
MKC资讯
近日,MKC 实验室在抑制多模态大语言模型(LVLMs)物体幻觉方向取得重要进展。实验室研究工作《HulluEdit: Single-Pass Evidence-Consistent Subspace Editing for Mitigating Hallucinations in Large Vision-Language Models》已被计算机视觉顶级国际会议 CVPR 2026 正式接收 。该工作提出了一种基于正交子空间分解的在线编辑框架,在保证推理效率的同时,有效解决了模型生成内容与视觉证据不一致的问题。
论文介绍
HulluEdit
CVPR 2026
“HulluEdit: Single-Pass Evidence-Consistent Subspace Editing for Mitigating Hallucinations in Large Vision-Language Models”
作者:林阳光,方全(通讯作者),李禹霏,孙佳辰,高君宇,桑基韬 论文链接:
https://arxiv.org/pdf/2602.22727 代码链接:
https://github.com/VioAgnes/HulluEdit

研究背景 多模态大语言模型(LVLMs)在图像描述和视觉问答中展现了卓越能力 。然而,模型仍面临严峻的物体幻觉挑战,即在生成文本时描述图像中不存在的对象、属性或关系 。这种现象通常源于强大的“语言先验”覆盖了较弱或模糊的“视觉证据”,导致生成内容与实际图像脱节。 如图1所示,现有方法在处理幻觉时面临以下核心挑战:1. 效率与精度的失衡:对比解码(Contrastive Decoding)等方法通常需要昂贵的参考模型或多次前向传播,增加了推理延迟 。2. 静态编辑的局限性:静态子空间编辑技术由于缺乏token级的自适应性,容易在抑制幻觉的同时误伤真实的视觉信息 。 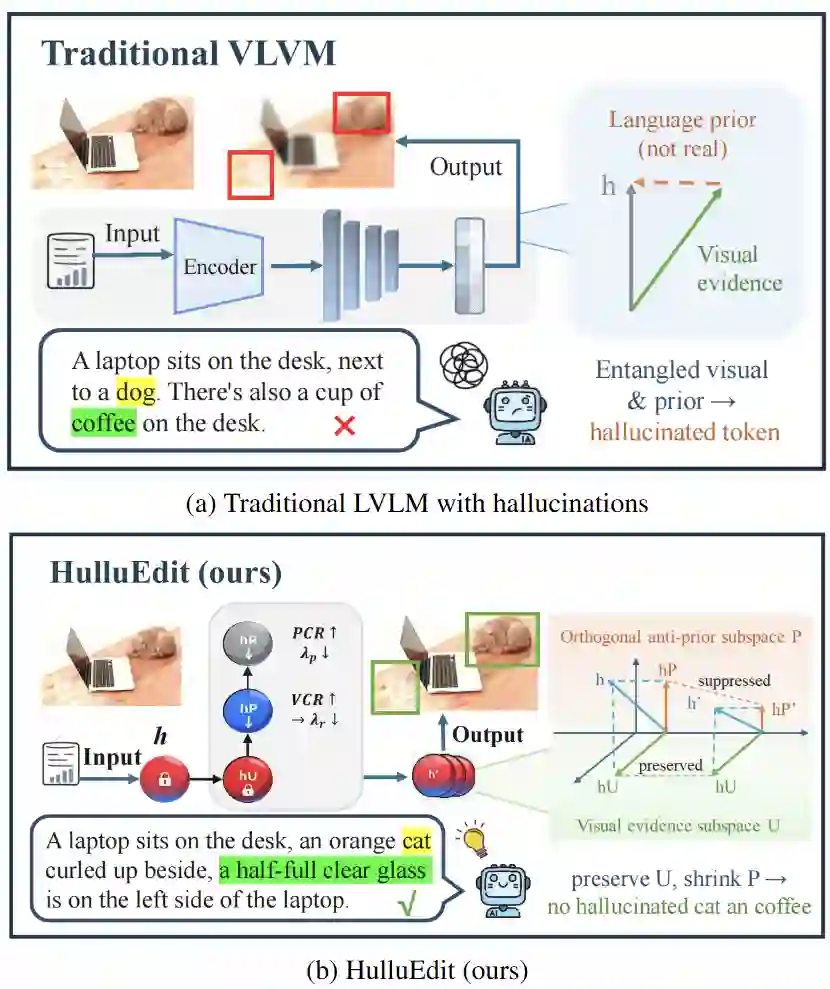

方法框架
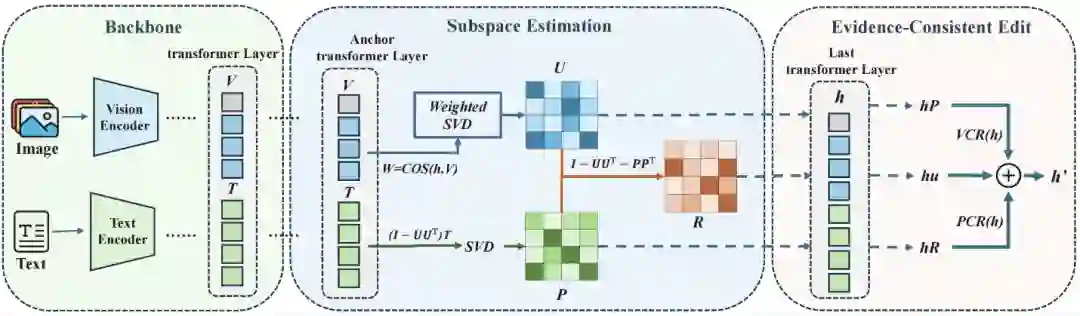
图 2 :HulluEdit 方法整体框架示意图
如图2所示,HulluEdit 框架通过三阶段实现高效且证据一致的幻觉抑制:首先选取模型中间层作为锚点层提取稳定的视觉特征,并同步维护动态文本缓存以捕获潜在的偏见模式;随后通过加权奇异值分解(Weighted SVD)在线估计视觉证据子空间U,并在其正交补空间内构建抗先验子空间 P,从数学上强制正交性约束以确保对先验的抑制完全不会干扰真实的视觉接地信息 ;最后,在模型输出层将隐藏状态 h正交分解为视觉证据、冲突先验与残差不确定性三个分量,并根据视觉确定性(VCR)与先验冲突(PCR)比率动态校准编辑强度,通过最小范数闭式解对冲突信号进行强度自适应的收缩,从而在维持生成流利度的同时,实现精准且稳健的去幻觉干预 。
**

实验结果 为了验证 HulluEdit 的有效性,研究团队在 LLaVA-1.5、MiniGPT-4、mPLUG-Owl2 以及 Qwen-VL 等多种代表性多模态大模型上进行了全面评估 。实验结果显示,在 POPE 和 CHAIR 等核心幻觉评测基准中,HulluEdit 在所有评估设置下均取得了最优的准确率与 F1 分数,特别是在语言先验干扰最严重的对抗性(Adversarial)测试中表现出极强的稳健性,证明了其在复杂冲突场景下对视觉证据的强大保护能力 。此外,在 MME 综合能力评估中,该方法在显著增强物体存在性、位置及颜色感知能力的同时,有效维持了模型的通用视觉理解水平 。值得注意的是,得益于高效的单次前向传播设计,在解码吞吐量(TPS)上大幅超越了 OPERA 和 HALC 等近期先进方法,在兼顾效率的同时显著提升了幻觉抑制。
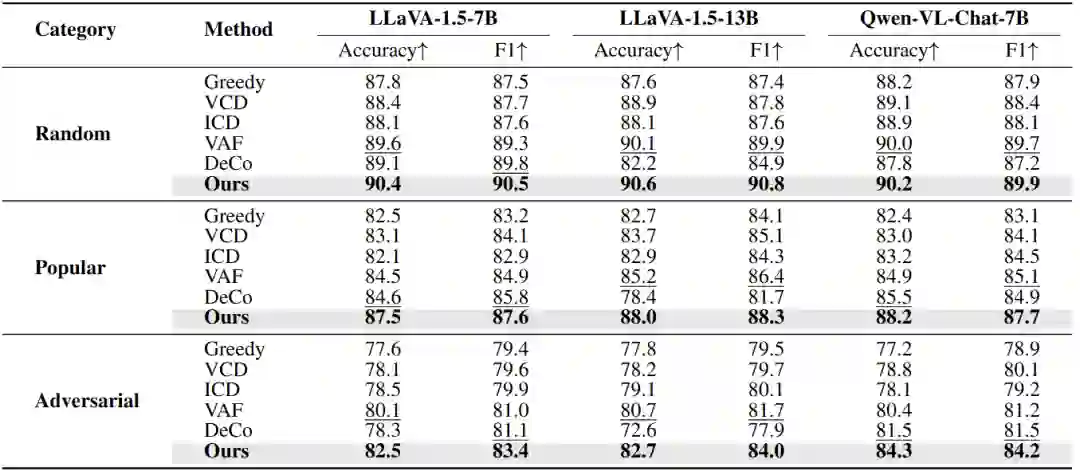
表 1: 不同方法在POPE任务上的性能对比
会议介绍

IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR)是由 IEEE 计算机学会与计算机视觉基金会(CVF)联合主办的国际顶级学术会议,主要面向计算机视觉、模式识别、图像处理、多模态学习及相关人工智能应用等研究方向。该会议被中国计算机学会(CCF)推荐为A 类会议,在全球计算机视觉领域拥有举足轻重的学术地位。CVPR 高度重视论文在方法创新、技术突破与实验验证上的综合质量,是计算机视觉与人工智能交叉领域极具代表性的顶尖学术会议之一。