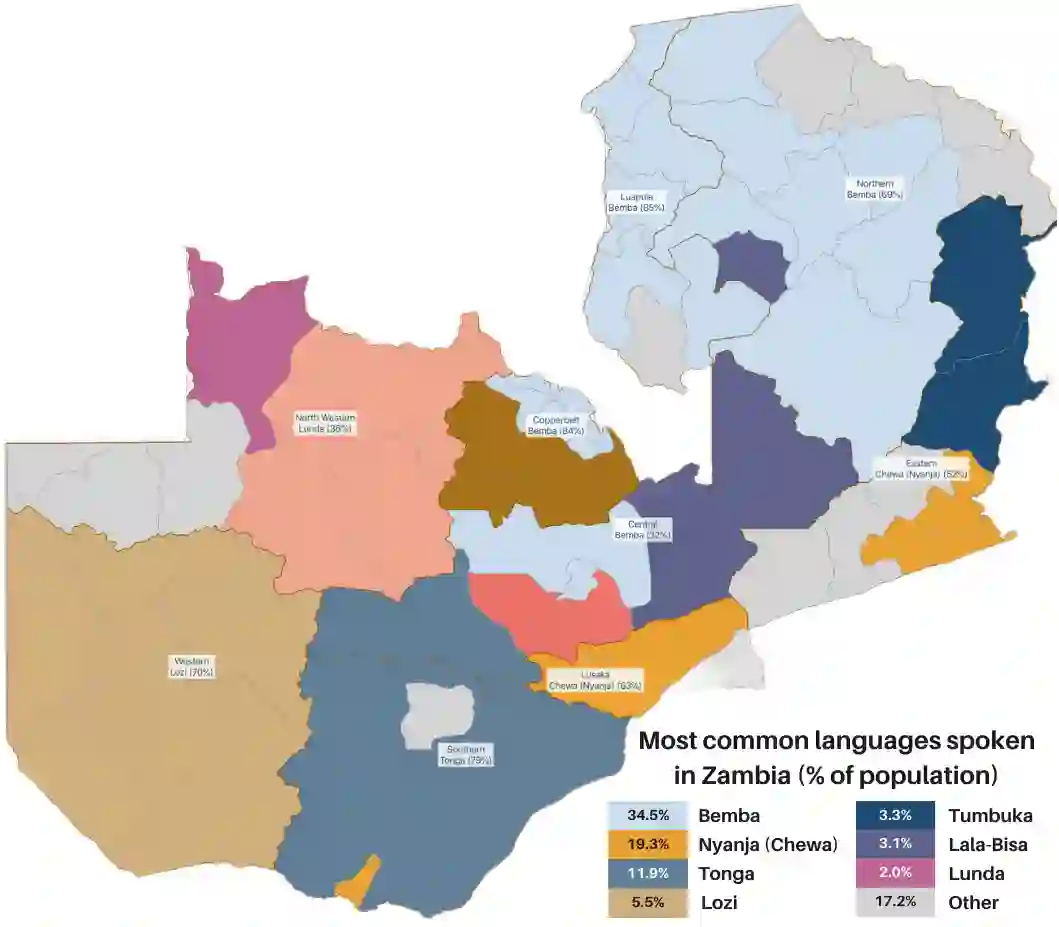
This work introduces Zambezi Voice, an open-source multilingual speech resource for Zambian languages. It contains two collections of datasets: unlabelled audio recordings of radio news and talk shows programs (160 hours) and labelled data (over 80 hours) consisting of read speech recorded from text sourced from publicly available literature books. The dataset is created for speech recognition but can be extended to multilingual speech processing research for both supervised and unsupervised learning approaches. To our knowledge, this is the first multilingual speech dataset created for Zambian languages. We exploit pretraining and cross-lingual transfer learning by finetuning the Wav2Vec2.0 large-scale multilingual pre-trained model to build end-to-end (E2E) speech recognition models for our baseline models. The dataset is released publicly under a Creative Commons BY-NC-ND 4.0 license and can be accessed via https://github.com/unza-speech-lab/zambezi-voice .
翻译:本文介绍赞比西之声(Zambezi Voice),一个针对赞比亚语种的开源多语言语音资源。该资源包含两个数据集集合:未标注的广播新闻和脱口秀节目录音(160小时),以及从公开文学书籍文本录制的标注朗读语音数据(超过80小时)。该数据集专为语音识别创建,但可扩展至监督与无监督学习方法的多语言语音处理研究。据我们所知,这是首个为赞比亚语种构建的多语言语音数据集。我们利用预训练与跨语言迁移学习,通过微调Wav2Vec2.0大规模多语言预训练模型,构建用于基线模型的端到端(E2E)语音识别模型。该数据集在Creative Commons BY-NC-ND 4.0许可下公开发布,可通过https://github.com/unza-speech-lab/zambezi-voice访问。