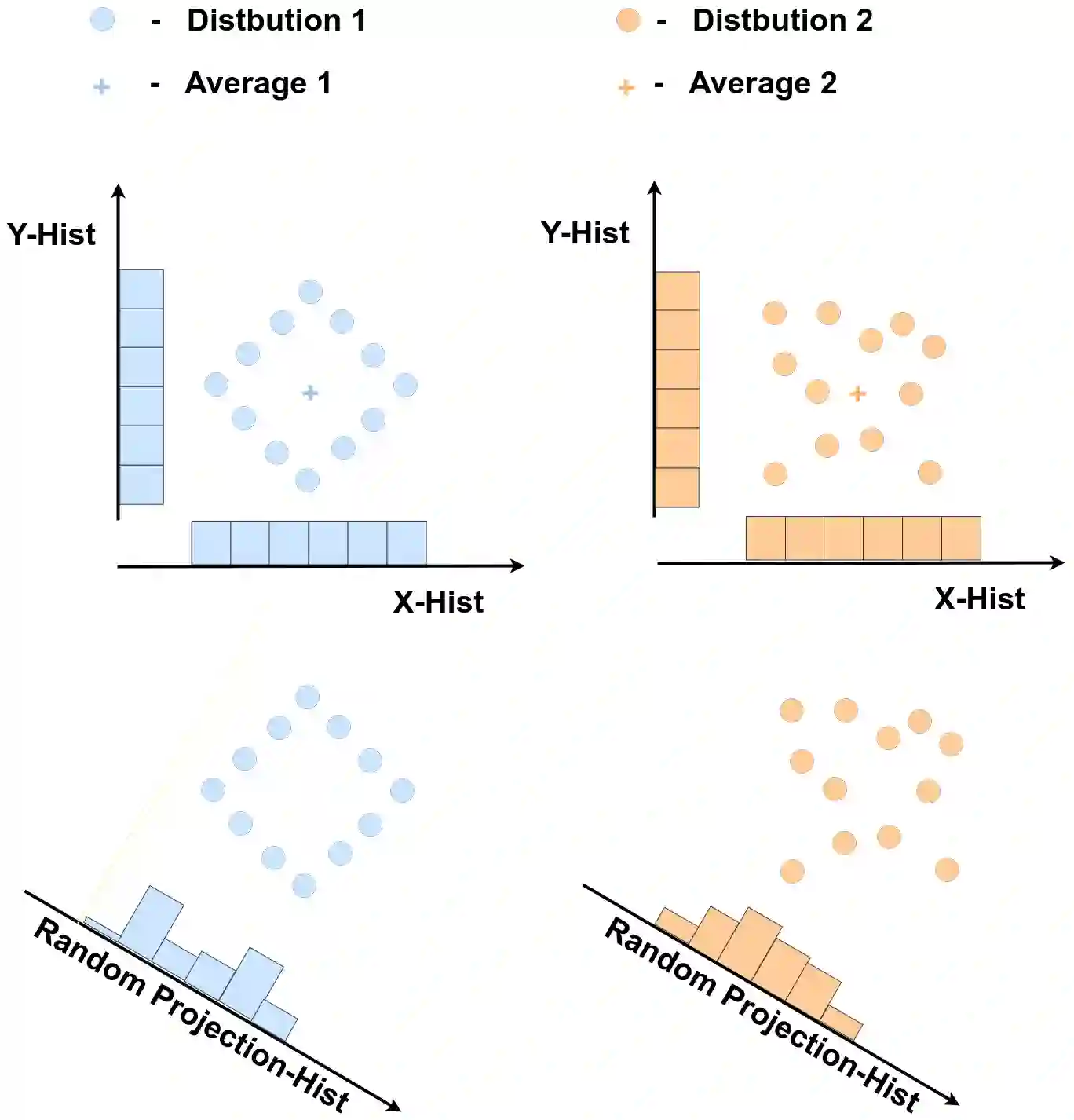
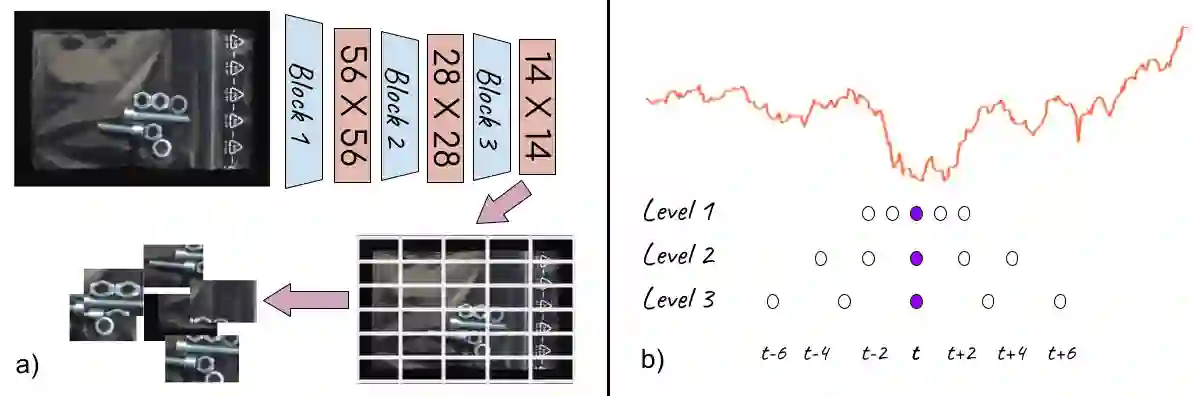
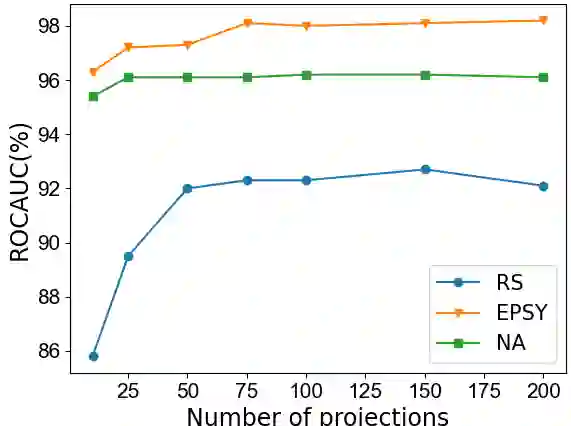
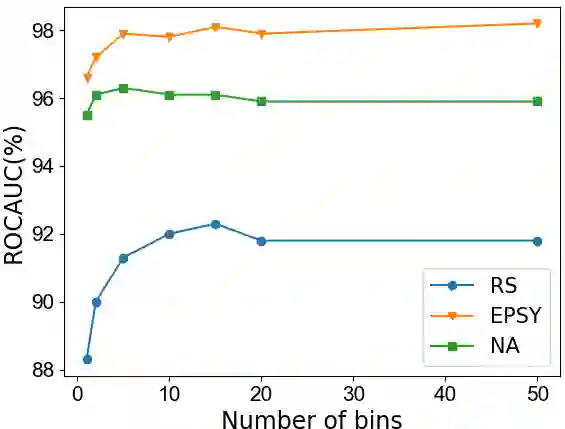
Fine-grained anomaly detection has recently been dominated by segmentation based approaches. These approaches first classify each element of the sample (e.g., image patch) as normal or anomalous and then classify the entire sample as anomalous if it contains anomalous elements. However, such approaches do not extend to scenarios where the anomalies are expressed by an unusual combination of normal elements. In this paper, we overcome this limitation by proposing set features that model each sample by the distribution its elements. We compute the anomaly score of each sample using a simple density estimation method. Our simple-to-implement approach outperforms the state-of-the-art in image-level logical anomaly detection (+3.4%) and sequence-level time-series anomaly detection (+2.4%).
翻译:细粒度异常检测近期主要由基于分割的方法主导。这些方法首先将样本的每个元素(如图像块)分类为正常或异常,随后若样本包含异常元素则将其整体判定为异常。然而,此类方法无法推广至异常表现为正常元素异常组合的场景。本文通过提出集合特征克服了这一局限,该特征通过元素分布对每个样本进行建模。我们采用简单的密度估计方法计算各样本的异常分数。这种易于实现的方案在图像级逻辑异常检测(+3.4%)和序列级时间序列异常检测(+2.4%)任务中均超越了现有最先进方法。