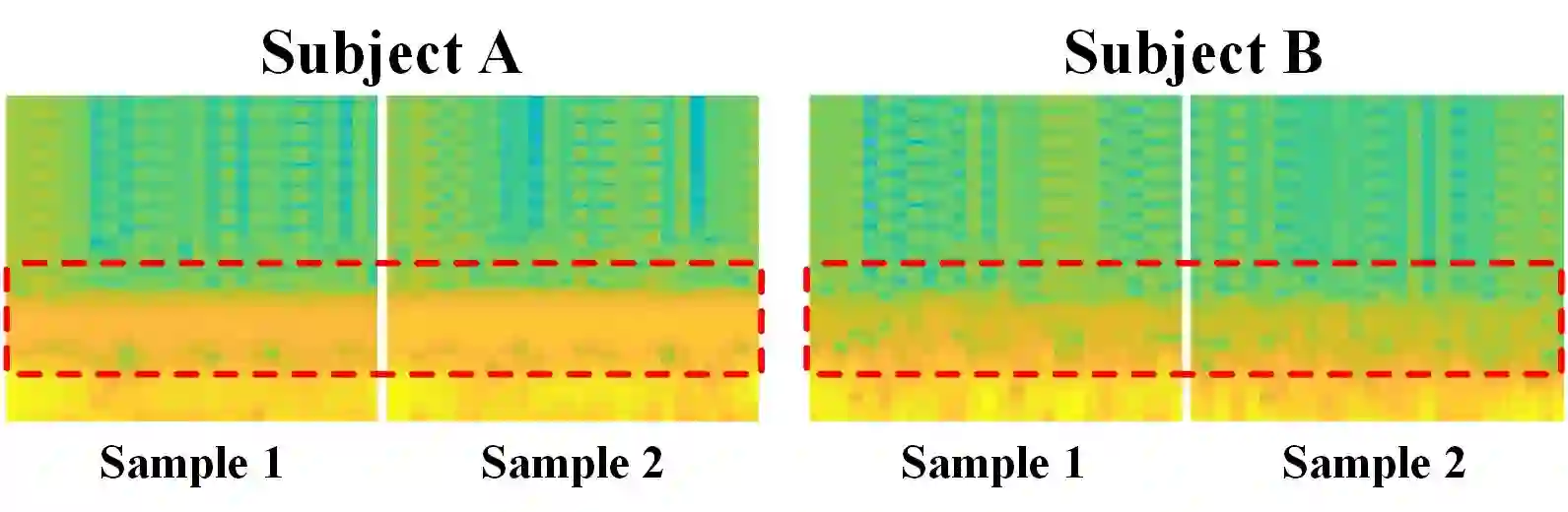
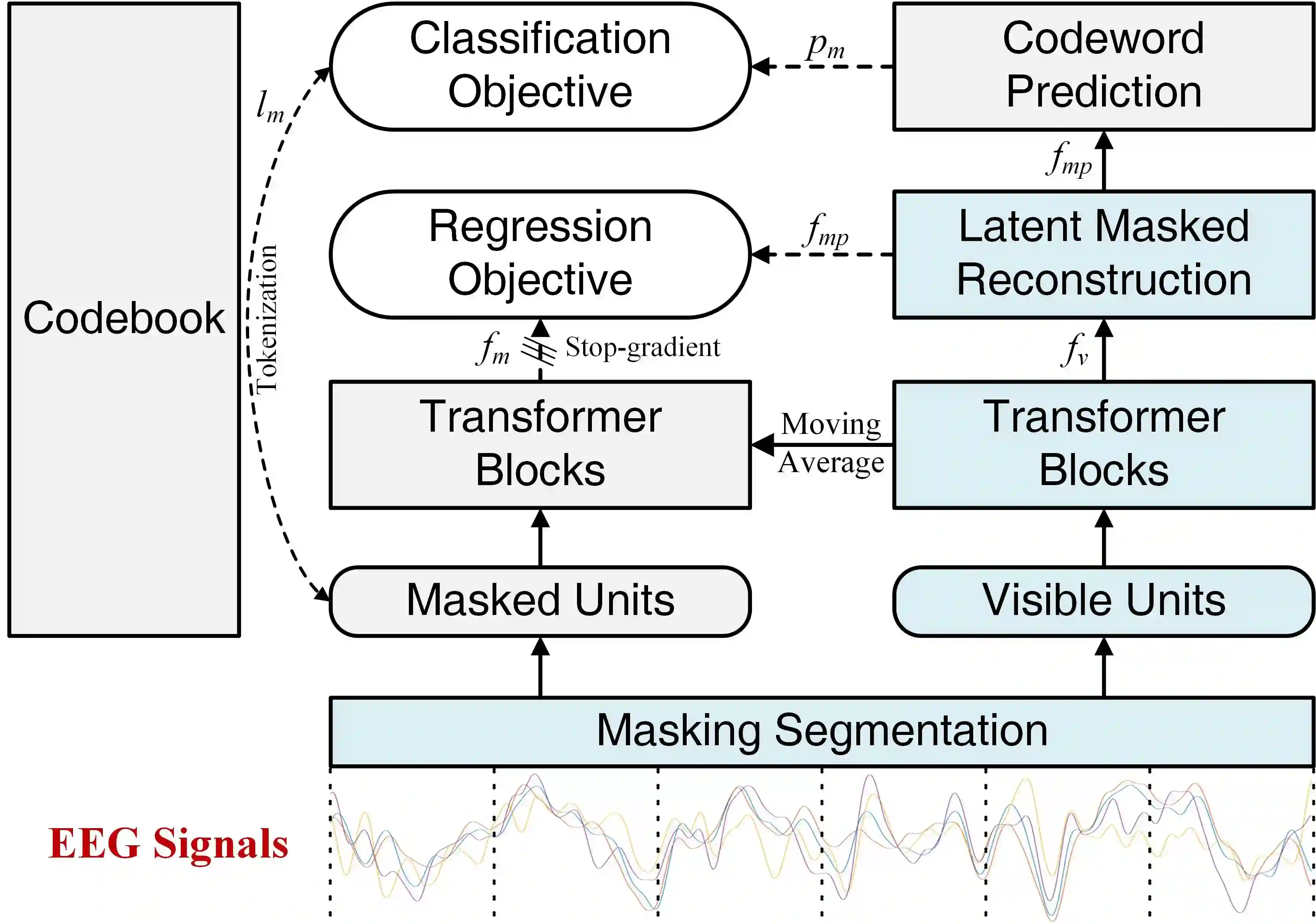
Analyzing and reconstructing visual stimuli from brain signals effectively advances understanding of the human visual system. However, the EEG signals are complex and contain a amount of noise. This leads to substantial limitations in existing works of visual stimuli reconstruction from EEG, such as difficulties in aligning EEG embeddings with the fine-grained semantic information and a heavy reliance on additional large self-collected dataset for training. To address these challenges, we propose a novel approach called BrainVis. Firstly, we divide the EEG signals into various units and apply a self-supervised approach on them to obtain EEG time-domain features, in an attempt to ease the training difficulty. Additionally, we also propose to utilize the frequency-domain features to enhance the EEG representations. Then, we simultaneously align EEG time-frequency embeddings with the interpolation of the coarse and fine-grained semantics in the CLIP space, to highlight the primary visual components and reduce the cross-modal alignment difficulty. Finally, we adopt the cascaded diffusion models to reconstruct images. Our proposed BrainVis outperforms state of the arts in both semantic fidelity reconstruction and generation quality. Notably, we reduce the training data scale to 10% of the previous work.
翻译:从脑信号中分析和重建视觉刺激能有效推动对人类视觉系统的理解。然而,脑电图(EEG)信号复杂且包含大量噪声,导致现有基于EEG的视觉刺激重建工作存在显著局限性,例如难以将EEG嵌入向量与细粒度语义信息对齐,以及对额外大规模自采集数据集的高度依赖。为解决这些挑战,我们提出一种名为BrainVis的新方法。首先,我们将EEG信号划分为不同单元,并对其应用自监督方法以获取EEG时域特征,从而降低训练难度。此外,我们提出利用频域特征增强EEG表示。随后,我们将EEG时频嵌入向量与CLIP空间中粗粒度与细粒度语义的插值结果同时对齐,以突出主要视觉成分并降低跨模态对齐难度。最终,我们采用级联扩散模型重建图像。所提出的BrainVis在语义保真度重建和生成质量上均优于现有最优方法。值得注意的是,我们将训练数据规模缩减至前人工作的10%。