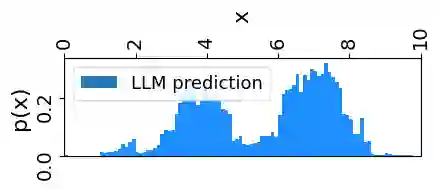
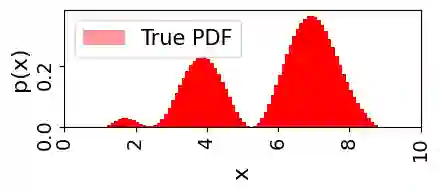
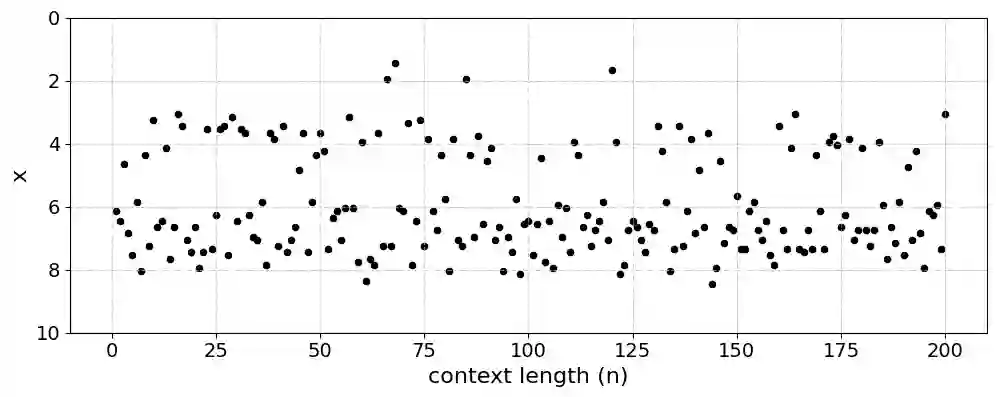
Large language models (LLMs) demonstrate remarkable emergent abilities to perform in-context learning across various tasks, including time series forecasting. This work investigates LLMs' ability to estimate probability density functions (PDFs) from data observed in-context; such density estimation (DE) is a fundamental task underlying many probabilistic modeling problems. We leverage the Intensive Principal Component Analysis (InPCA) to visualize and analyze the in-context learning dynamics of LLaMA-2 models. Our main finding is that these LLMs all follow similar learning trajectories in a low-dimensional InPCA space, which are distinct from those of traditional density estimation methods like histograms and Gaussian kernel density estimation (KDE). We interpret the LLaMA in-context DE process as a KDE with an adaptive kernel width and shape. This custom kernel model captures a significant portion of LLaMA's behavior despite having only two parameters. We further speculate on why LLaMA's kernel width and shape differs from classical algorithms, providing insights into the mechanism of in-context probabilistic reasoning in LLMs.
翻译:大语言模型(LLMs)展现出卓越的涌现能力,能够在包括时间序列预测在内的多种任务中实现情境学习。本研究探讨了LLMs根据情境中观测数据估计概率密度函数(PDFs)的能力;此类密度估计(DE)是许多概率建模问题的基本任务。我们利用密集主成分分析(InPCA)对LLaMA-2模型的情境学习动态进行可视化与分析。主要发现表明,这些LLMs在低维InPCA空间中均遵循相似的学习轨迹,该轨迹与直方图和高斯核密度估计(KDE)等传统密度估计方法的学习轨迹存在显著差异。我们将LLaMA的情境DE过程解释为具有自适应核宽度与形状的KDE。尽管仅包含两个参数,该定制核模型仍能捕捉LLaMA行为的重要特征。我们进一步探讨了LLaMA的核宽度与形状区别于经典算法的原因,从而为理解LLMs情境概率推理机制提供了新的见解。