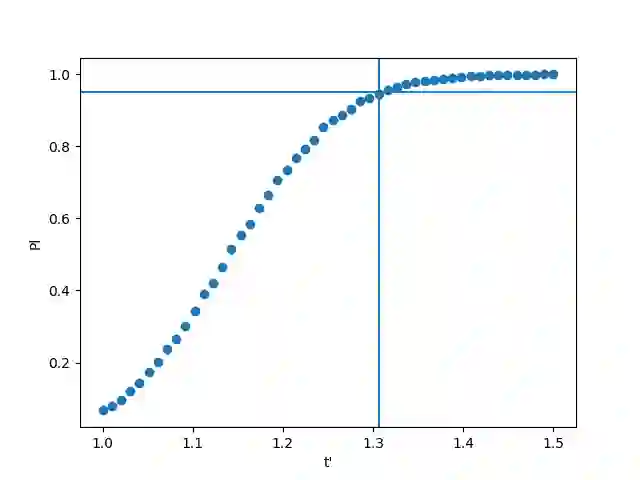
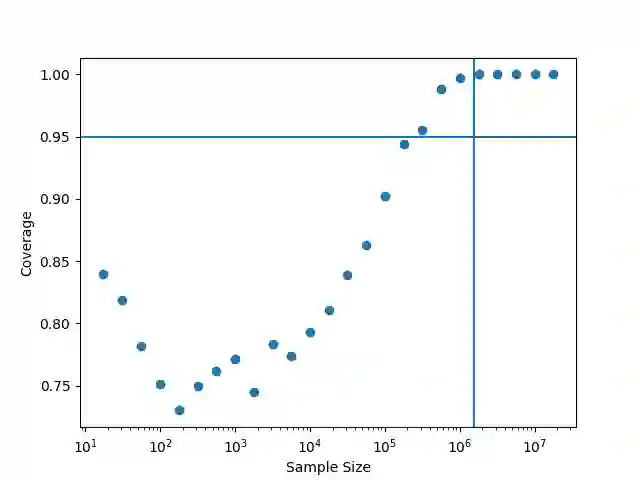
The parameters of a machine learning model are typically learned by minimizing a loss function on a set of training data. However, this can come with the risk of overtraining; in order for the model to generalize well, it is of great importance that we are able to find the optimal parameter for the model on the entire population -- not only on the given training sample. In this paper, we construct valid confidence sets for this optimal parameter of a machine learning model, which can be generated using only the training data without any knowledge of the population. We then show that studying the distribution of this confidence set allows us to assign a notion of confidence to arbitrary regions of the parameter space, and we demonstrate that this distribution can be well-approximated using bootstrapping techniques.
翻译:机器学习模型的参数通常通过在训练数据上最小化损失函数来学习。然而,这可能会带来过拟合的风险;为了使模型具有良好的泛化能力,能够找到模型在整个总体(而不仅仅是给定训练样本)上的最优参数至关重要。在本文中,我们为机器学习模型的这一最优参数构建了有效的置信集,该置信集仅需使用训练数据即可生成,而无需任何关于总体的知识。随后,我们证明研究该置信集的分布能够为参数空间的任意区域赋予置信度的概念,并展示该分布可以通过自举技术得到良好的近似。