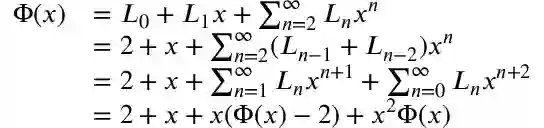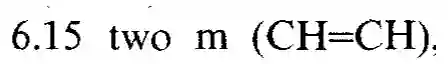This paper presents the UniMER dataset to provide the first study on Mathematical Expression Recognition (MER) towards complex real-world scenarios. The UniMER dataset consists of a large-scale training set UniMER-1M offering an unprecedented scale and diversity with one million training instances and a meticulously designed test set UniMER-Test that reflects a diverse range of formula distributions prevalent in real-world scenarios. Therefore, the UniMER dataset enables the training of a robust and high-accuracy MER model and comprehensive evaluation of model performance. Moreover, we introduce the Universal Mathematical Expression Recognition Network (UniMERNet), an innovative framework designed to enhance MER in practical scenarios. UniMERNet incorporates a Length-Aware Module to process formulas of varied lengths efficiently, thereby enabling the model to handle complex mathematical expressions with greater accuracy. In addition, UniMERNet employs our UniMER-1M data and image augmentation techniques to improve the model's robustness under different noise conditions. Our extensive experiments demonstrate that UniMERNet outperforms existing MER models, setting a new benchmark in various scenarios and ensuring superior recognition quality in real-world applications. The dataset and model are available at https://github.com/opendatalab/UniMERNet.
翻译:本文提出UniMER数据集,首次针对复杂真实场景下的数学表达式识别(MER)问题展开研究。UniMER数据集包含大规模训练集UniMER-1M,提供前所未有的规模与多样性——百万级训练实例,以及精心设计的测试集UniMER-Test,全面反映真实场景中常见的各类公式分布。该数据集能够支持鲁棒高精度MER模型的训练,并对模型性能进行全面评估。此外,我们提出通用数学表达式识别网络(UniMERNet),这是一套旨在增强实际场景中MER性能的创新框架。UniMERNet引入长度感知模块,高效处理不同长度的公式,从而提升模型对复杂数学表达式的识别准确率。同时,UniMERNet采用UniMER-1M数据与图像增强技术,增强模型在不同噪声条件下的鲁棒性。大量实验表明,UniMERNet优于现有MER模型,在多种场景下树立了新标杆,并确保真实应用中的卓越识别质量。数据集与模型已开源至https://github.com/opendatalab/UniMERNet。