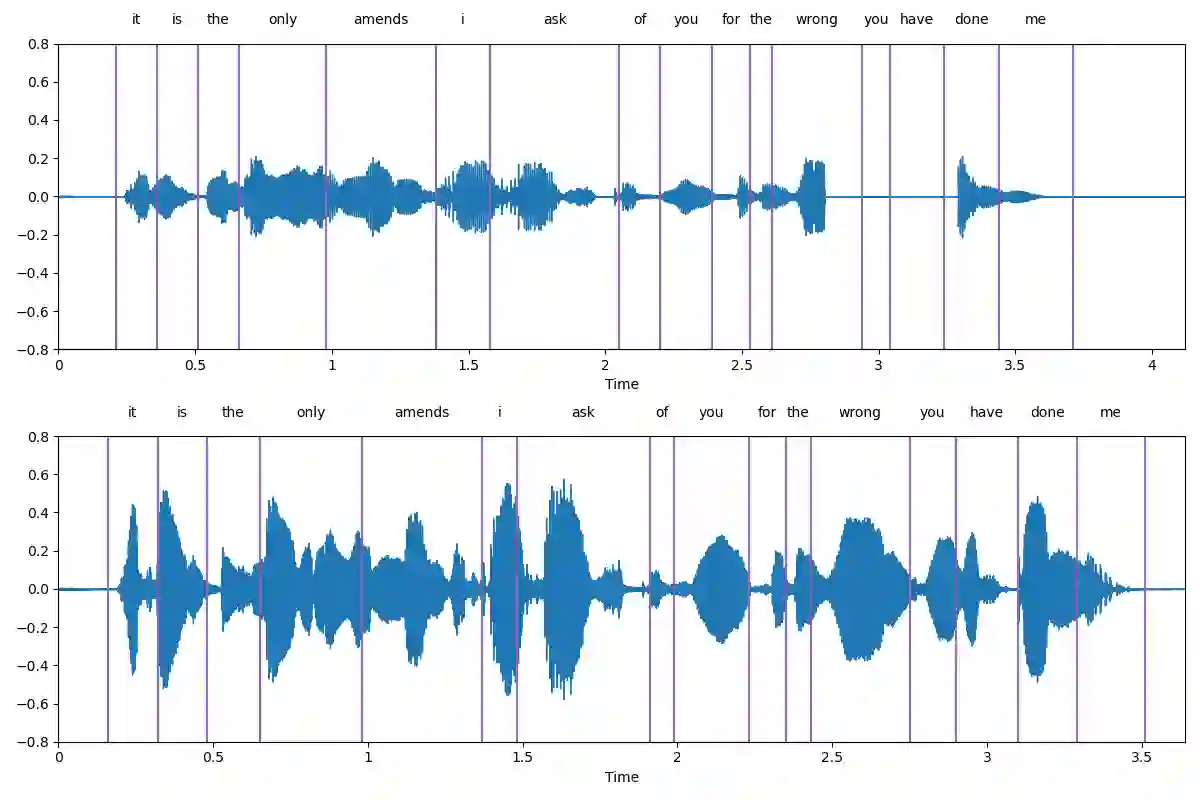
Large language models (LLMs) have gained considerable attention for Artificial Intelligence Generated Content (AIGC), particularly with the emergence of ChatGPT. However, the direct adaptation of continuous speech to LLMs that process discrete tokens remains an unsolved challenge, hindering the application of LLMs for speech generation. The advanced speech LMs are in the corner, as that speech signals encapsulate a wealth of information, including speaker and emotion, beyond textual data alone. Prompt tuning has demonstrated notable gains in parameter efficiency and competitive performance on some speech classification tasks. However, the extent to which prompts can effectively elicit generation tasks from speech LMs remains an open question. In this paper, we present pioneering research that explores the application of prompt tuning to stimulate speech LMs for various generation tasks, within a unified framework called SpeechGen, with around 10M trainable parameters. The proposed unified framework holds great promise for efficiency and effectiveness, particularly with the imminent arrival of advanced speech LMs, which will significantly enhance the capabilities of the framework. The code and demos of SpeechGen will be available on the project website: \url{https://ga642381.github.io/SpeechPrompt/speechgen}
翻译:大型语言模型(LLMs)在人工智能生成内容(AIGC)领域引起了广泛关注,尤其是ChatGPT的出现。然而,将连续语音直接适配于处理离散令牌的LLMs仍是一个未解决的挑战,这阻碍了LLMs在语音生成任务中的应用。由于语音信号包含说话人身份、情感等超越文本数据的丰富信息,先进的语音语言模型(speech LMs)亟待出现。提示调优(prompt tuning)已在部分语音分类任务中展现出显著的参数效率提升和竞争性性能。但提示能否有效激发语音语言模型执行生成任务,仍是一个待解的问题。本文开展开创性研究,探索将提示调优应用于统一的框架SpeechGen(可训练参数约1000万),以激励语音语言模型完成多种生成任务。所提出的统一框架在效率和效果上展现出巨大潜力——尤其随着先进语音语言模型的即将问世,该框架的能力将得到显著增强。SpeechGen的代码与演示将在项目网站公开:\url{https://ga642381.github.io/SpeechPrompt/speechgen}