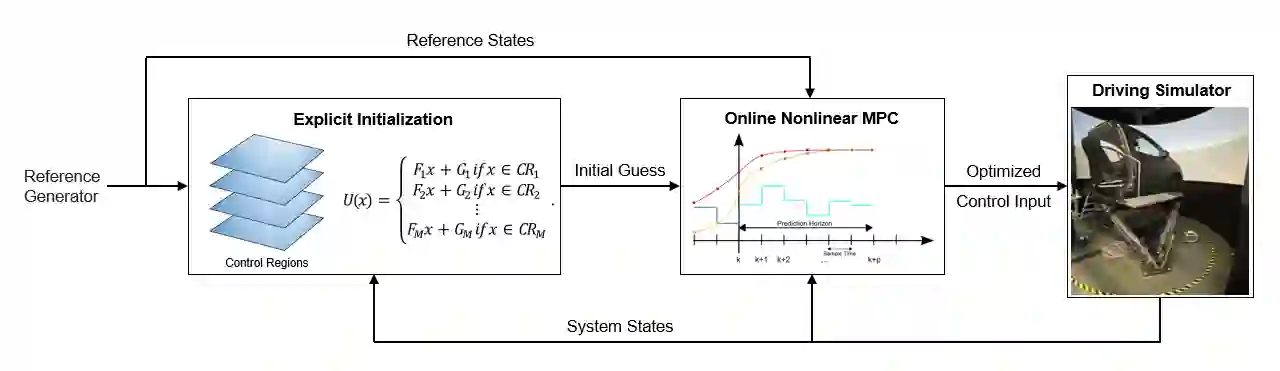
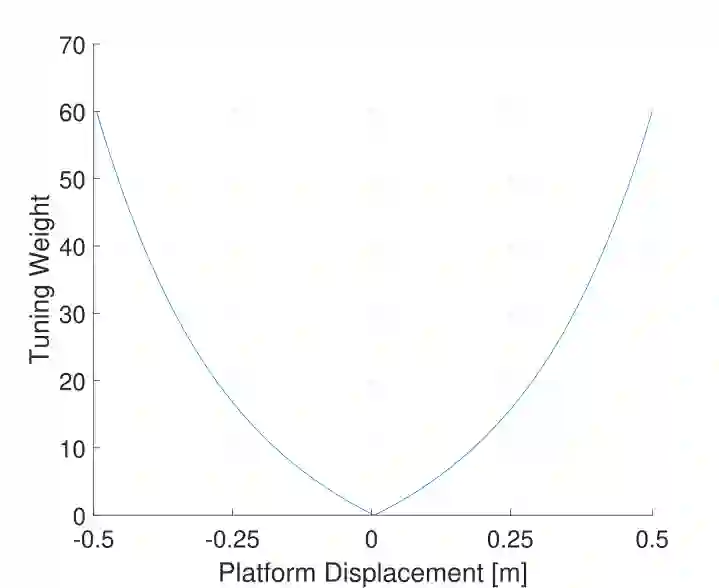
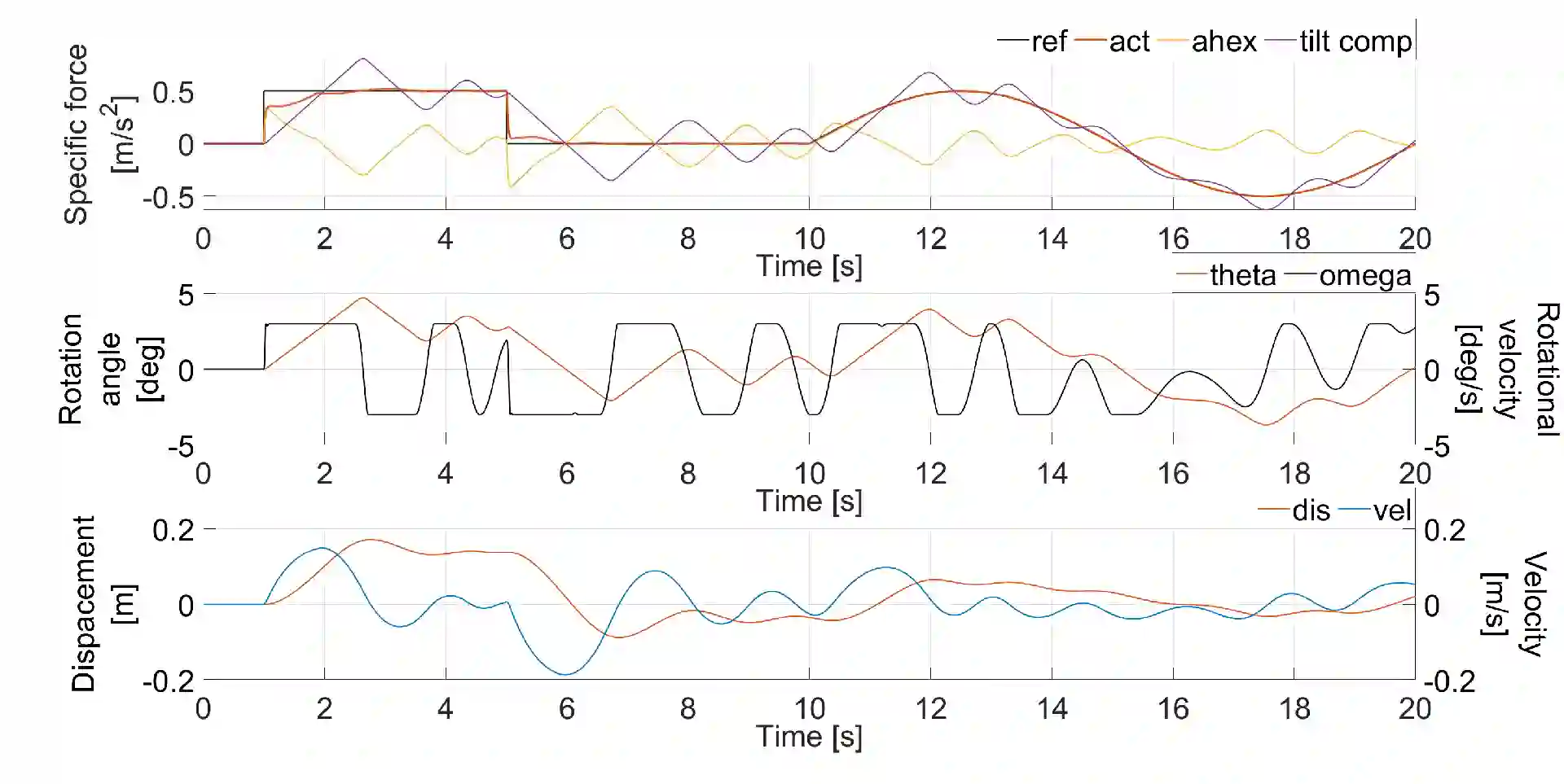
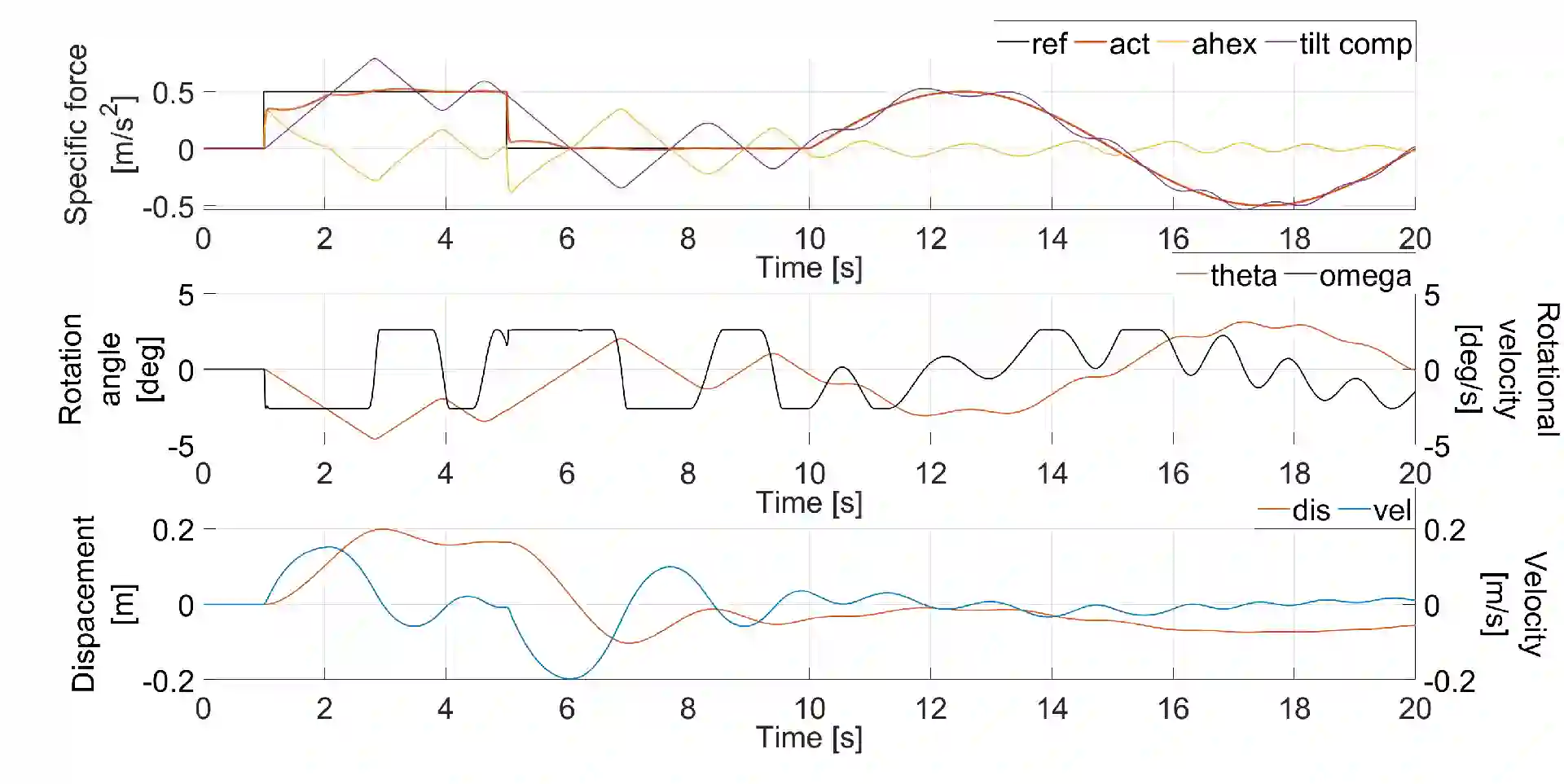
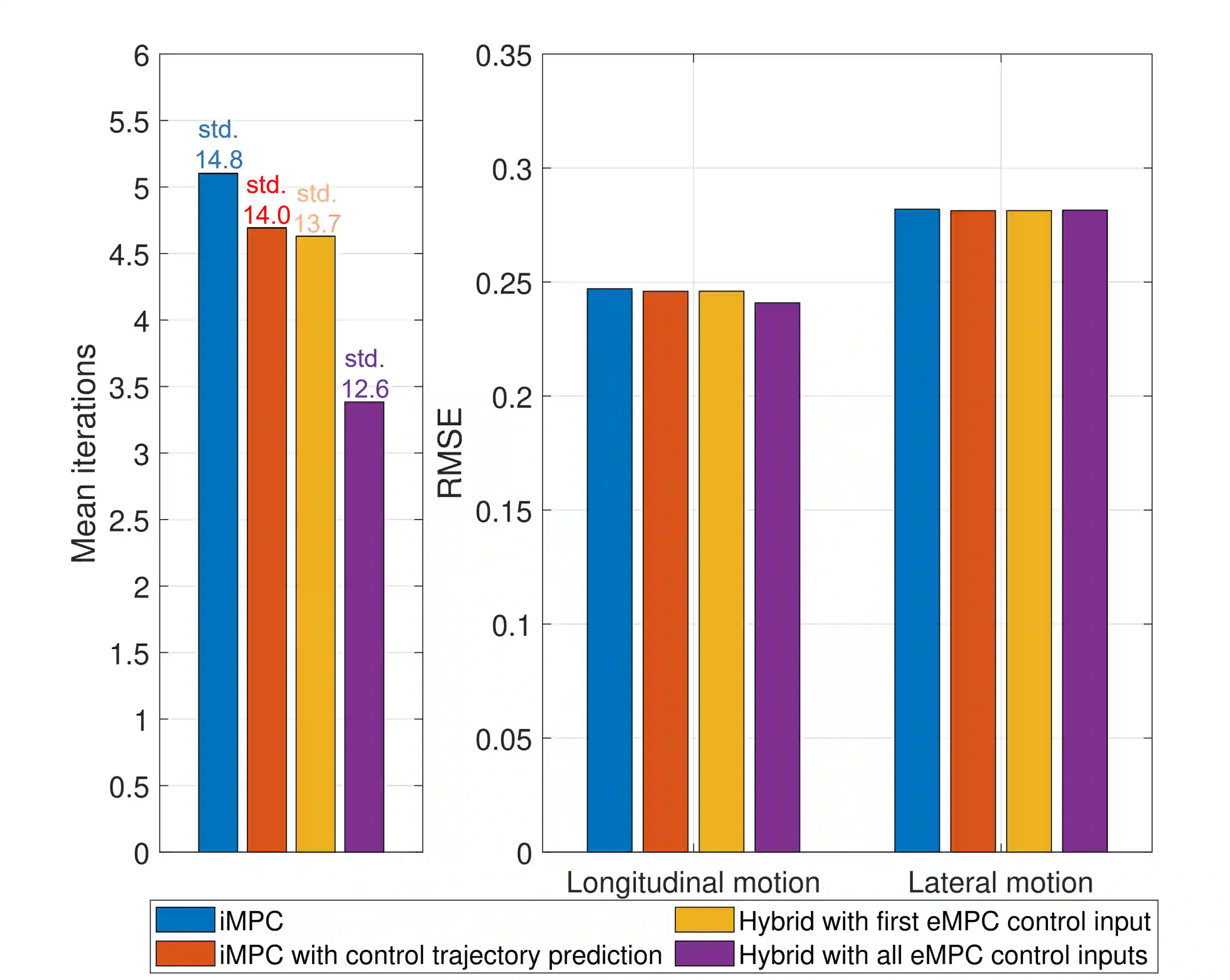
Driving simulators have been used in the automotive industry for many years because of their ability to perform tests in a safe, reproducible and controlled immersive virtual environment. The improved performance of the simulator and its ability to recreate in-vehicle experience for the user is established through motion cueing algorithms (MCA). Such algorithms have constantly been developed with model predictive control (MPC) acting as the main control technique. Currently, available MPC-based methods either compute the optimal controller online or derive an explicit control law offline. These approaches limit the applicability of the MCA for real-time applications due to online computational costs and/or offline memory storage issues. This research presents a solution to deal with issues of offline and online solving through a hybrid approach. For this, an explicit MPC is used to generate a look-up table to provide an initial guess as a warm-start for the implicit MPC-based MCA. From the simulations, it is observed that the presented hybrid approach is able to reduce online computation load by shifting it offline using the explicit controller. Further, the algorithm demonstrates a good tracking performance with a significant reduction of computation time in a complex driving scenario using an emulator environment of a driving simulator.
翻译:长期以来,驾驶模拟器因其能够在安全、可重复且受控的沉浸式虚拟环境中进行测试而被广泛应用于汽车工业。模拟器性能的提升及其为使用者再造车内体验的能力,是通过运动提示算法(MCA)实现的。此类算法持续发展,模型预测控制(MPC)作为主要控制技术。当前,基于MPC的方法要么在线计算最优控制器,要么离线推导显式控制律。这些方法因在线计算成本及/或离线存储空间问题,限制了MCA在实时应用中的适用性。本研究提出一种融合方案,以应对离线与在线求解的难题。具体而言,采用显式MPC生成查找表,为基于隐式MPC的MCA提供热启动初始猜测。仿真结果表明,所提出的混合方法通过显式控制器将在线计算负荷转移至离线,从而降低在线计算量。此外,该算法在驾驶模拟器仿真环境下的复杂驾驶场景中展现出良好的跟踪性能,并显著缩短了计算时间。