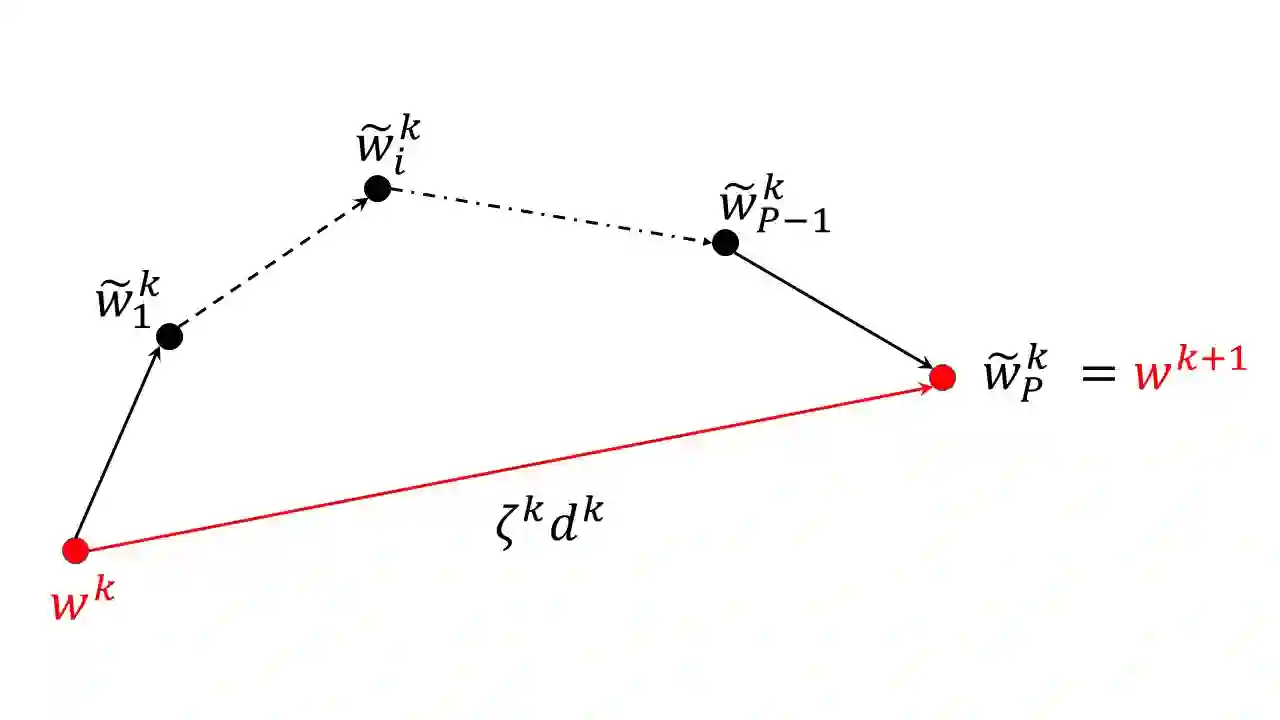
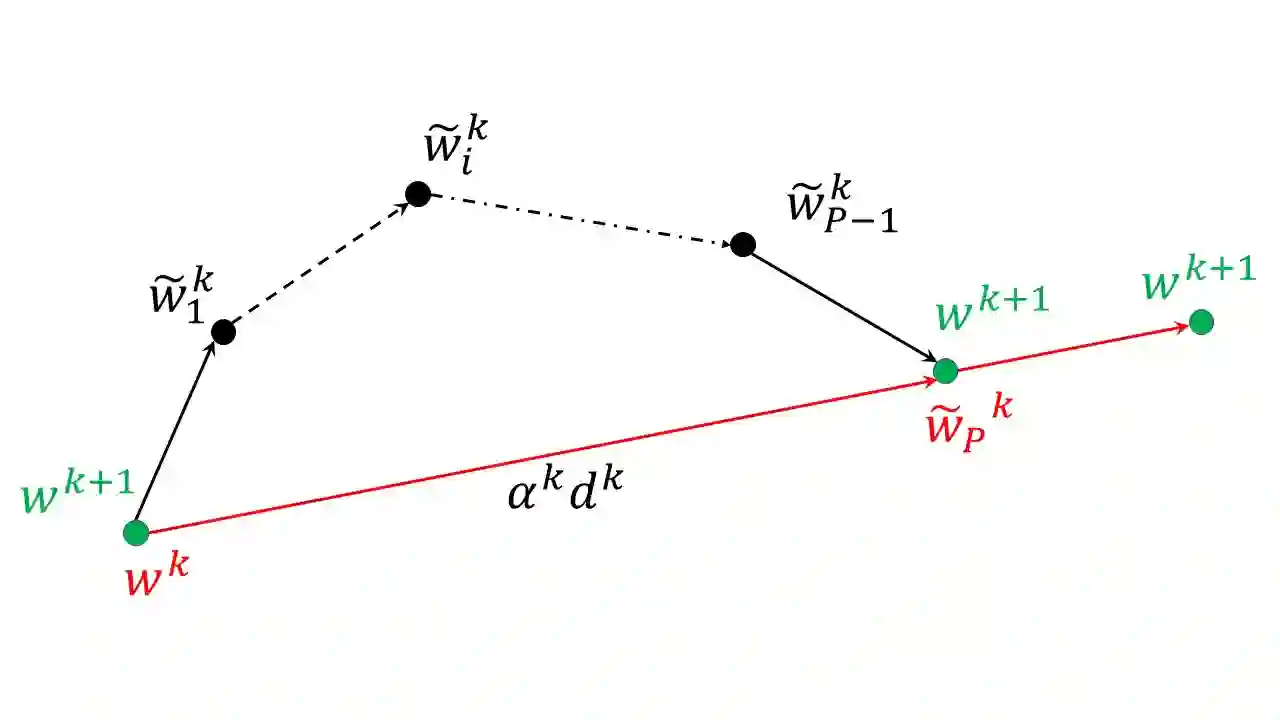
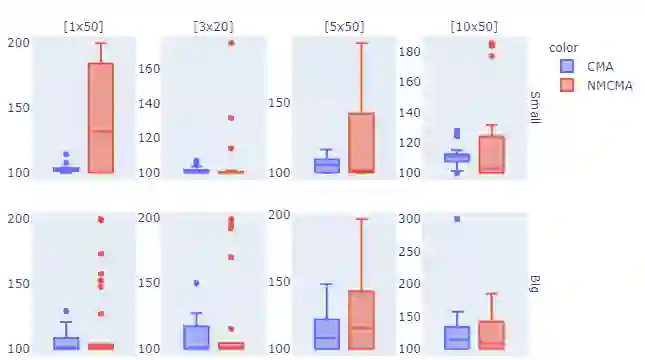
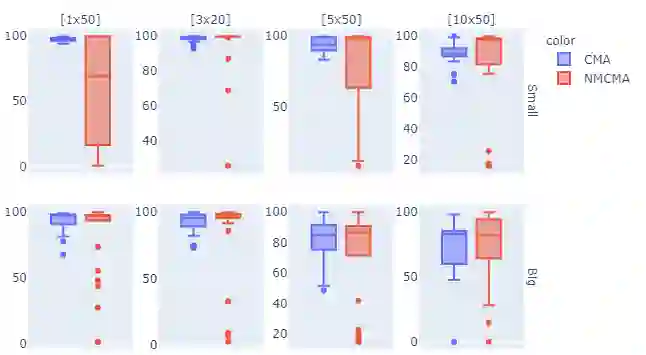
We consider minimizing the average of a very large number of smooth and possibly non-convex functions. This optimization problem has deserved much attention in the past years due to the many applications in different fields, the most challenging being training Machine Learning models. Widely used approaches for solving this problem are mini-batch gradient methods which, at each iteration, update the decision vector moving along the gradient of a mini-batch of the component functions. We consider the Incremental Gradient (IG) and the Random reshuffling (RR) methods which proceed in cycles, picking batches in a fixed order or by reshuffling the order after each epoch. Convergence properties of these schemes have been proved under different assumptions, usually quite strong. We aim to define ease-controlled modifications of the IG/RR schemes, which require a light additional computational effort and can be proved to converge under very weak and standard assumptions. In particular, we define two algorithmic schemes, monotone or non-monotone, in which the IG/RR iteration is controlled by using a watchdog rule and a derivative-free line search that activates only sporadically to guarantee convergence. The two schemes also allow controlling the updating of the stepsize used in the main IG/RR iteration, avoiding the use of preset rules. We prove convergence under the lonely assumption of Lipschitz continuity of the gradients of the component functions and perform extensive computational analysis using Deep Neural Architectures and a benchmark of datasets. We compare our implementation with both full batch gradient methods and online standard implementation of IG/RR methods, proving that the computational effort is comparable with the corresponding online methods and that the control on the learning rate may allow faster decrease.
翻译:我们考虑极小化大量光滑且可能非凸函数的平均值问题。该优化问题因在不同领域的广泛应用(最具挑战性的是机器学习模型训练)而备受关注。解决该问题的常用方法是小批量梯度法,每次迭代通过沿小批量分量函数梯度方向更新决策向量。我们考虑增量梯度(IG)和随机重排(RR)方法,它们按周期进行,批次按固定顺序选择或在每个epoch后重排顺序。这些方案的收敛性已在不同假设下得到证明,但这些假设通常较强。我们旨在定义IG/RR方案的易控改进,该改进只需增加少量计算量,且能在极弱的标准假设下证明收敛性。具体而言,我们定义了两种算法方案(单调或非单调),通过看门狗规则和仅偶尔激活以保证收敛的无导数线搜索来控制IG/RR迭代。这两种方案还允许控制主IG/RR迭代中使用的步长更新,无需预设规则。我们在仅假设分量函数梯度Lipschitz连续性的条件下证明收敛性,并使用深度神经网络架构和基准数据集进行大量计算分析。我们将我们的实现与全批量梯度方法和IG/RR方法的标准在线实现进行比较,证明计算量与相应在线方法相当,且学习率的控制可实现更快的下降。