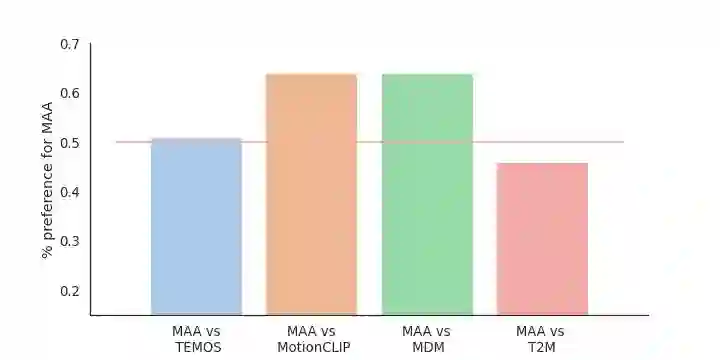
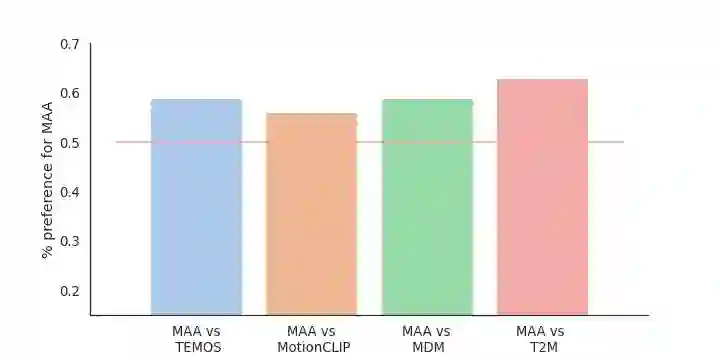
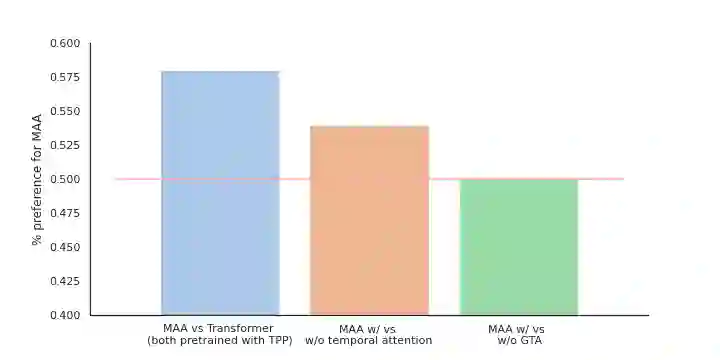
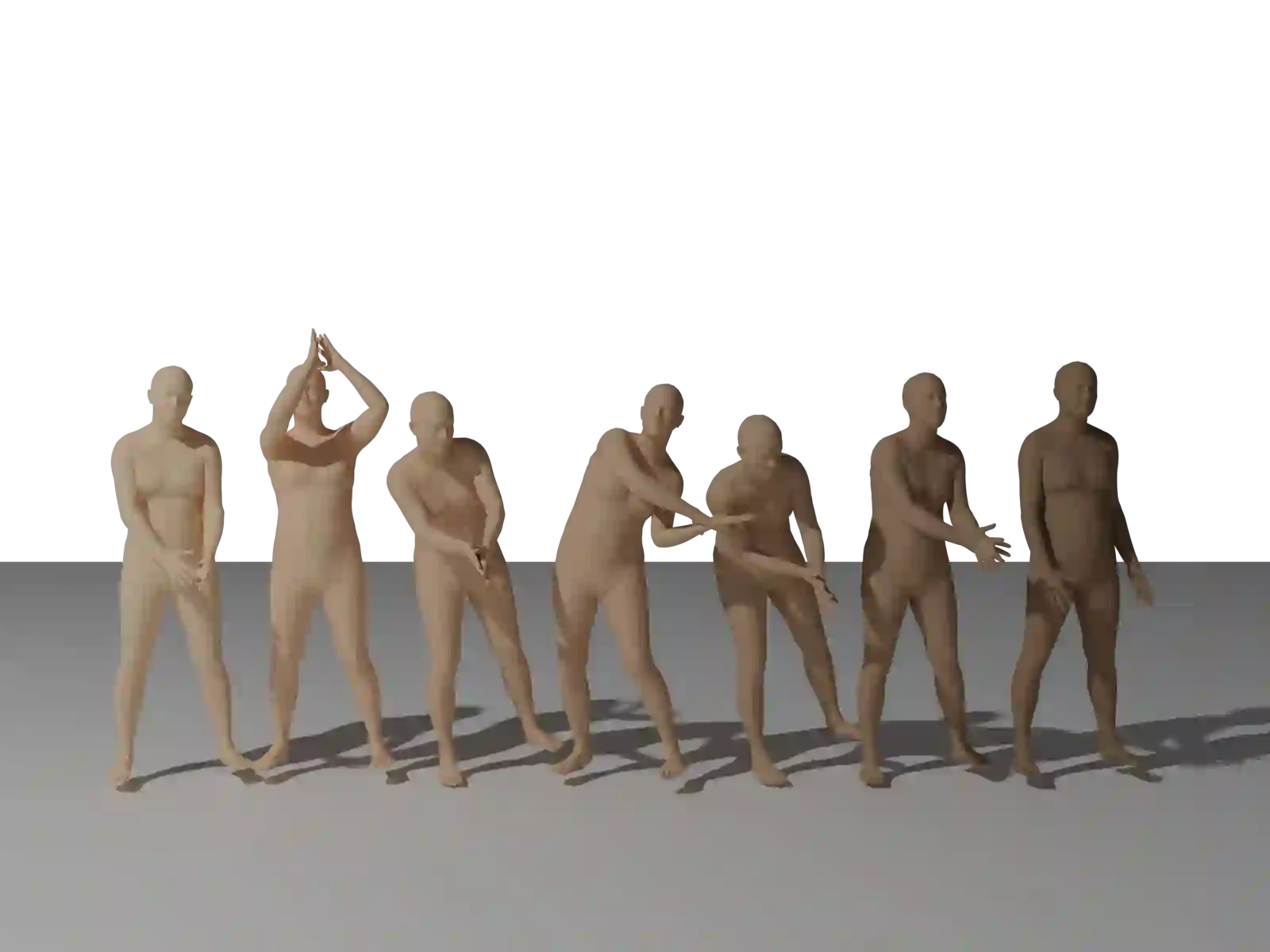Text-guided human motion generation has drawn significant interest because of its impactful applications spanning animation and robotics. Recently, application of diffusion models for motion generation has enabled improvements in the quality of generated motions. However, existing approaches are limited by their reliance on relatively small-scale motion capture data, leading to poor performance on more diverse, in-the-wild prompts. In this paper, we introduce Make-An-Animation, a text-conditioned human motion generation model which learns more diverse poses and prompts from large-scale image-text datasets, enabling significant improvement in performance over prior works. Make-An-Animation is trained in two stages. First, we train on a curated large-scale dataset of (text, static pseudo-pose) pairs extracted from image-text datasets. Second, we fine-tune on motion capture data, adding additional layers to model the temporal dimension. Unlike prior diffusion models for motion generation, Make-An-Animation uses a U-Net architecture similar to recent text-to-video generation models. Human evaluation of motion realism and alignment with input text shows that our model reaches state-of-the-art performance on text-to-motion generation.
翻译:文本引导的人体运动生成因其在动画和机器人领域的广泛应用而引起了广泛关注。近年来,扩散模型在运动生成中的应用显著提高了生成运动的质量。然而,现有方法依赖于相对小规模的动作捕捉数据,导致在更具多样性的真实世界提示上表现不佳。本文提出了Make-An-Animation——一种文本条件的人体运动生成模型,该模型通过从大规模图文数据集中学习更多样化的姿态和提示,相比先前工作实现了显著性能提升。Make-An-Animation采用两阶段训练:首先在大规模(文本、静态伪姿态)对构成的精选数据集上训练,这些数据来自图文数据集;随后在动作捕捉数据上进行微调,通过添加额外层来建模时间维度。与先前用于运动生成的扩散模型不同,Make-An-Animation采用类似于近期文本-视频生成模型的U-Net架构。基于运动真实感与文本对齐程度的人工评估表明,我们的模型在文本到运动生成任务上达到了最先进水平。