
导读
当大模型从聊天助手变成能够规划、调用工具、保存记忆并持续行动的智能体,可信性问题也随之发生变化。传统模型的一次错误回答,通常停留在文本层面;智能体的一次错误判断,却可能沿着“感知—规划—行动—反思—学习”的长链条逐步放大,最终触发真实工具、修改外部系统、泄露数据,甚至把错误经验写回记忆。 综述论文《Towards Trustworthy Agentic AI: A Comprehensive Survey of Safety, Robustness, Privacy, and System Security》围绕可信智能体 AI 展开系统梳理。作者没有把所有可信议题平均铺开,而是聚焦高风险部署中最紧迫的两条主线:安全与鲁棒性,以及隐私与系统安全。论文进一步把风险和防护措施映射到智能体生命周期,统一整理评估指标、基准、发布门槛和真实应用案例。 本文严格按照原论文结构展开,重点回答四个问题:智能体为何产生不同于普通 LLM 的风险;风险会在哪个生命周期阶段出现;训练前、训练中、运行时和事故后应如何建立保证机制;以及如何用过程指标而不只是最终成功率来决定系统能否上线。论文作者:Jinhu Qi、Muzhi Li、Jiahong Liu、Yuqin Shu、Dianzhi Yu、Shicheng Ma、Wenqian Cui、Yiyang Zhao、Yiyi Chen、Ruoxi Jiang、Irwin King、Zenglin Xu 等论文地址:https://arxiv.org/abs/2605.23989
1 Introduction / 引言
研究动机
智能体 AI 通常由大语言模型、规划器、工具接口、记忆和环境反馈共同构成。它能够将高层目标拆分为多步任务,查询外部信息,调用代码、浏览器、数据库或企业 API,并根据结果继续调整计划。这种自主性提高了系统能力,也把模型从“内容生成器”变成了数字基础设施中的行动节点。 风险因此不再只来自最终回答。一个被污染的网页可能通过间接提示注入影响感知;规划器可能把模糊目标转化为危险子任务;工具层可能以过高权限执行错误操作;反思模块可能对失败作出错误归因;长期记忆则可能将一次攻击固化为后续行为规则。多步轨迹中的早期偏差会累积,局部看似合理的动作组合起来却可能造成严重后果。 论文强调,智能体可信性不能完全沿用聊天模型的评估方式。仅检查有害输出率或单轮准确率,无法覆盖工具滥用、凭证泄露、记忆投毒、跨智能体传播、不可逆行动以及长周期错误累积。评估对象必须从“输出文本”扩展到完整轨迹、内部状态和外部副作用。
研究范围
作者将可信智能体的核心问题集中为两个维度。
- 安全与鲁棒性:系统在不确定性、扰动、对抗输入和分布变化下,是否能够避免对个人、组织和环境造成非预期伤害。
- 隐私与系统安全:系统能否保护数据、凭证、工具和执行环境的机密性、完整性与可用性,并抵抗提示注入、越权访问、代码执行和数据外泄。
价值对齐、透明性、公平性与问责性并未被忽略,但主要作为相关背景和治理条件出现,而非与上述两条主线并列展开。作者也明确指出,这是一份面向当前高风险部署的聚焦型综述,并非对所有风险和方法的穷尽式枚举。
主要贡献
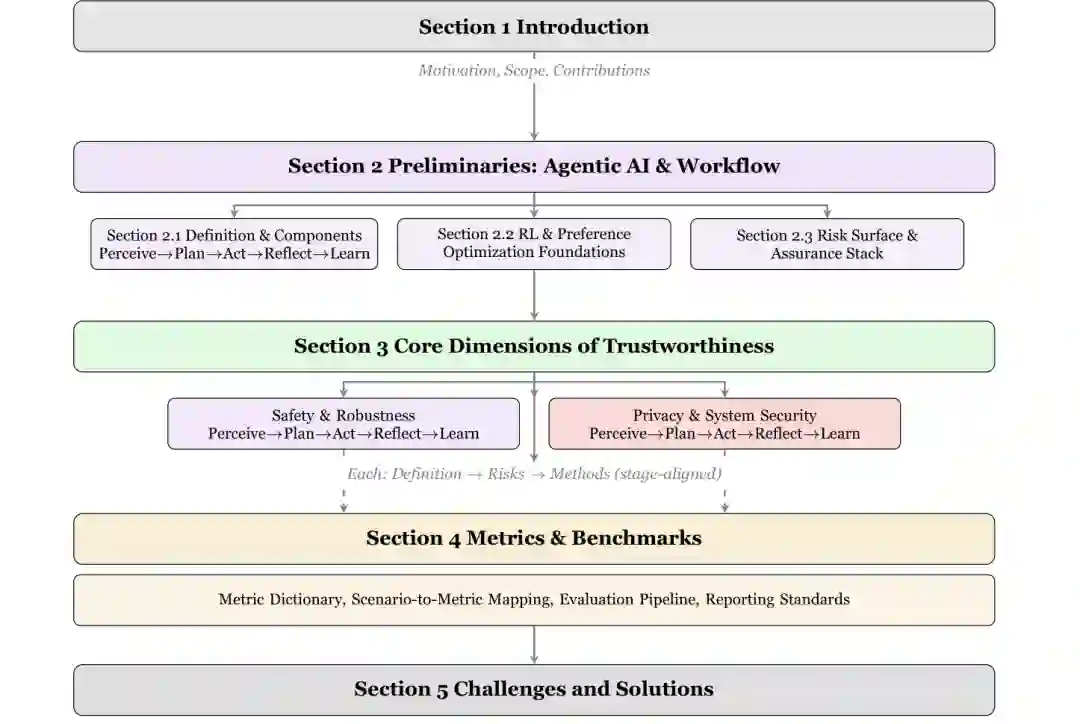
论文的贡献可以概括为三点。第一,以智能体工作流为主轴,将风险定位到感知、规划、行动、反思、学习、多智能体协作和长周期运行阶段。第二,按“定义—风险—方法”的统一方式整理安全、鲁棒、隐私和系统安全研究。第三,建立指标与基准中心,将场景、威胁模型、过程信号和发布门槛关联起来,使综述不仅描述研究版图,也提供工程化评估路线。
2 Preliminaries / 预备知识
智能体的定义与组成
论文将智能体 AI 定义为:具有持续目标,能够感知环境、进行多步规划、通过工具或执行器影响外部系统,并在明确的人类监督、隐私安全政策和运行约束下反思结果、调整内部状态的 AI 系统。 其典型组成包括目标与约束、感知模块、规划与推理模块、行动或工具层、情景记忆与语义记忆、世界模型,以及反思和学习模块。人类管理员提供目标、权限、预算和监督,环境则返回状态、结果和奖励。 与单轮 LLM 相比,智能体的关键差异并不只是“多调用几次模型”,而是拥有持久状态、反馈闭环和现实行动能力。它会主动改变未来可见的信息,也可能更新自身记忆和策略。可信性因此必须覆盖状态转移和行为链条。
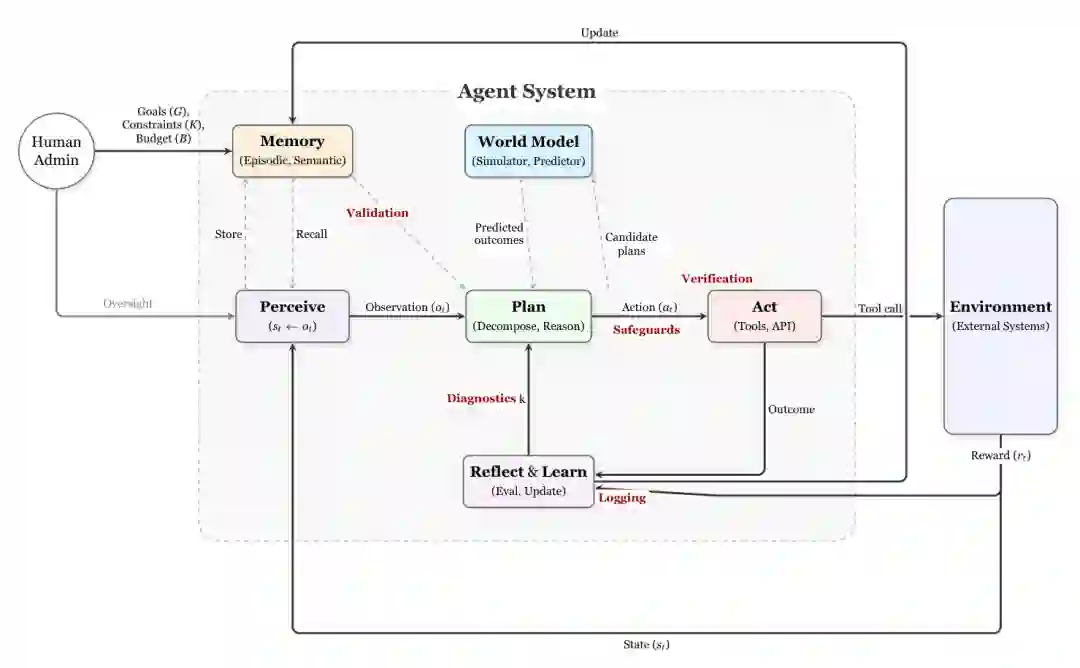
强化学习与偏好优化基础
智能体决策可表示为 MDP 或 POMDP:系统根据当前观测和内部状态选择动作,环境返回新状态与奖励。在真实任务中,观测往往不完整,奖励稀疏且存在延迟,系统需要依赖记忆推断隐藏状态。这些条件使信用分配、探索和策略稳定性更加困难。 强化学习、模仿学习、离线强化学习和偏好优化都会影响可信性。纯粹最大化任务奖励可能诱发奖励投机;离线数据可能包含偏差和危险操作;人类偏好数据也可能不一致。安全强化学习通常把风险写入约束,例如限制累计成本、使用条件风险价值衡量尾部损失,或通过盾牌机制阻止不安全动作。 作者指出,偏好对齐并不等同于运行安全。模型即使能够拒绝明显有害请求,也可能在长轨迹中被间接提示注入,或经由合法工具组合完成危险操作。因此,训练层对齐需要与权限控制和运行时验证配合。
风险面与保证栈
论文提出四层保证栈。
- 事前保证:威胁建模、数据治理、红队测试、模拟验证和部署域定义。
- 训练时保证:约束强化学习、偏好优化、鲁棒训练以及安全策略改进。
- 运行时保证:动作验证、沙箱、最小权限、异常检测、人类审批和分阶段发布。
- 事后保证:结构化遥测、可复现轨迹、事故分析、补丁验证和安全回归测试。
这四层不能相互替代。训练阶段无法枚举所有现实攻击,运行时规则也无法修复根本性的目标错位;可信系统需要纵深防御。
3 Core Dimensions of Trustworthiness / 可信性的核心维度
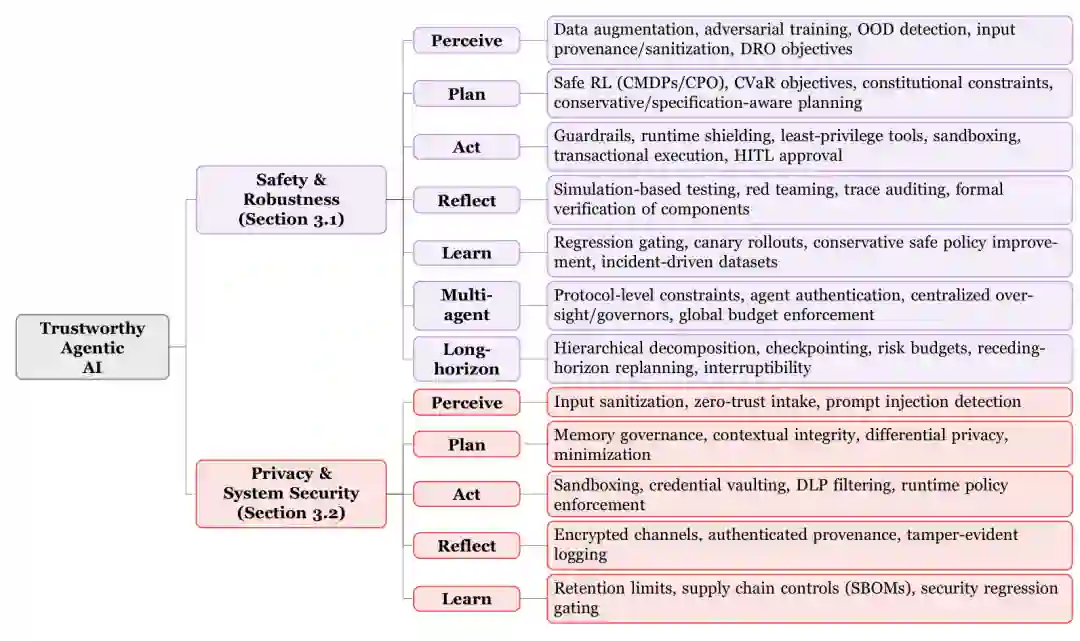
安全与鲁棒性
安全关注系统是否避免造成非预期伤害,鲁棒性关注系统在噪声、对抗扰动和分布偏移下能否维持稳定行为。对智能体而言,两者相互依赖:感知错误可能导致危险计划,计划错误可能触发不可逆工具操作,反思错误又可能使问题进入长期记忆。 在感知阶段,风险包括输入污染、对抗样本、传感器故障、错误检索和域外数据。方法包括数据增强、对抗训练、来源验证、输入净化和分布外检测。在规划阶段,系统可能出现目标误解、奖励投机、不安全探索和约束遗漏,可使用约束 MDP、保守规划、风险敏感目标与宪法规则。 行动阶段最接近真实后果。防护重点包括工具白名单、最小权限、参数校验、沙箱、事务式执行和高风险操作的人类审批。事务式执行尤其重要:系统应先生成可检查计划,在验证通过后提交,并为可逆动作保留回滚机制。 反思与学习阶段会把短期错误转化为长期风险。系统可能根据偶然结果形成错误规律,或被攻击者通过持续交互污染记忆和策略。应通过轨迹审计、模拟测试、记忆来源标注、回归门控和金丝雀发布限制错误更新。 多智能体环境还会产生欺骗、串谋、错误级联和责任分散。长周期任务则面临误差累积、目标漂移和监督衰减。协议级约束、身份认证、全局预算、检查点和可中断性是关键机制。
隐私与系统安全
隐私关注个人和敏感信息能否被合理收集、使用、保存和删除;系统安全则关注数据、工具和执行环境能否抵抗恶意攻击。智能体可访问邮件、文档、浏览器历史、数据库和凭证,因此比普通聊天模型拥有更大的攻击面。 在感知阶段,间接提示注入是代表性威胁。攻击指令可隐藏于网页、邮件、文档或工具返回值中,使系统混淆“数据”和“命令”。防御需要零信任输入、内容与指令分离、来源认证、提示注入检测,以及对不可信内容降低权限。 规划与记忆阶段的风险包括上下文泄露、跨任务数据混用、敏感信息长期保存和记忆投毒。缓解方法包括数据最小化、目的限制、差分隐私、记忆分区、保留期限和删除机制。论文用 ((\varepsilon,\delta))-差分隐私描述机制在相邻数据集上的输出稳定性,但也指出形式化隐私不能独自解决权限和执行安全。 行动阶段的主要威胁是凭证盗取、越权工具调用、代码执行和数据外传。工程措施包括凭证保险库、短期令牌、最小权限、数据防泄漏过滤、网络出口控制和运行策略执行。日志本身也可能包含秘密,因此需要加密通道、认证来源和防篡改审计。 学习阶段还涉及训练数据保留、模型供应链和依赖组件风险。组织应维护软件物料清单,审查模型、插件和工具来源,并将安全回归测试作为每次升级的发布门槛。
4 Consolidated Metrics and Benchmarks / 统一度量与基准
从结果评估转向过程评估
智能体评估不能只看任务是否完成。同样的成功结果,可能来自安全路径,也可能伴随越权访问、敏感信息暴露或违反政策。论文建议同时记录结果指标与过程指标。 结果指标包括任务成功率、伤害事件率、对抗攻击成功率、隐私泄露率和违规操作率。过程指标包括轨迹完整性、约束违反次数、工具调用合法性、敏感数据暴露、人工接管频率、恢复时间和日志覆盖率。还要区分步骤级与轨迹级评估:单步合法并不代表动作序列整体安全。 长周期任务应测量错误随步骤增长的累积趋势、恢复能力和延迟后果;多智能体任务则要评估个体归因、协议遵循、协作涌现和共享责任。使用 LLM 裁判时,需要报告裁判一致性、校准误差,并以人工审查和对抗测试验证裁判可靠性。
场景到指标的映射
评估应从场景和威胁模型出发,而不是机械运行一个通用榜单。医疗诊断、自动驾驶和企业助手具有不同的伤害半径、可逆性和监管要求,因此应设置不同的发布阈值。 作者建议先明确运行设计域:允许处理哪些输入、调用哪些工具、作用于哪些用户和环境;随后列出高风险失败模式,为每类风险选择指标与基准,最后定义阻断发布的硬阈值。平均任务分数不能抵消严重安全事件,尾部风险必须独立报告。
评估流水线
论文给出从离线到生产的七阶段路线:离线回归重放已知失败;在模拟环境测试罕见事件;在沙箱中执行工具任务;开展自动化与人工红队;以只读影子模式接入真实流量;小范围金丝雀发布;最后持续生产监控。 每一阶段都应保留最小可审计轨迹,包括输入来源、模型与策略版本、计划、工具参数、权限决策、环境反馈、记忆更新和人工干预。报告还应提供代表性失败轨迹、根因分析和可复现实验包,而不只是汇总分数。 评估面临的开放问题包括裁判脆弱、基准饱和、模拟到现实差距、长轨迹组合爆炸、多智能体归因困难,以及不可能穷尽所有攻击方式。因此,可信性不是一次认证,而是持续回归和监控过程。
5 Real-World Applications in High-Risk Domains / 高风险领域的实际应用
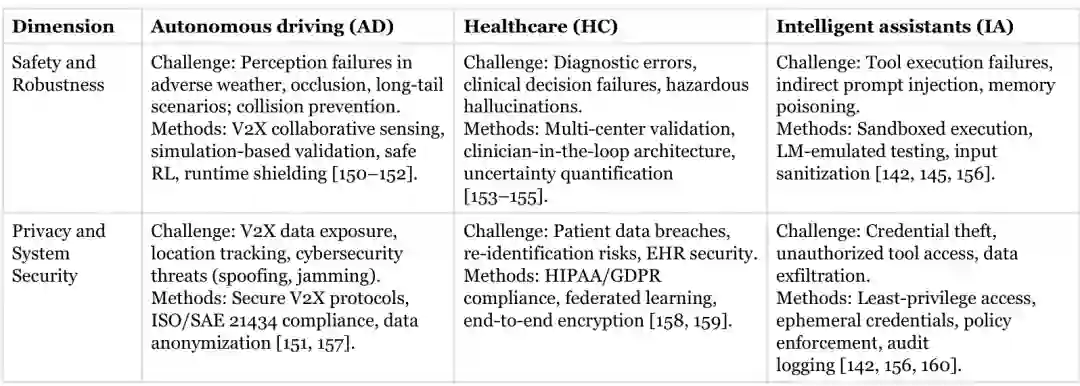
自动驾驶
自动驾驶中的智能体风险集中在恶劣天气、遮挡、长尾场景和多主体交互。安全措施包括多传感器与车路协同感知、仿真验证、安全强化学习和运行时屏蔽。隐私与系统安全问题则包括位置轨迹泄露、V2X 欺骗、干扰和车辆控制接口攻击,需要安全通信、身份认证、数据匿名化和汽车网络安全标准。
医疗健康
医疗智能体可能参与诊断、临床决策、病历整理和工作流协调。风险不仅是幻觉,还包括错误升级路径、忽略不确定性和不恰当自动执行。多中心验证、临床人员在环、置信度与不确定性估计、持续监测是基本要求。隐私方面应结合访问控制、联邦学习、端到端加密、审计和 HIPAA、GDPR 等合规机制。
智能助手与企业系统
智能助手可访问邮件、日历、代码仓库、支付和内部知识库,容易受到间接提示注入、工具执行失败、记忆投毒和凭证盗取。防护重点是沙箱、最小权限、临时凭证、输入净化、策略执行和审计日志。 金融与交易智能体还涉及市场操纵、错误订单和合规风险;企业浏览与编码智能体则可能下载恶意依赖、泄露源代码或执行危险命令。组织应根据动作可逆性和金额、数据敏感度设置分级审批。
6 Challenges and Solutions / 挑战与解决方案
自进化与运行时验证
能够持续学习和修改记忆的智能体会不断偏离最初验证版本。未来系统需要对更新内容进行来源追踪、策略差异分析和安全回归,并在运行时检查关键不变量。变化点检测、检查点、回滚和分阶段放量应成为自进化系统的标准组件。
可信个性化
个性化需要长期用户数据,但长期记忆也会增加泄露、错误画像和操纵风险。可行方向包括本地化处理、分层同意、细粒度删除、用途限制和隐私预算。用户应能看到系统记住了什么,并能更正或撤销。
效率、解释性与问责
可信机制会带来额外计算、延迟和人工成本,系统必须平衡安全与效用。解释性也应从“生成一段理由”转向可验证的因果证据:使用了哪些观察、为何选择该工具、哪个规则阻止了动作。问责机制需要明确开发者、部署者、工具提供者和用户之间的责任边界。
长周期部署
长周期任务的核心困难包括误差累积、延迟后果、稀疏奖励、推理与行动脱节、监督扩展困难和评估不可处理。分层任务分解、风险预算、阶段检查点、后退式重规划和可中断设计可以降低风险,但仍缺少成熟统一方案。
开源智能体的安全案例
论文以 OpenClaw/Moltbook 等开放智能体生态为案例,讨论“致命三要素”:系统能够接触不可信内容,能够访问敏感数据,同时拥有对外通信或执行能力。三者结合后,隐藏指令即可诱导系统读取秘密并发送到外部。 开放插件、技能市场和智能体间通信还带来供应链风险。恶意组件可能通过依赖、配置或共享记忆扩散,且责任跨越多个主体。案例表明,提示注入不是单纯的模型问题,而是权限、数据流和系统架构问题。最有效的防线通常是隔离信任域、收窄权限、限制出口、验证工具参数并保留完整审计。
7 Conclusions / 结论
这篇综述的核心判断是:可信智能体 AI 必须被视为系统工程,而不能只被理解为模型对齐。风险贯穿感知、规划、行动、反思和学习,并随着工具权限、长期记忆、多智能体协作和长周期运行而放大。 安全与鲁棒性要求系统在不确定和对抗条件下仍避免伤害;隐私与系统安全要求数据、凭证和执行环境得到端到端保护。实现这些目标,需要将事前威胁建模、训练时约束、运行时防护和事后审计连接为完整保证栈。 对于实际团队,论文给出的最重要启示是:先定义运行设计域和高风险动作,再设计最小权限与验证机制;同时评估结果和轨迹过程,将严重风险设为不可被平均分抵消的发布门槛;上线后持续监控模型、工具、记忆与策略版本变化。可信性不是一个静态标签,而是贯穿智能体全生命周期的持续治理能力。 论文地址:https://arxiv.org/abs/2605.23989
