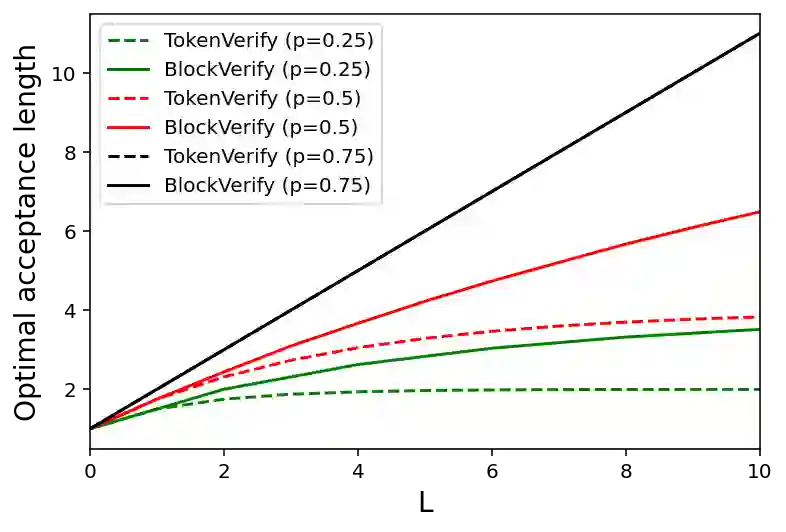
Speculative decoding has shown to be an effective method for lossless acceleration of large language models (LLMs) during inference. In each iteration, the algorithm first uses a smaller model to draft a block of tokens. The tokens are then verified by the large model in parallel and only a subset of tokens will be kept to guarantee that the final output follows the distribution of the large model. In all of the prior speculative decoding works, the draft verification is performed token-by-token independently. In this work, we propose a better draft verification algorithm that provides additional wall-clock speedup without incurring additional computation cost and draft tokens. We first formulate the draft verification step as a block-level optimal transport problem. The block-level formulation allows us to consider a wider range of draft verification algorithms and obtain a higher number of accepted tokens in expectation in one draft block. We propose a verification algorithm that achieves the optimal accepted length for the block-level transport problem. We empirically evaluate our proposed block-level verification algorithm in a wide range of tasks and datasets, and observe consistent improvements in wall-clock speedup when compared to token-level verification algorithm. To the best of our knowledge, our work is the first to establish improvement over speculative decoding through a better draft verification algorithm.
翻译:推测解码已被证明是一种在推理过程中无损加速大型语言模型(LLMs)的有效方法。在每次迭代中,算法首先使用较小的模型草拟一个令牌块,然后由大模型并行验证这些令牌,仅保留部分令牌以确保最终输出符合大模型的分布。在以往所有推测解码研究中,草稿验证均以逐令牌独立方式进行。本文提出一种更优的草稿验证算法,在无需额外计算开销和草稿令牌的情况下实现额外的实际时间加速。我们首先将草稿验证步骤形式化为块级最优传输问题。块级公式化允许我们考虑更广泛的草稿验证算法,并在单个草稿块中期望获得更多被接受的令牌。我们提出一种验证算法,能够在该块级传输问题上实现最优接受长度。我们在多种任务和数据集上对提出的块级验证算法进行了实证评估,与令牌级验证算法相比,观察到一致的实际时间加速比提升。据我们所知,本文是首个通过改进草稿验证算法来提升推测解码性能的研究工作。