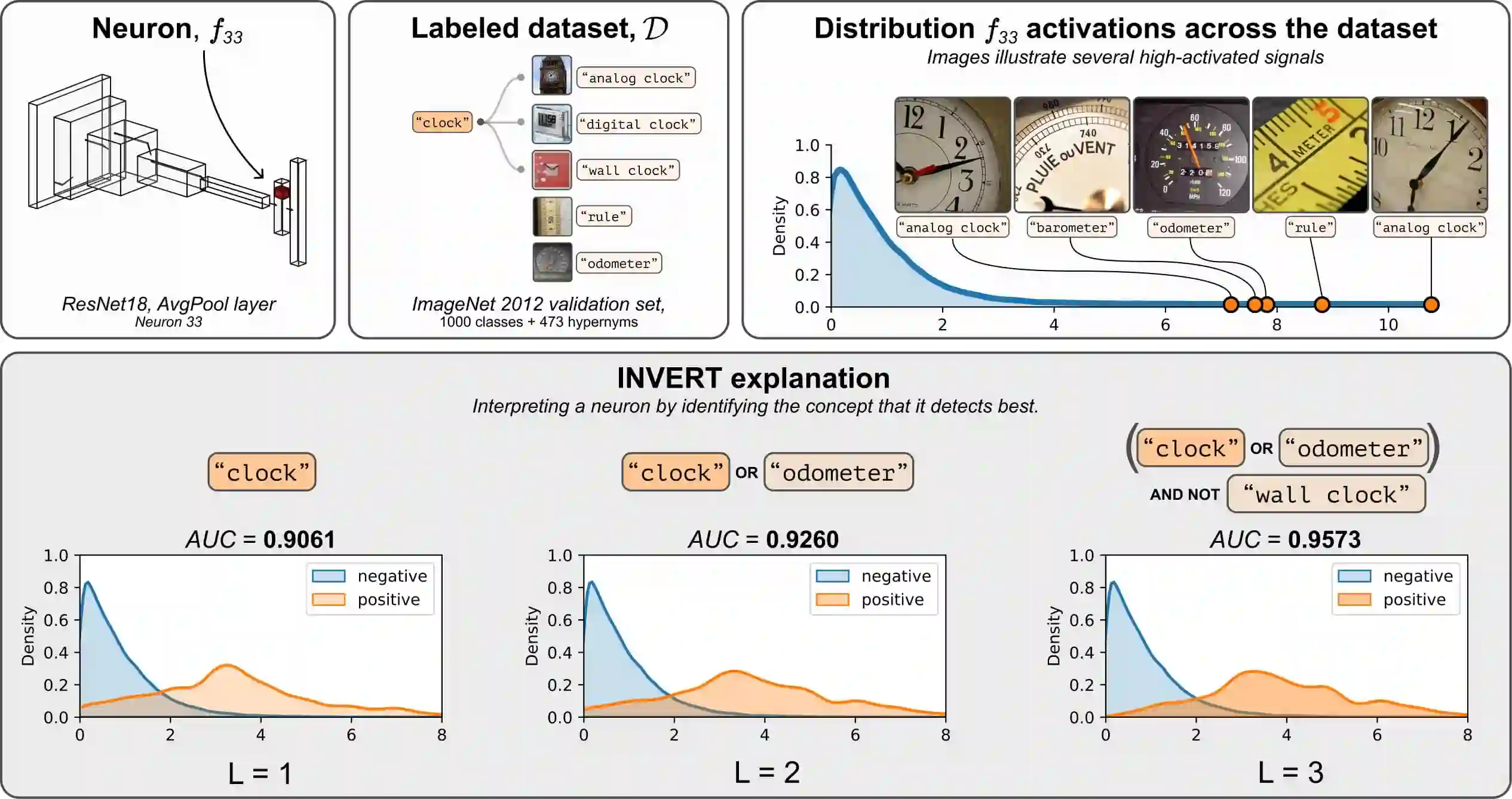
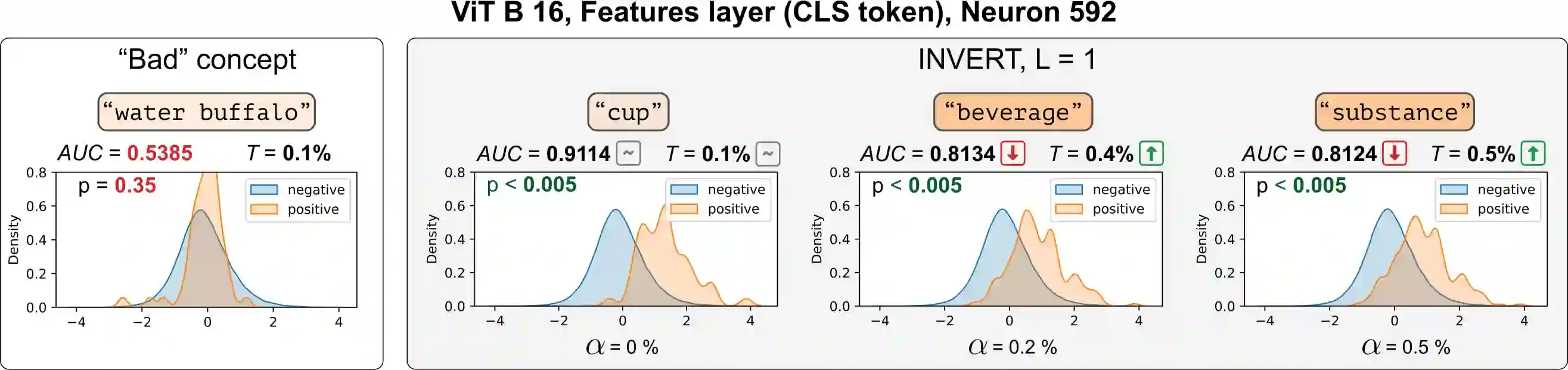
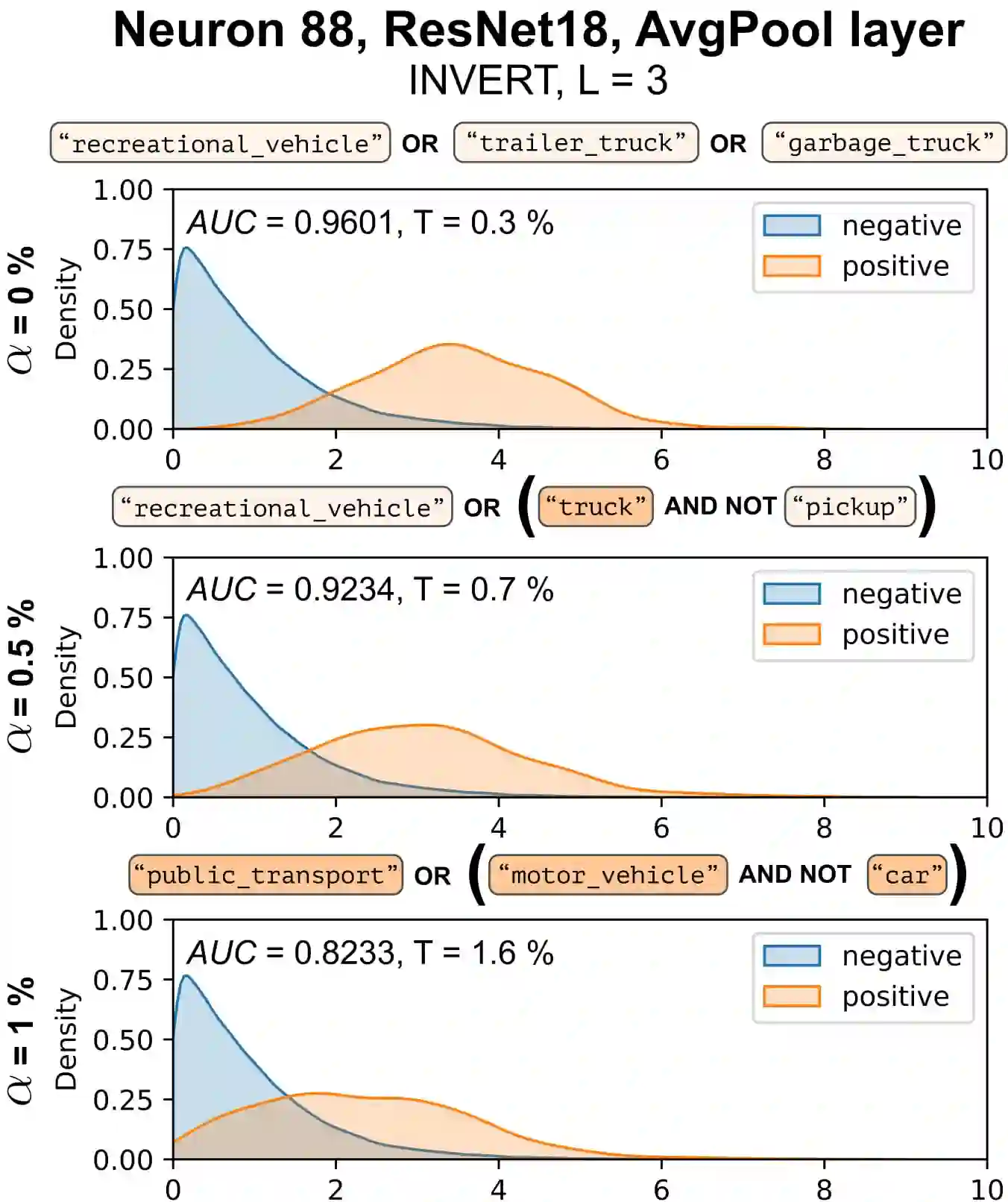
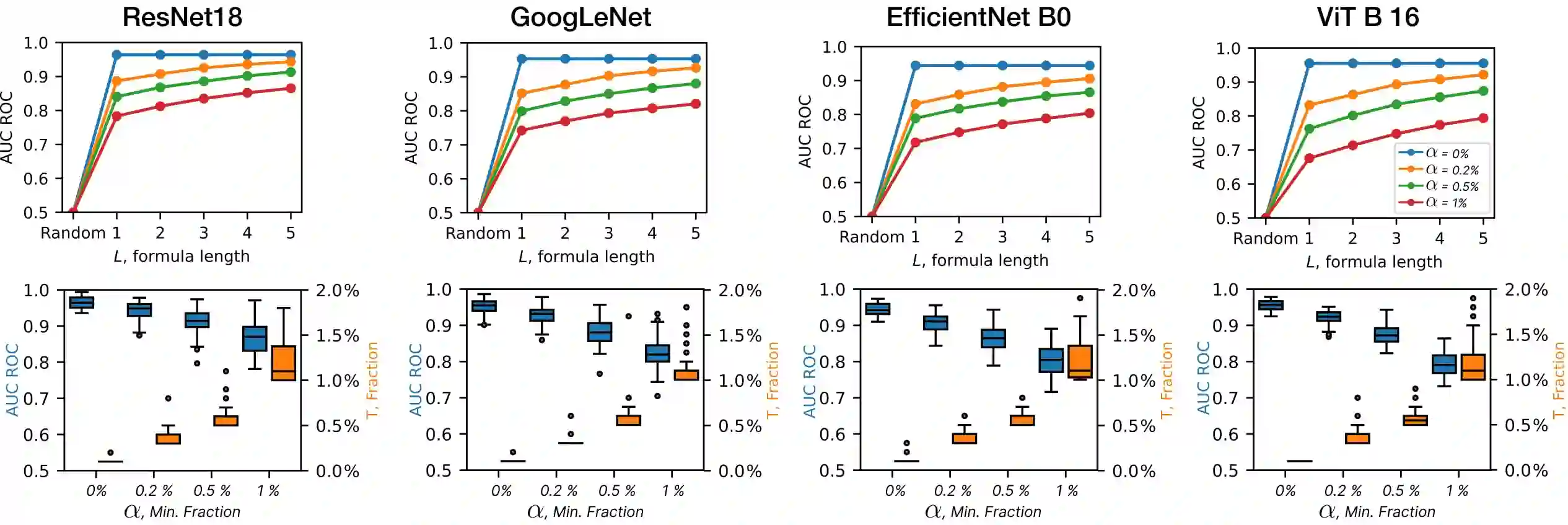
Deep Neural Networks (DNNs) demonstrated remarkable capabilities in learning complex hierarchical data representations, but the nature of these representations remains largely unknown. Existing global explainability methods, such as Network Dissection, face limitations such as reliance on segmentation masks, lack of statistical significance testing, and high computational demands. We propose Inverse Recognition (INVERT), a scalable approach for connecting learned representations with human-understandable concepts by leveraging their capacity to discriminate between these concepts. In contrast to prior work, INVERT is capable of handling diverse types of neurons, exhibits less computational complexity, and does not rely on the availability of segmentation masks. Moreover, INVERT provides an interpretable metric assessing the alignment between the representation and its corresponding explanation and delivering a measure of statistical significance, emphasizing its utility and credibility. We demonstrate the applicability of INVERT in various scenarios, including the identification of representations affected by spurious correlations, and the interpretation of the hierarchical structure of decision-making within the models.
翻译:深度神经网络(DNNs)在学习复杂层次数据表示方面展现出卓越的能力,但这些表示的本质仍很大程度上未知。现有的全局可解释性方法(如网络剖析)面临依赖分割掩码、缺乏统计显著性检验以及计算成本高昂等局限性。我们提出逆向识别(INVERT),这是一种可扩展的方法,通过利用学习到的表示区分人为可理解概念的能力,将这些表示与概念建立关联。与先前工作相比,INVERT能够处理多种类型的神经元,计算复杂度更低,且无需依赖分割掩码。此外,INVERT提供了一种可解释的度量,用于评估表示与其对应解释之间的一致性,并给出统计显著性指标,凸显了其实用性和可信度。我们展示了INVERT在多种场景中的适用性,包括识别受虚假相关性影响的表示,以及解释模型内部决策的层次结构。