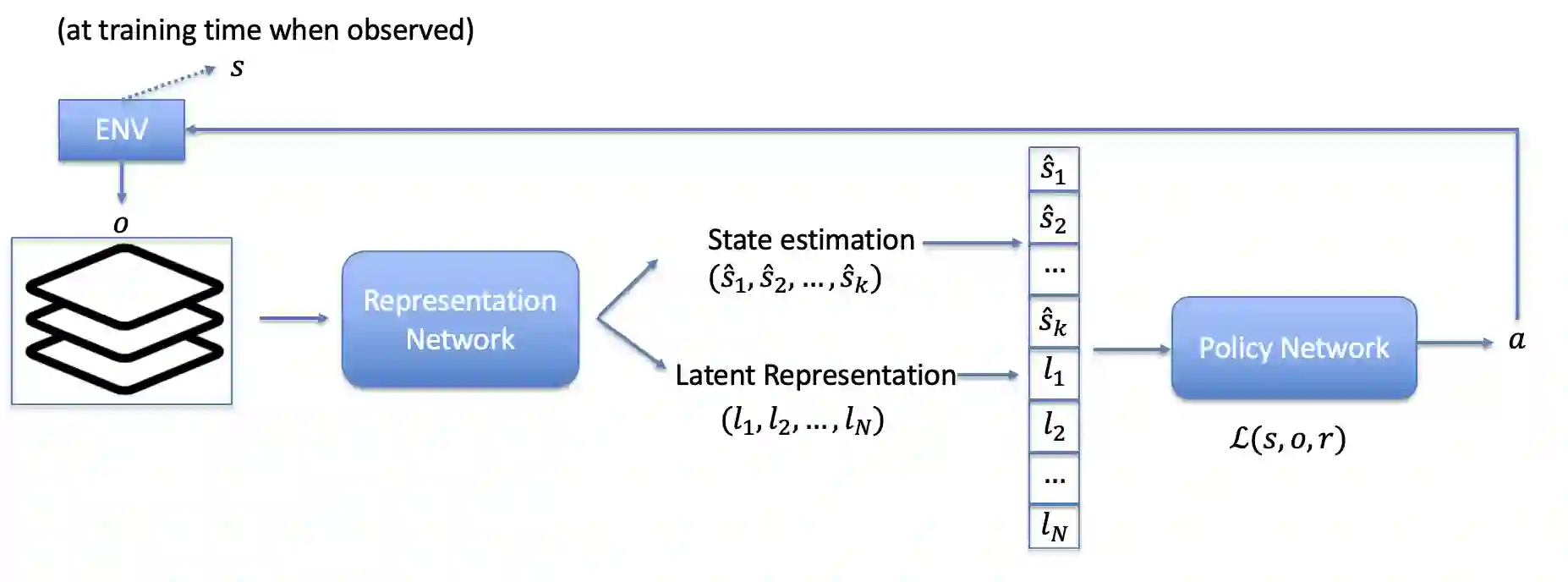
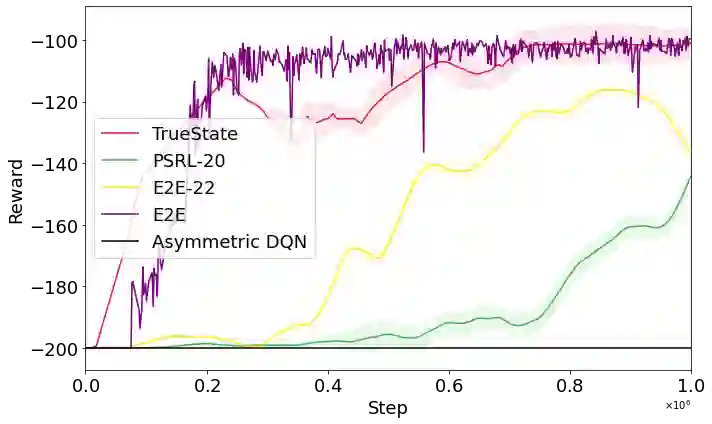
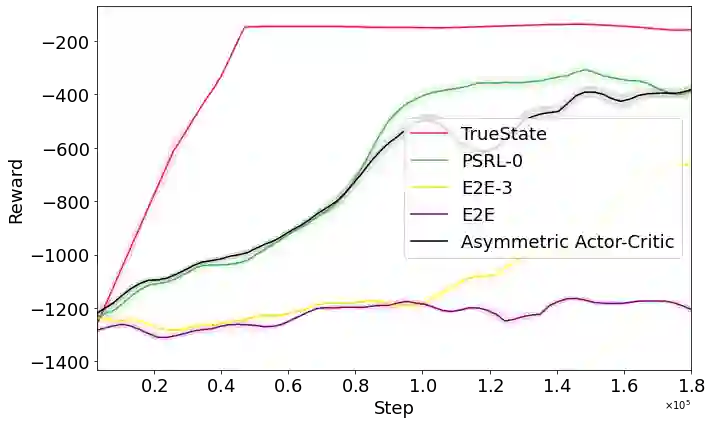
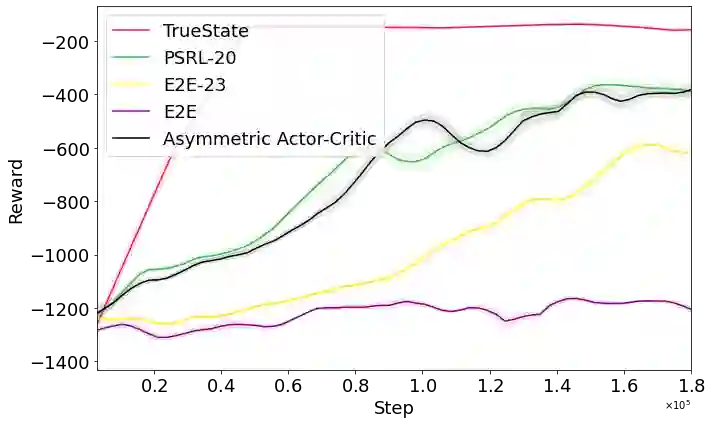
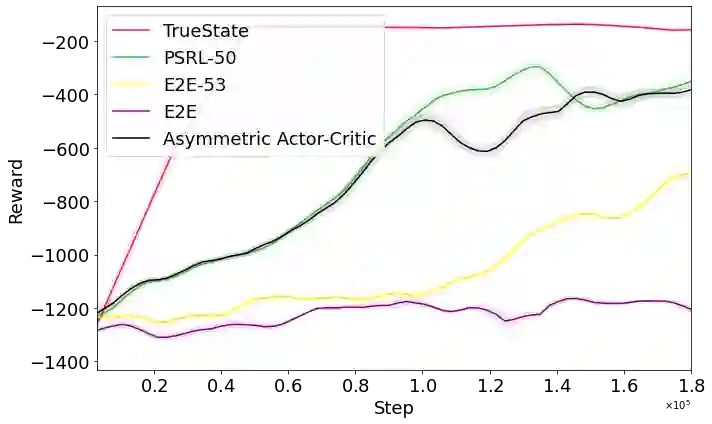
Deep reinforcement learning has demonstrated remarkable achievements across diverse domains such as video games, robotic control, autonomous driving, and drug discovery. Common methodologies in partially-observable domains largely lean on end-to-end learning from high-dimensional observations, such as images, without explicitly reasoning about true state. We suggest an alternative direction, introducing the Partially Supervised Reinforcement Learning (PSRL) framework. At the heart of PSRL is the fusion of both supervised and unsupervised learning. The approach leverages a state estimator to distill supervised semantic state information from high-dimensional observations which are often fully observable at training time. This yields more interpretable policies that compose state predictions with control. In parallel, it captures an unsupervised latent representation. These two-the semantic state and the latent state-are then fused and utilized as inputs to a policy network. This juxtaposition offers practitioners a flexible and dynamic spectrum: from emphasizing supervised state information to integrating richer, latent insights. Extensive experimental results indicate that by merging these dual representations, PSRL offers a potent balance, enhancing model interpretability while preserving, and often significantly outperforming, the performance benchmarks set by traditional methods in terms of reward and convergence speed.
翻译:摘要:深度强化学习已在视频游戏、机器人控制、自动驾驶和药物发现等多个领域展现出显著成果。在部分可观测领域,常见方法主要依赖从高维观测(如图像)进行端到端学习,而未显式推理真实状态。我们提出一种替代方向,引入部分监督强化学习(PSRL)框架。PSRL的核心是融合监督学习与无监督学习。该方法利用状态估计器从高维观测(通常在训练时完全可观测)中提取监督语义状态信息,从而生成更可解释的策略,这些策略将状态预测与控制相结合。同时,它捕获无监督潜在表示。语义状态和潜在状态这两者被融合并作为策略网络的输入。这种并置为实践者提供了灵活的动态谱系:从强调监督状态信息到整合更丰富的潜在洞察。大量实验结果表明,通过融合双重表示,PSRL实现了强大的平衡:增强模型可解释性,同时保持甚至显著超越传统方法在奖励和收敛速度方面的性能基准。