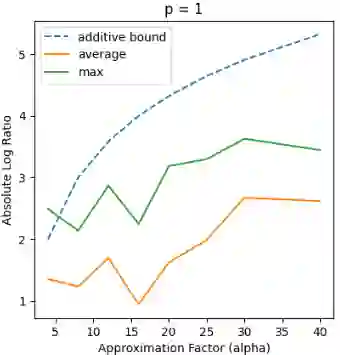
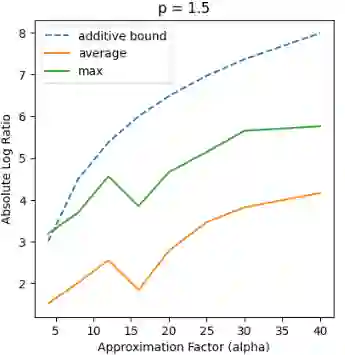
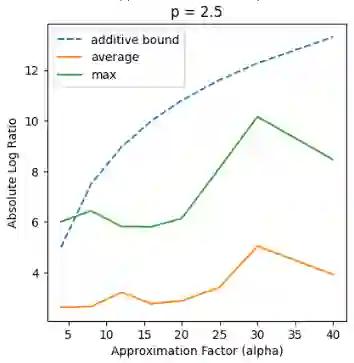
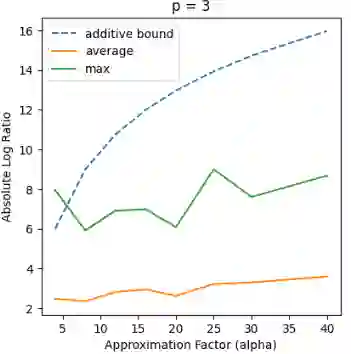
Recent works in dimensionality reduction for regression tasks have introduced the notion of sensitivity, an estimate of the importance of a specific datapoint in a dataset, offering provable guarantees on the quality of the approximation after removing low-sensitivity datapoints via subsampling. However, fast algorithms for approximating $\ell_p$ sensitivities, which we show is equivalent to approximate $\ell_p$ regression, are known for only the $\ell_2$ setting, in which they are termed leverage scores. In this work, we provide efficient algorithms for approximating $\ell_p$ sensitivities and related summary statistics of a given matrix. In particular, for a given $n \times d$ matrix, we compute $\alpha$-approximation to its $\ell_1$ sensitivities at the cost of $O(n/\alpha)$ sensitivity computations. For estimating the total $\ell_p$ sensitivity (i.e. the sum of $\ell_p$ sensitivities), we provide an algorithm based on importance sampling of $\ell_p$ Lewis weights, which computes a constant factor approximation to the total sensitivity at the cost of roughly $O(\sqrt{d})$ sensitivity computations. Furthermore, we estimate the maximum $\ell_1$ sensitivity, up to a $\sqrt{d}$ factor, using $O(d)$ sensitivity computations. We generalize all these results to $\ell_p$ norms for $p > 1$. Lastly, we experimentally show that for a wide class of matrices in real-world datasets, the total sensitivity can be quickly approximated and is significantly smaller than the theoretical prediction, demonstrating that real-world datasets have low intrinsic effective dimensionality.
翻译:近期针对回归任务的降维研究引入了敏感度概念,用于评估数据集中特定数据点的重要性,并通过子采样移除低敏感度数据点,为近似质量提供可证明的保证。然而,已知的近似 $\ell_p$ 敏感度的快速算法(我们证明其等价于近似 $\ell_p$ 回归)仅适用于 $\ell_2$ 情形,在此情形下该指标被称为杠杆分数。在本工作中,我们为给定矩阵的 $\ell_p$ 敏感度及相关汇总统计量的近似提供了高效算法。特别地,对于给定的 $n \times d$ 矩阵,我们以 $O(n/\alpha)$ 次敏感度计算的代价计算其 $\ell_1$ 敏感度的 $\alpha$ 近似值。针对总 $\ell_p$ 敏感度(即 $\ell_p$ 敏感度之和)的估计,我们提出了一种基于 $\ell_p$ Lewis 权重重要采样的算法,该算法以约 $O(\sqrt{d})$ 次敏感度计算的代价获得总敏感度的常数因子近似。此外,我们利用 $O(d)$ 次敏感度计算,将最大 $\ell_1$ 敏感度的估计误差控制在 $\sqrt{d}$ 因子范围内。我们将所有这些结果推广至 $p > 1$ 的 $\ell_p$ 范数。最后,实验表明,对于现实世界数据集中的广泛矩阵类别,总敏感度可快速近似且显著小于理论预测值,证明现实世界数据集具有较低的内在有效维度。