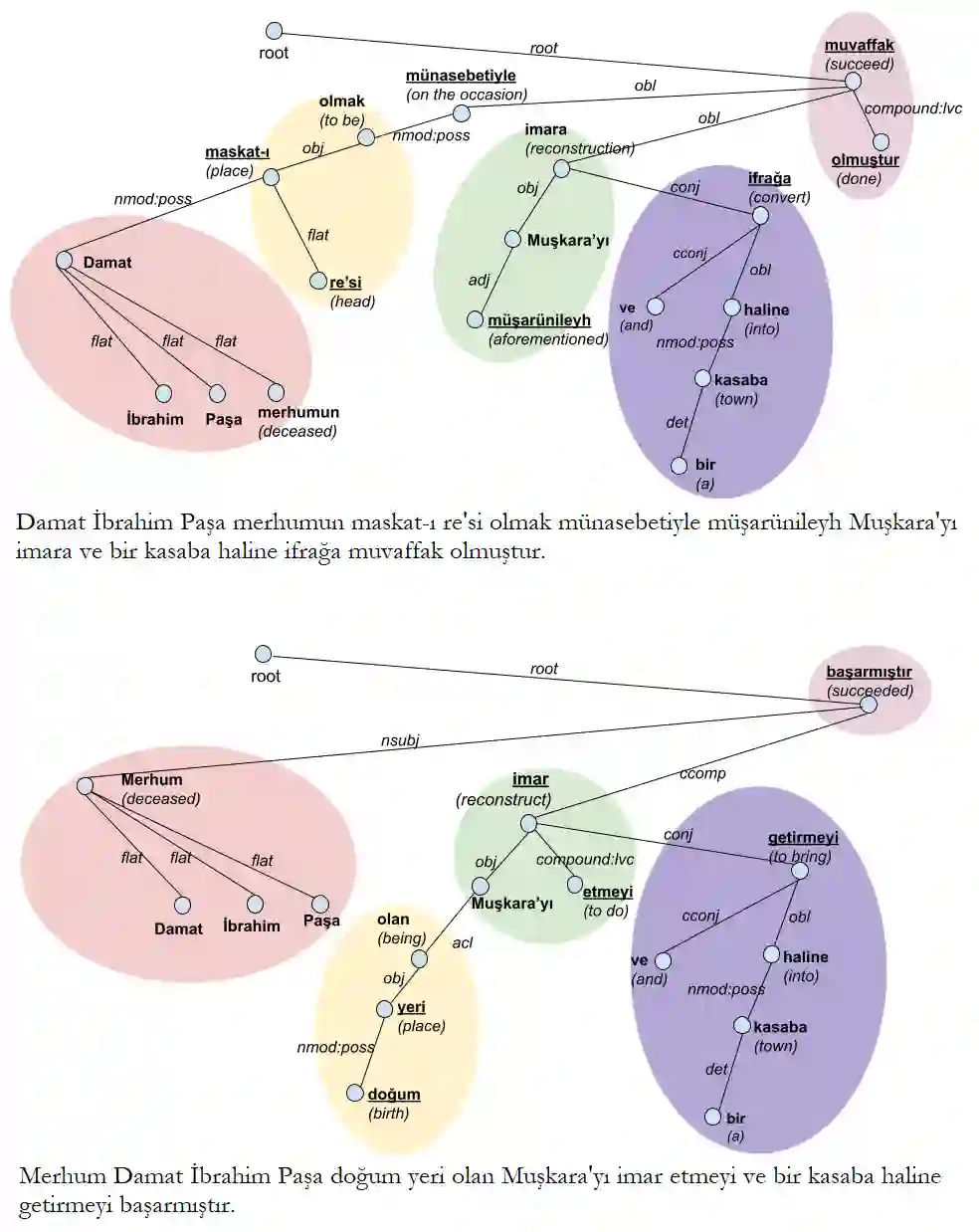
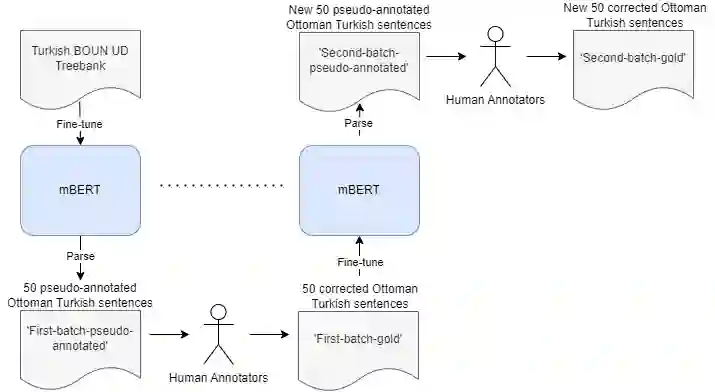
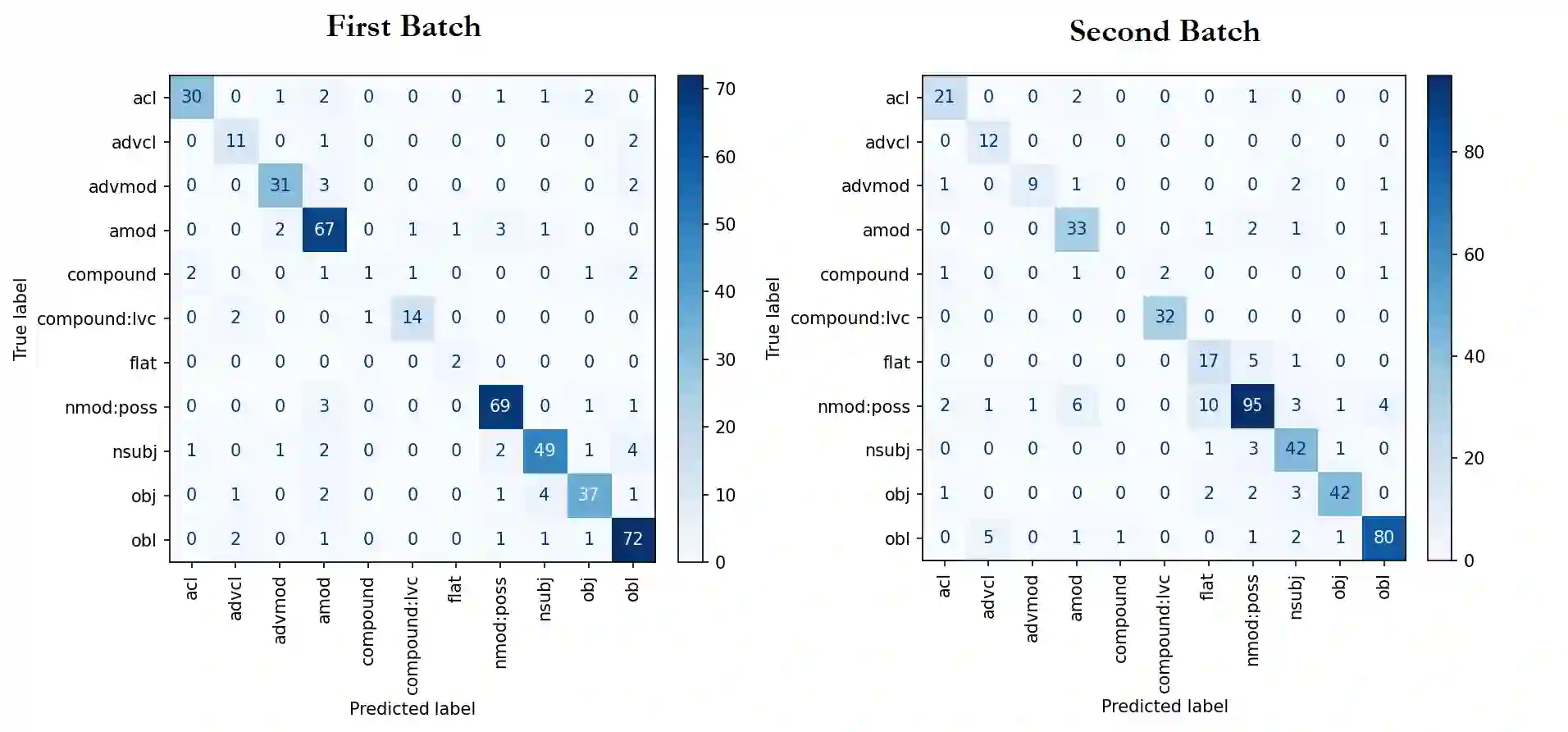
This study introduces a pretrained large language model-based annotation methodology for the first dependency treebank in Ottoman Turkish. Our experimental results show that, iteratively, i) pseudo-annotating data using a multilingual BERT-based parsing model, ii) manually correcting the pseudo-annotations, and iii) fine-tuning the parsing model with the corrected annotations, we speed up and simplify the challenging dependency annotation process. The resulting treebank, that will be a part of the Universal Dependencies (UD) project, will facilitate automated analysis of Ottoman Turkish documents, unlocking the linguistic richness embedded in this historical heritage.
翻译:本研究提出了一种基于预训练大语言模型的标注方法,用于构建首个奥斯曼土耳其语依存树库。实验结果表明,通过迭代执行以下步骤:(i)利用基于多语言BERT的句法分析模型进行伪标注;(ii)人工修正伪标注结果;(iii)使用修正后的标注对分析模型进行微调,我们显著加速并简化了具有挑战性的依存标注过程。该树库将作为通用依存(UD)项目的一部分,有助于实现奥斯曼土耳其语文档的自动化分析,从而挖掘这一历史遗产中蕴含的语言丰富性。