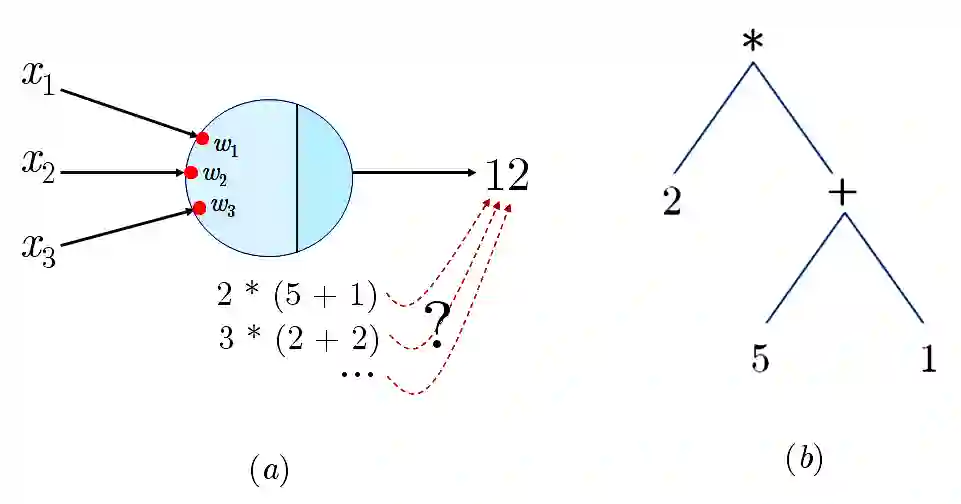
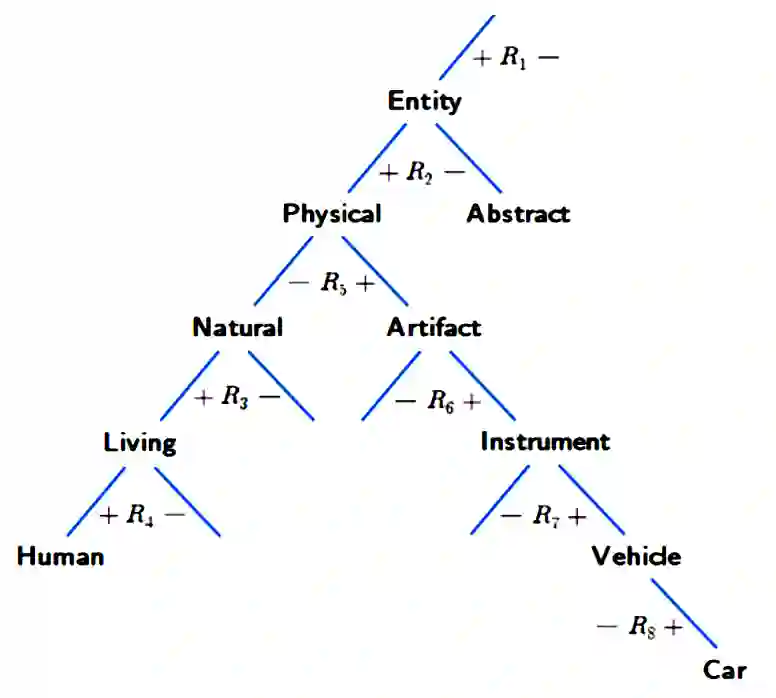
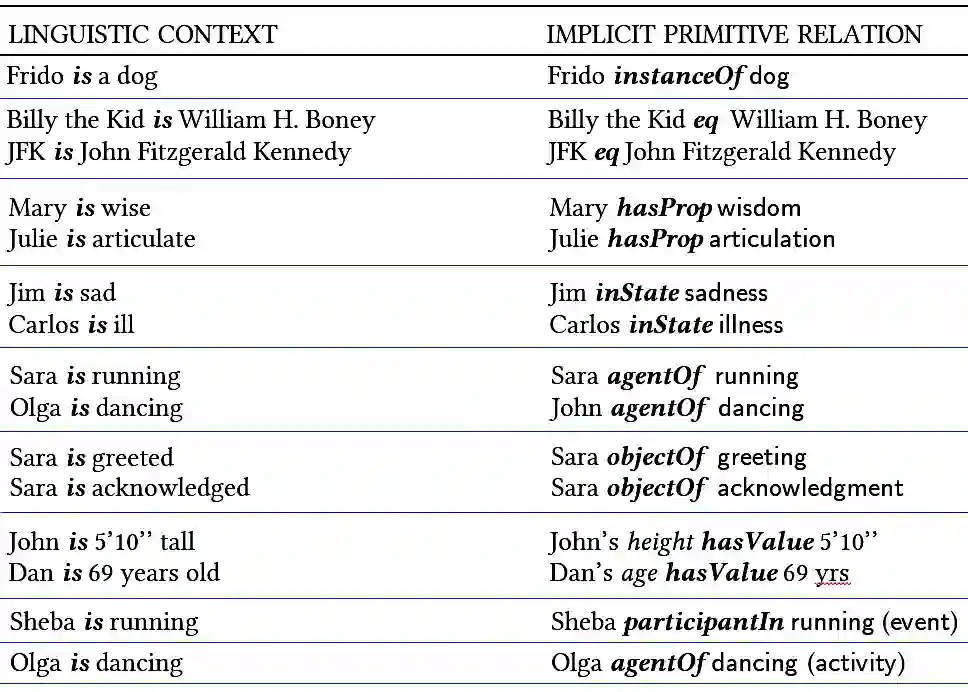
Large language models (LLMs) have achieved a milestone that undenia-bly changed many held beliefs in artificial intelligence (AI). However, there remains many limitations of these LLMs when it comes to true language understanding, limitations that are a byproduct of the under-lying architecture of deep neural networks. Moreover, and due to their subsymbolic nature, whatever knowledge these models acquire about how language works will always be buried in billions of microfeatures (weights), none of which is meaningful on its own, making such models hopelessly unexplainable. To address these limitations, we suggest com-bining the strength of symbolic representations with what we believe to be the key to the success of LLMs, namely a successful bottom-up re-verse engineering of language at scale. As such we argue for a bottom-up reverse engineering of language in a symbolic setting. Hints on what this project amounts to have been suggested by several authors, and we discuss in some detail here how this project could be accomplished.
翻译:大型语言模型(LLMs)取得了里程碑式成就,毫无疑问地改变了人工智能领域的诸多固有认知。然而,这些LLMs在真正的语言理解方面仍存在诸多局限,这些局限本质上是深度神经网络底层架构的副产品。此外,由于子符号特性,这些模型获得的任何关于语言运作方式的知识都将永远埋藏在数十亿个微观特征(权重)中——每个特征本身毫无意义,导致这类模型陷入不可解释的困境。为解决这些局限,我们建议将符号化表征的优势与我们认为LLMs成功的关键要素相结合:即对语言进行大规模的、自底向上的逆向工程。由此,我们主张在符号化框架下对语言实施自底向上的逆向工程。多位学者已就这一研究方向的要义提出启示性见解,本文将详细阐述该研究计划的实现路径。