
导读
机器学习通常把数据看作向量、图像、序列或表格,但越来越多真实数据本身就是“形状”:细胞轮廓、核糖体结构、脑区表面、牙齿形态、骨骼化石、人体姿态、三维网格和点云。它们的差异往往不体现在单个数值上,而体现在弯曲、突起、拓扑、配准关系、局部几何和跨样本变形轨迹中。 综述论文《Learning the Geometry of Data: A Mathematical Review of Shape Space Analysis》系统梳理了“形状空间分析”这一交叉方向。它将数学、统计学、几何处理和机器学习连接起来,讨论如何把一组几何对象看作高维空间中的点,如何定义合适的表示、距离、均值、波动、轨迹和统计检验,以及如何在有限标注数据下进行分类、聚类和生物形态发现。 这篇综述的核心观点是:形状数据不能简单塞进通用机器学习流程。对形状而言,表示方式、配准方式和距离度量会直接决定后续结论。若忽略几何结构,模型可能看起来能分类,却无法解释真正的形态变化;若构建了合适的形状空间,则可以从微观细胞动态到宏观灵长类牙齿演化中发现跨尺度规律。

论文:Learning the Geometry of Data: A Mathematical Review of Shape Space Analysis作者:Gary P. T. Choi、Khanh Dao Duc、Shira Faigenbaum-Golovin、Karen Habermann、Emmanuel Hartman、Christoph von Tycowicz、Chi Zhang、Wenjun Zhao、Felix Zhou类别:Statistics Theory;Machine Learning篇幅:79页,10图,8表项目仓库:https://github.com/shirafaigen/ShapeSpaceSurvey.git论文地址:https://arxiv.org/abs/2606.17022
1 Introduction / 引言
为什么要研究形状空间
形状空间的基本思想,是把一组形状对象放进一个能够反映几何差异的空间中研究。每个对象可以是图像、点云、曲面、体数据、网格、图结构或生物结构。研究者关心的不是单个形状的曲率或面积,而是整个集合中的差异、相似性、群体结构、演化趋势和动态轨迹。 论文用核糖体作为开场例子说明“形态即功能”。不同生命域中的核糖体在体积和复杂度上呈现系统性变化,这些几何变化与翻译精确性、共翻译折叠、伴侣蛋白结合等功能有关。若仅分析单个结构,很难发现整体规律;若把它们放入形状空间,就能观察到结构复杂度与生物功能之间的组织方式。
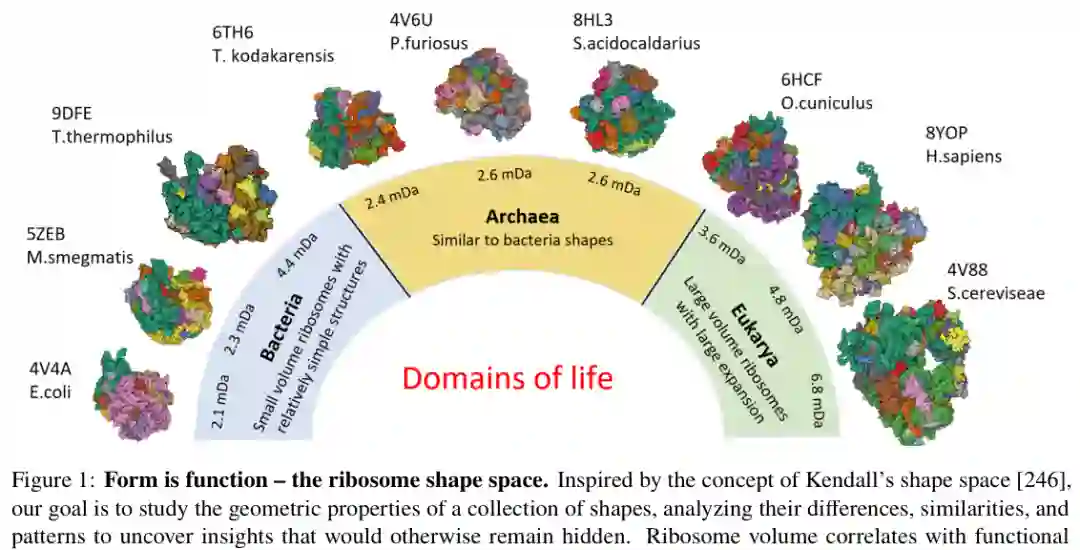
综述定位
论文强调,形状空间分析不是传统计算机视觉、图形学或图像处理的简单延伸。很多生物和医学数据的差异极其细微,样本量又有限,通用深度学习很容易受表示、配准和噪声影响。作者因此主张:机器学习应建立在几何感知的表示和统计框架之上,而不是跳过数学结构直接训练模型。 全文按一个分析流程组织:先讨论形状如何被采集和存储,再讨论形状如何表示;随后进入预处理、对应、配准、参数化、特征描述、距离度量、动态分析和统计推断;接着讨论机器学习如何发现形态模式;最后通过细胞形态和灵长类牙齿两个案例展示完整流程,并整理数据集、软件工具和未来问题。
2 Shape in Data / 数据中的形状
采集技术
形状数据首先来自采集。论文把采集方式分为接触式、非接触式和从零设计。接触式方法包括切片、组织学、聚焦离子束扫描电镜等,也包括用机械臂探测三维点的非破坏式测量。非接触方法则包括计算机断层扫描、核磁共振、超声、雷达、激光雷达、结构光、摄影测量、显微成像等。设计类数据则来自方程、CAD、Blender、Unity等显式构造过程。 采集方式通常决定后续数据格式。CT、MRI 和显微镜产生规则网格或体数据;激光扫描和结构光得到点云;三维重建得到网格;蛋白质结构可能表现为图或高阶复形。每一种格式都携带不同的计算代价、几何保真度和可扩展性。
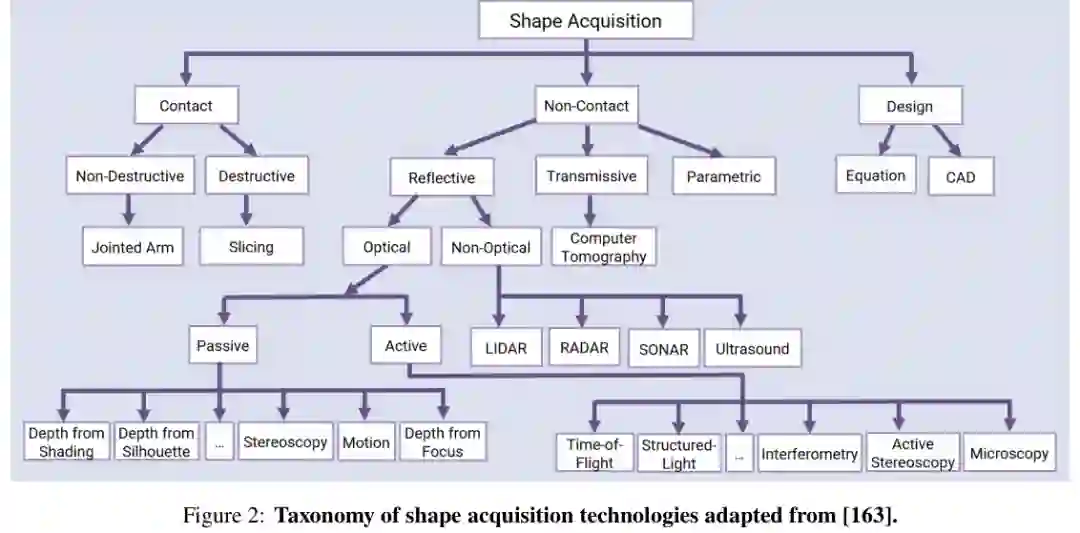
数据格式
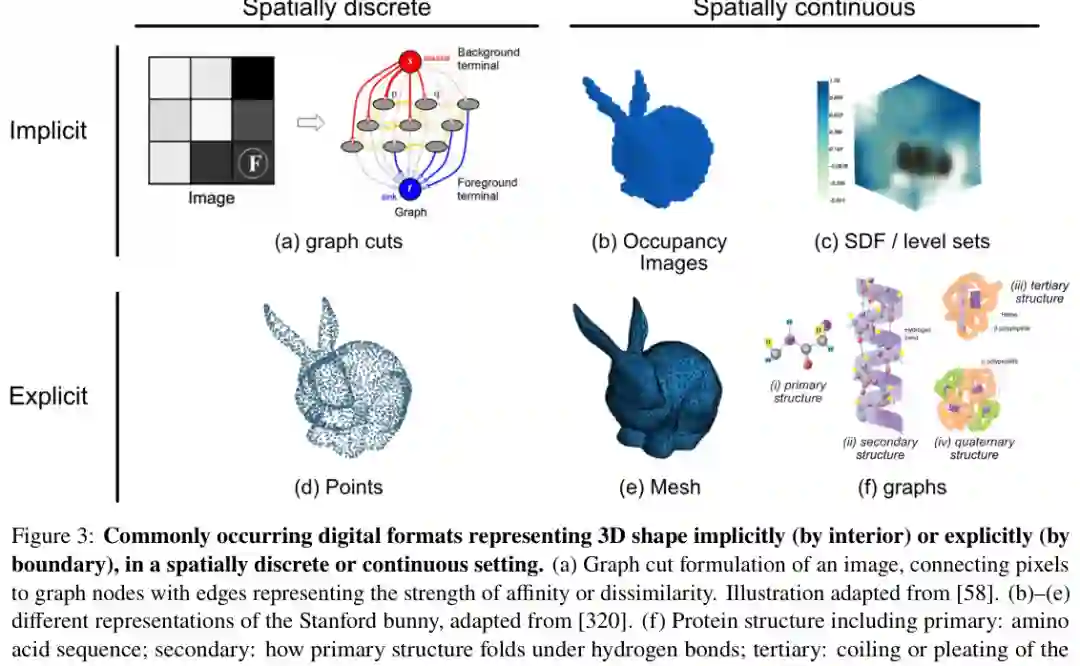
论文把形状表示分为隐式和显式两类。隐式表示通过空间内部和外部来定义形状,例如图割、占据图、符号距离函数和水平集。它们容易推广到高维和复杂拓扑,也适合分割、重建和体数据处理。 显式表示则直接描述边界或几何元素,例如点云、网格、图结构、蛋白质一级到四级结构等。显式表示更容易建立对应关系,也更直观地支持变形、插值和局部几何比较,但通常更依赖拓扑质量、连通关系和网格修复。
3 Shape Space Overview / 形状空间概览
三类表示范式
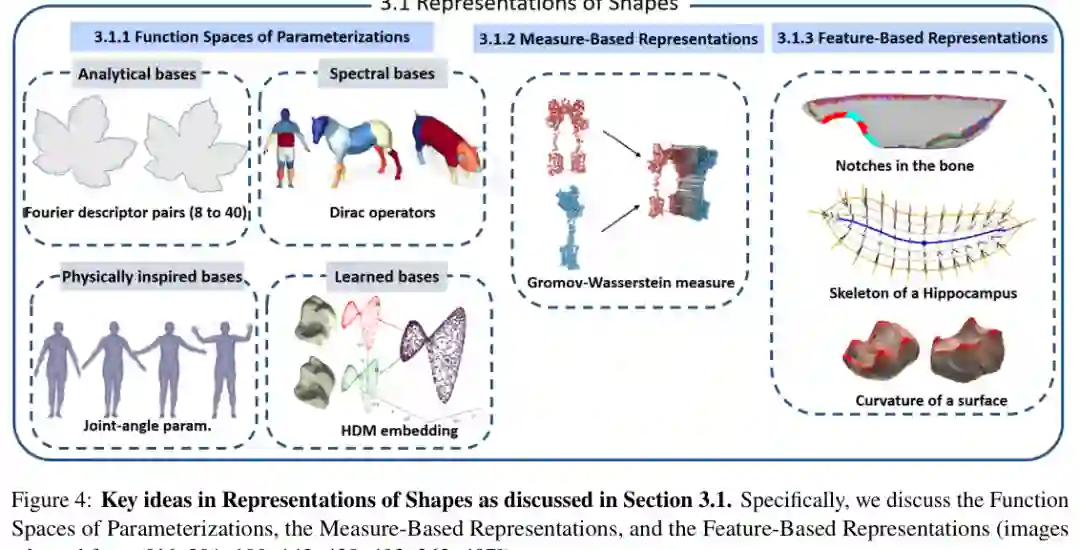
形状空间的第一步是决定“一个形状到底是什么”。论文总结了三类主要表示。 第一类是参数化函数空间。形状被看作从模板流形到欧氏空间的映射,研究重点是如何剔除平移、旋转、尺度和重新参数化等不相关变化。Kendall形状空间、曲线和曲面的商空间,以及基于傅里叶、谱基和物理启发基的表示都属于这一类。 第二类是测度表示。点云、曲线、曲面和体数据可以被看作空间中的概率或质量分布,用高斯测度、随机测度、currents、varifolds、最优传输或核方法进行比较。这类方法对拓扑变化、噪声和部分观测更灵活。 第三类是特征表示。形状被压缩为几何、外观或关系描述符,如曲率、骨架、拓扑特征、统计量、深度嵌入等。它不一定保留精确空间对应,但适合聚类、分类、检索、低维嵌入和多模态整合。
4 Methods / 方法
预处理与对应
形状采集后通常不能直接分析。点云可能有噪声,网格可能有洞,表面可能不满足目标算法的拓扑假设,考古碎片和三维场景还可能只有局部观测。因此,平滑、补洞、表面重建、拓扑简化、shrinkwrapping、全局坐标重建等步骤常常是必要前提。 随后是形状对应问题。对应包括对齐、地标点和配准。对齐用于移除平移、旋转和尺度等外在差异;地标点用于建立解剖或结构上有意义的参照;配准则通过刚性或非刚性变换,把一个形状映射到另一个形状或共同模板上。
参数化、特征与距离
参数化的目标,是为表面或体数据建立一致坐标系统。它可以把复杂曲面映射到平面、球面、带孔区域、周期域或体模板上,使得不同样本之间可以按同一坐标比较。医学中的脑模板、细胞表面展开、牙齿曲面比较,都依赖这类思想。 特征描述符则回答另一个问题:我们要保留形状的哪些信息。全局统计量如面积、体积、偏心率解释性强;局部统计量如曲率、粗糙度适合捕捉微小突起;拓扑特征能描述孔洞、连通性和持久同调;分解方法如傅里叶、Zernike、球谐和PCA把形状投影到基函数;数据学习描述符则通过自编码器、图神经网络、对比学习和生成模型学习嵌入。 距离度量是形状空间的核心。论文将距离大体分为地标点距离、表示距离、点云距离和数据流形距离。地标点距离计算快、解释清楚,但依赖准确地标;表示距离利用曲线、曲面或体的完整结构,能捕捉连续变形;点云距离常用最优传输等无对应方法;流形距离则利用整个样本集合推断潜在几何结构。
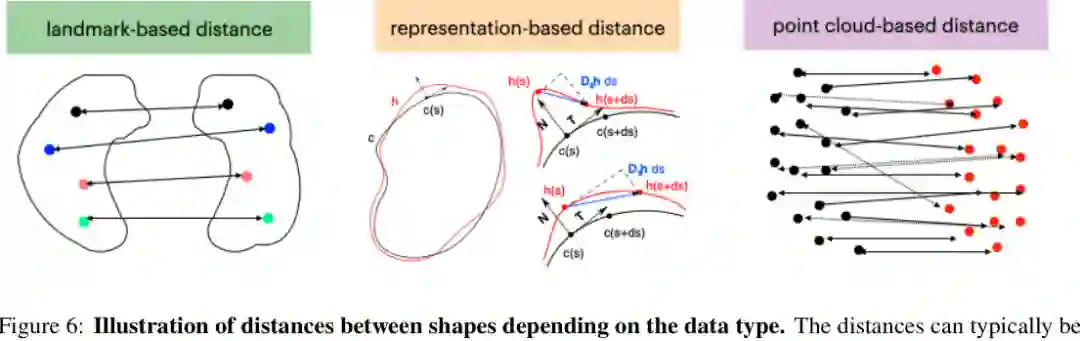
动态、均值与波动
形状空间不仅用于静态比较,也用于研究随时间、发育、疾病或演化变化的轨迹。若形状落在非线性流形上,普通欧氏均值和线性回归可能失真。论文因此讨论了流形学习、时间不变坐标、测地线、样条回归、Fréchet均值和形状波动等工具,用于描述动态变化和统计不确定性。 这部分的实践含义很直接:如果研究对象是心脏瓣膜随心动周期变化、细胞表面突起随信号传播变化、牙齿形态随演化压力变化,那么模型必须尊重形状空间的曲率、距离和对应结构。
5 Machine Learning to Uncover Morphological Patterns in Shape Space / 用机器学习发现形态模式
机器学习之前的评估
论文对“直接上机器学习”保持谨慎。形状数据常常样本少、标注稀缺、采集渠道不同、噪声和偏差复杂。如果训练集与测试集泄漏、类别不平衡、验证方式不合适,模型结果可能被严重高估。因此,作者强调必须结合真实或模拟测试场景,报告误差、置信区间、统计显著性和任务相关指标。
分类、聚类与假设检验
形状空间中的机器学习任务包括分类、聚类、检索、疾病表型识别、物种识别、生态关系推断和演化模式发现。算法本身可以是随机森林、SVM、K-means、层次聚类、图神经网络或深度嵌入,但关键并不是算法名称,而是输入表示和距离是否表达了正确几何。 论文用解剖表面的聚类结果说明,连续Procrustes距离、扩散映射和水平扩散距离会产生完全不同的结构。当几何信息被合适地嵌入到低维空间后,原本模糊的群体结构会变得清晰。这说明形状学习的成败常常发生在算法之前:表示和度量已经决定了可见模式。
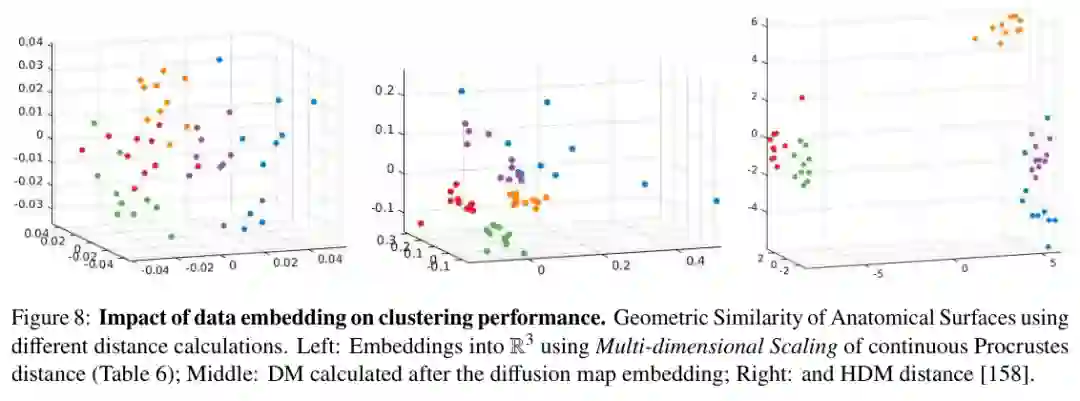
假设检验则用于回答“观察到的形态差异是否超过随机波动”。在高维小样本场景中,形状分析常用置换检验、bootstrap、非参数能量检验、拓扑数据分析和流形上的统计推断。论文强调,统计问题必须先被翻译成明确的几何问题:比较的是全局形状、局部结构、拓扑事件、轨迹差异,还是群体均值。
6 Practical Guidance to Shape Space Analysis, through the Lens of Two Examples / 两个案例中的实践指南
细胞形态与信号动态
第一个案例来自微观尺度的细胞形态。细胞形状长期被认为是信号通路和功能状态的结果,但新显微成像和生物传感器表明,形状本身也可能驱动信号。例如转移性黑色素瘤细胞会形成动态半球形突起,这些突起不仅帮助迁移,也能激活生存相关信号。 论文介绍了u-Unwrap3D工作流:先从三维细胞表面构建一个平滑参考曲面,再通过球面、二维UV图和三维拓扑表面等多种表示之间的双向映射,追踪突起、曲率和信号流。该案例说明,复杂形状常常不能由单一表示解决,而需要多个表示协同工作。
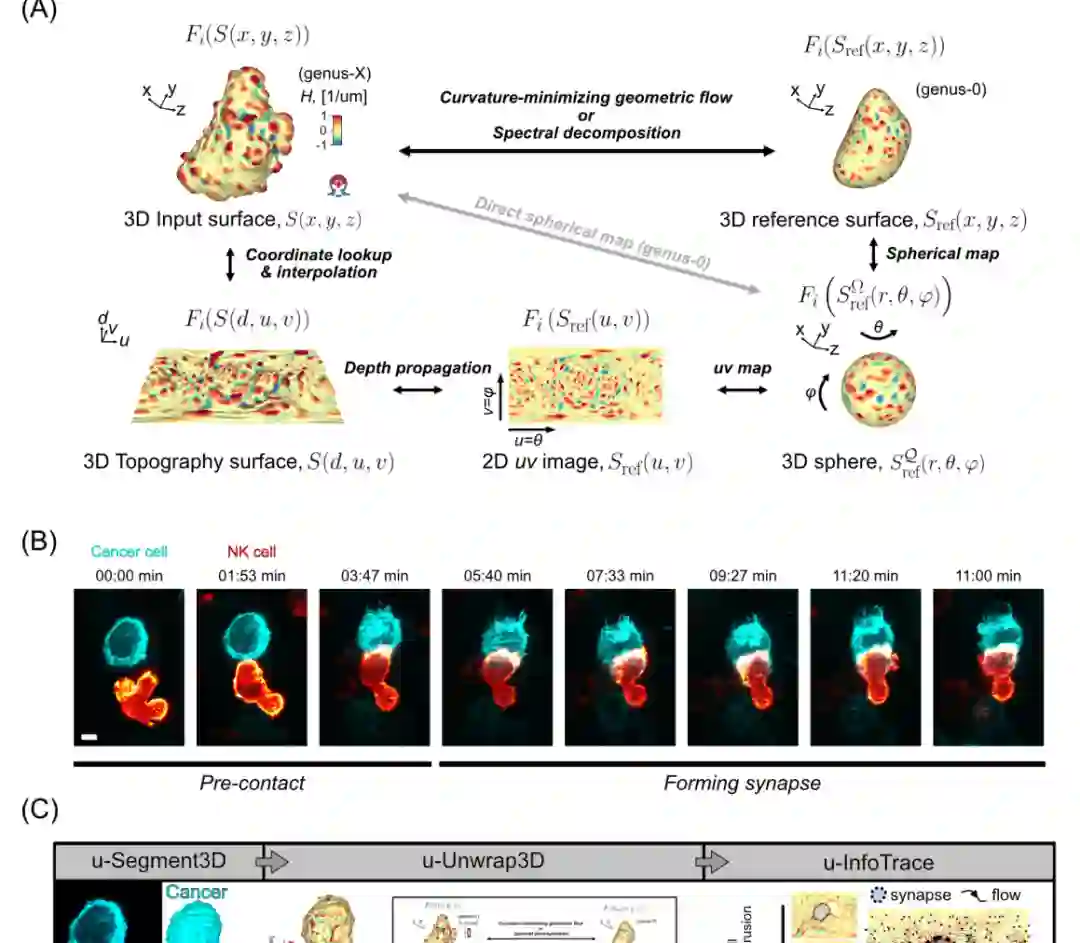
灵长类牙齿演化
第二个案例来自宏观尺度的灵长类牙齿形态。研究流程从高分辨率CT扫描开始,经过曲面重建、网格清理、配准、自动地标点检测、连续Procrustes距离和水平扩散映射,最终在低维空间中比较不同物种牙齿表面。 该案例展示了形状空间如何服务演化问题。不同饮食类型的灵长类在牙齿形状空间中形成相对清晰的群组:食叶类和食果类分别聚集,食虫类则远离这些群体。这里,形状空间不是可视化装饰,而是把物理标本、几何曲面和演化假设连接起来的分析框架。
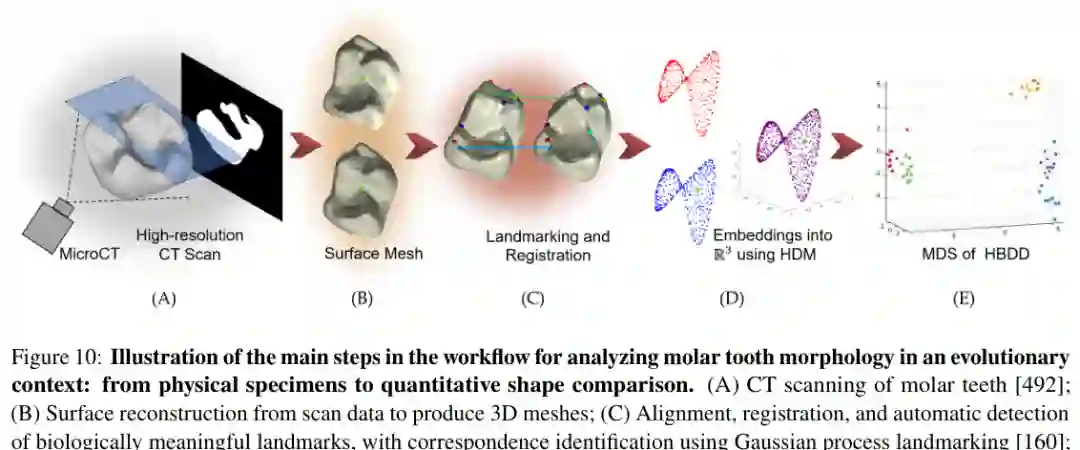
7 Shape Space Datasets / 形状空间数据集
基准与真实数据
论文整理了多类形状空间数据集。标准基准包括MNIST、EMNIST、CMU PIE、Stanford 3D扫描库、Princeton Shape Benchmark、ShapeNet、ABC等。它们适合算法评估,但往往不能完全代表真实科学数据的复杂性。 真实世界数据更能体现形状空间的挑战。论文列举了细胞轮廓、二维细胞图像、核糖体原子结构、Cryo-EM密度图、三维细胞图像、神经元重建、脑影像、医学三维形状、骨骼和牙齿、果蝇翅膀、叶片、云图、人体网格、石器和癌症影像等数据。它们跨越微观到宏观,也跨越生物、医学、人类学、考古和图形学。
8 Software Tools / 软件工具
工具生态
形状空间方法分散在数学、统计、计算几何、医学影像、图形学和机器学习社区中。论文没有在正文穷尽所有工具,而是提供了持续更新的GitHub仓库,收集相关方法、代码和参考文献。 这也反映出该领域当前的重要状态:工具很多,但还缺少统一的接口、术语和评估协议。研究者往往需要根据数据类型、科学问题、拓扑条件和计算资源组合自己的分析管线,而不是期待一个通用开箱方案。
9 Discussion and Future Research Direction / 讨论与未来方向
八个开放问题
论文最后提出多个关键方向。 第一,AI革命会如何改变形状空间分析。几何深度学习、表示学习和生成模型正在扩大可处理问题范围,但如何把几何约束、物理先验和统计解释纳入深度系统仍未解决。 第二,是否存在开箱即用方案。作者的判断偏谨慎:形状数据的来源、拓扑、尺度、噪声和采样差异很大,算法很少能不加调整直接使用。更重要的问题是如何设计完整管线,而不是单点选择某个模型。 第三,地标点是否仍然必要。地标点解释性强,但对局部新性状、非同源结构和连续变形并不总是合适。未来需要地标点、局部特征、拓扑描述和无对应距离的互补框架。 第四,配准仍未真正解决。大变形、拓扑变化、噪声、缺失数据和弱对应都会让配准困难。如何在无初始对应和部分损坏形状下高效配准,是基础挑战。 第五,评估协议缺失。形状空间分析仍缺少可靠GT数据、标准化指标、鲁棒性测试和跨任务基准。没有这些,方法比较很难客观。 第六,多模态和混合表示。二维图像、点云、曲面网格、体数据和图结构之间如何统一,是未来大规模几何数据分析的关键。 第七,多尺度和层级表示。蛋白质结构、细胞形态、组织环境和宏观器官并非孤立存在,未来需要跨尺度整合表示。 第八,模型驱动学习。数据驱动模型应吸收形状空间知识,包括不变性、物理约束、生物先验和可解释统计结构,以提高泛化性和数据效率。
总结
这篇综述把形状空间分析描绘为一个从采集、表示、预处理、配准、度量、统计到机器学习的完整体系。它的价值在于统一语言:不同领域看似在研究细胞、牙齿、核糖体、脑区或三维模型,实际上面对的是同一类问题,即如何在复杂、非线性、未对齐的几何集合中发现结构。 对机器学习研究者而言,本文提醒我们:当数据“有形状”时,几何不是前处理细节,而是建模对象本身。真正有效的学习系统,需要先理解形状如何被表示、如何比较、如何对齐,以及什么样的距离才对应科学问题。 论文地址:https://arxiv.org/abs/2606.17022
