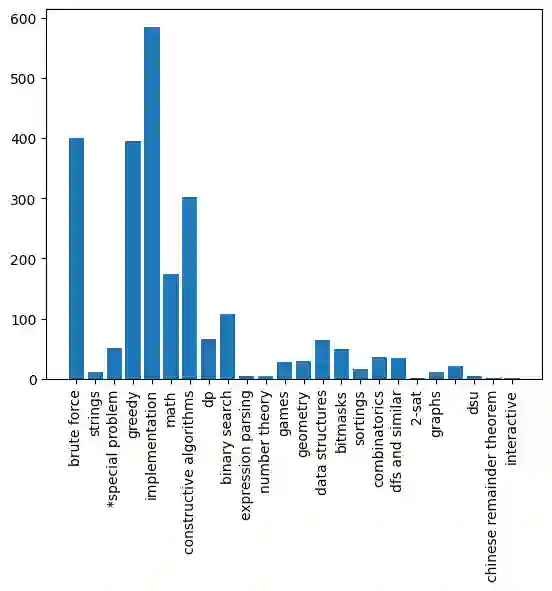
In the past decade, the amount of research being done in the fields of machine learning and deep learning, predominantly in the area of natural language processing (NLP), has risen dramatically. A well-liked method for developing programming abilities like logic building and problem solving is competitive programming. It can be tough for novices and even veteran programmers to traverse the wide collection of questions due to the massive number of accessible questions and the variety of themes, levels of difficulty, and questions offered. In order to help programmers find questions that are appropriate for their knowledge and interests, there is a need for an automated method. This can be done using automated tagging of the questions using Text Classification. Text classification is one of the important tasks widely researched in the field of Natural Language Processing. In this paper, we present a way to use text classification techniques to determine the domain of a competitive programming problem. A variety of models, including are implemented LSTM, GRU, and MLP. The dataset has been scraped from Codeforces, a major competitive programming website. A total of 2400 problems were scraped and preprocessed, which we used as a dataset for our training and testing of models. The maximum accuracy reached using our model is 78.0% by MLP(Multi Layer Perceptron).
翻译:过去十年间,机器学习和深度学习领域的研究大幅增长,尤其是在自然语言处理方面。竞赛编程作为一种广受欢迎的培养逻辑构建与问题解决等编程技能的方法,其可获取的问题数量庞大、主题、难度及题型多样,使得新手乃至经验丰富的程序员都难以在浩瀚题集中精准定位目标。为帮助程序员找到符合其知识水平和兴趣的问题,亟需一种自动化方法。这可通过基于文本分类的自动标注技术实现。文本分类是自然语言处理领域广泛研究的重要任务之一。本文提出利用文本分类技术判定竞赛编程问题所属领域的方法。我们实现了LSTM、GRU和MLP等多种模型。数据集从主流竞赛编程网站Codeforces爬取,共收集并预处理了2400道题目,用于模型训练与测试。其中,MLP(多层感知机)模型取得了最高78.0%的准确率。