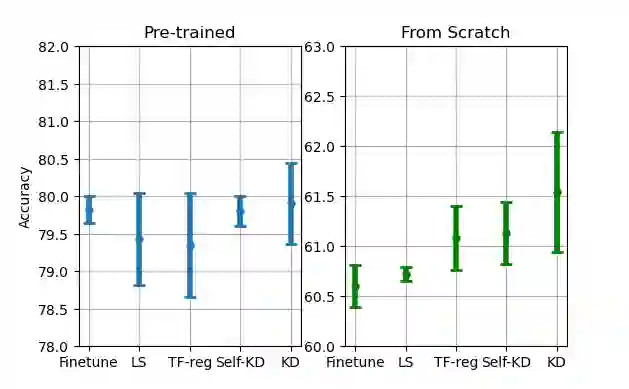
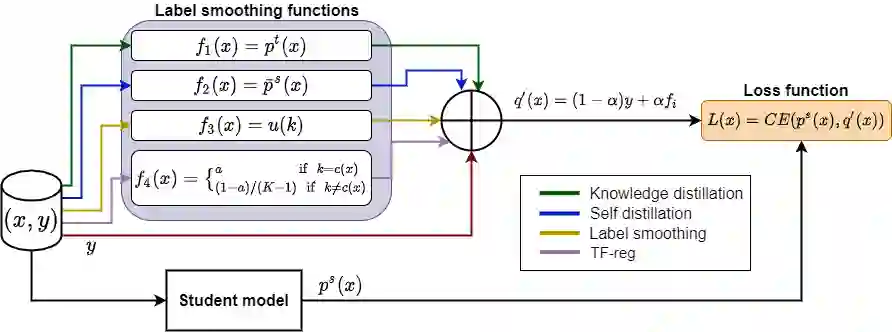
Knowledge Distillation (KD) is a prominent neural model compression technique that heavily relies on teacher network predictions to guide the training of a student model. Considering the ever-growing size of pre-trained language models (PLMs), KD is often adopted in many NLP tasks involving PLMs. However, it is evident that in KD, deploying the teacher network during training adds to the memory and computational requirements of training. In the computer vision literature, the necessity of the teacher network is put under scrutiny by showing that KD is a label regularization technique that can be replaced with lighter teacher-free variants such as the label-smoothing technique. However, to the best of our knowledge, this issue is not investigated in NLP. Therefore, this work concerns studying different label regularization techniques and whether we actually need them to improve the fine-tuning of smaller PLM networks on downstream tasks. In this regard, we did a comprehensive set of experiments on different PLMs such as BERT, RoBERTa, and GPT with more than 600 distinct trials and ran each configuration five times. This investigation led to a surprising observation that KD and other label regularization techniques do not play any meaningful role over regular fine-tuning when the student model is pre-trained. We further explore this phenomenon in different settings of NLP and computer vision tasks and demonstrate that pre-training itself acts as a kind of regularization, and additional label regularization is unnecessary.
翻译:知识蒸馏(KD)是一种重要的神经模型压缩技术,它高度依赖教师网络的预测来指导学生模型的训练。考虑到预训练语言模型(PLM)规模不断增长,KD被广泛应用于涉及PLM的许多自然语言处理(NLP)任务中。然而,在KD中,训练时部署教师网络会增加内存和计算需求,这一点已显而易见。在计算机视觉文献中,研究者通过证明KD是一种标签正则化技术,可被更轻量的无教师变体(如标签平滑技术)替代,从而对教师网络的必要性提出了质疑。但据我们所知,这一问题在NLP领域尚未得到研究。因此,本文致力于研究不同标签正则化技术,以及我们是否确实需要它们来改进较小PLM网络在下游任务上的微调性能。为此,我们针对BERT、RoBERTa和GPT等不同PLM进行了全面实验,开展了超过600次独立试验,并对每种配置重复运行五次。这一研究得出了一个令人惊讶的观察结果:在学生模型经过预训练的情况下,KD及其他标签正则化技术相较于常规微调并未发挥任何有意义的作用。我们进一步在NLP和计算机视觉任务的不同场景中探索了这一现象,并证明预训练本身即作为一种正则化形式,而额外的标签正则化是不必要的。