示例,这在现实场景中可能难以获取。为克服这一局限,我们提出面向上下文学习的数据增强方法(DAIL)。DAIL基于大语言模型对自身生成内容更熟悉的直觉,首先利用该模型生成测试样本的释义版本,并通过多数投票法基于各独立预测结果确定最终输出。广泛的实证评估表明,在低资源场景下DAIL的性能优于标准上下文学习方法及其他集成方法。此外,我们还探索了在无法获取预测概率时,将投票一致性作为模型置信度分数的可行性。我们相信本工作将推动低资源环境下上下文学习相关研究的进一步发展。