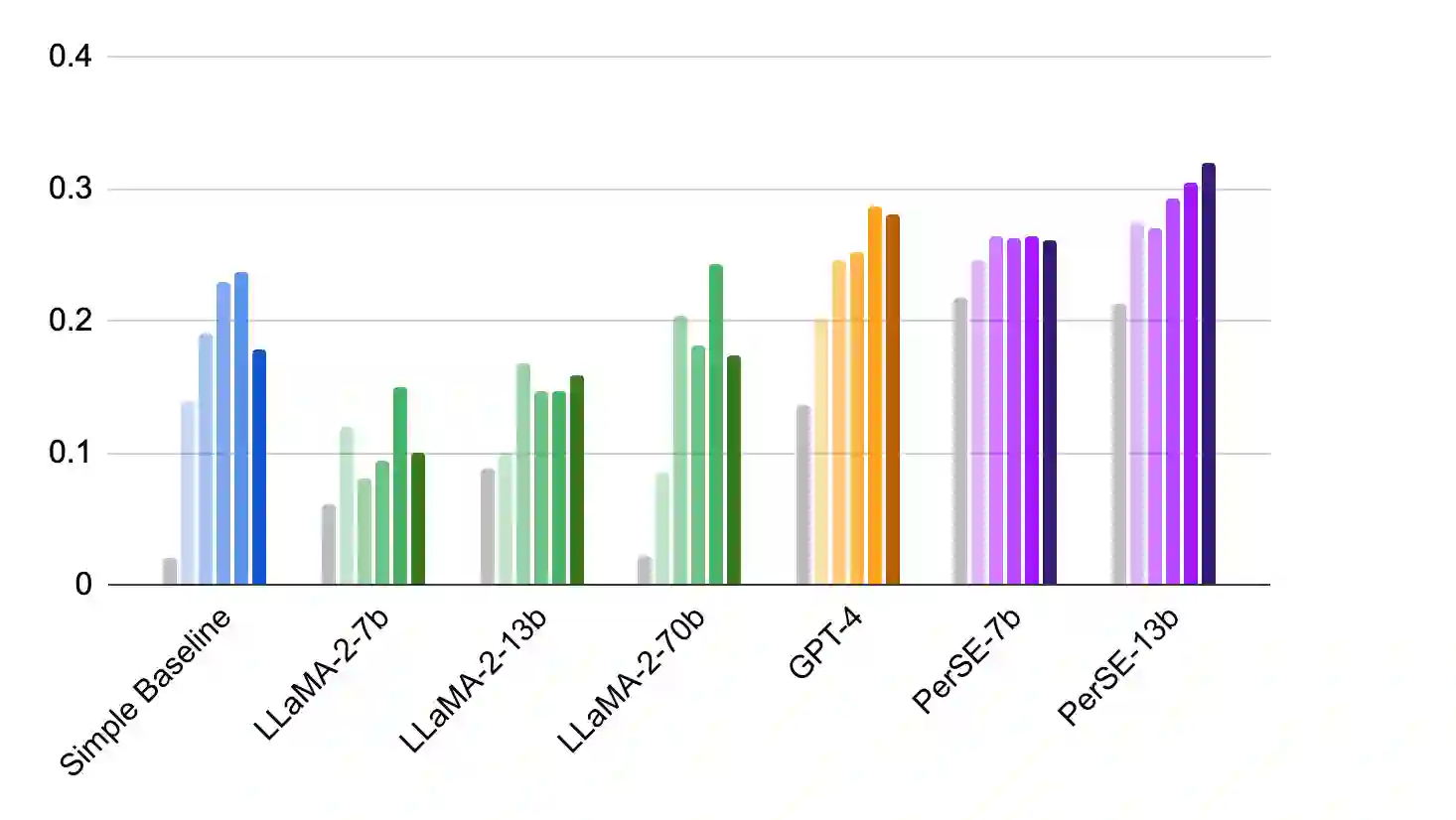
While large language models (LLMs) have shown impressive results for more objective tasks such as QA and retrieval, it remains nontrivial to evaluate their performance on open-ended text generation for reasons including (1) data contamination; (2) multi-dimensional evaluation criteria; and (3) subjectiveness stemming from reviewers' personal preferences. To address such issues, we propose to model personalization in an uncontaminated open-ended generation assessment. We create two new datasets Per-MPST and Per-DOC for personalized story evaluation, by re-purposing existing datasets with proper anonymization and new personalized labels. We further develop a personalized story evaluation model PERSE to infer reviewer preferences and provide a personalized evaluation. Specifically, given a few exemplary reviews from a particular reviewer, PERSE predicts either a detailed review or fine-grained comparison in several aspects (such as interestingness and surprise) for that reviewer on a new text input. Experimental results show that PERSE outperforms GPT-4 by 15.8% on Kendall correlation of story ratings, and by 13.7% on pairwise preference prediction accuracy. Both datasets and code will be released at https://github.com/dqwang122/PerSE.
翻译:尽管大型语言模型(LLMs)在问答和检索等更客观的任务中展现出显著成果,但其在开放式文本生成任务上的性能评估仍面临诸多挑战,具体包括:(1) 数据污染;(2) 多维度评价标准;(3) 评审者个人偏好导致的主观性。为解决这些问题,我们提出在无污染的开放式生成评估中建模个性化特征。通过重新利用现有数据集并进行适当的匿名化处理和新增个性化标注,我们构建了Per-MPST和Per-DOC两个用于个性化故事评估的新数据集。我们进一步开发了个性化故事评估模型PERSE,用于推断评审者偏好并提供个性化评估。具体而言,给定某位评审者提供的少量评审样例,PERSE能够针对该评审者对新的文本输入预测详细的评分或在趣味性、惊喜程度等多个维度进行细粒度比较。实验结果表明,PERSE在故事评分的肯德尔相关系数上比GPT-4提升15.8%,在成对偏好预测准确率上提升13.7%。相关数据集和代码将在https://github.com/dqwang122/PerSE开源。