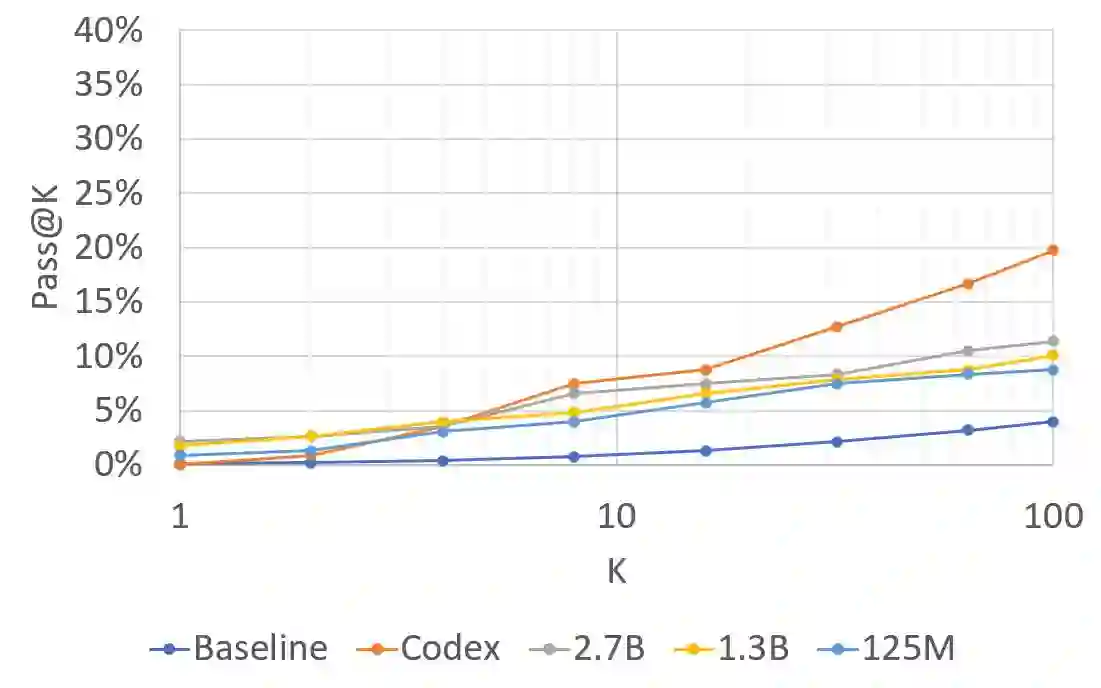
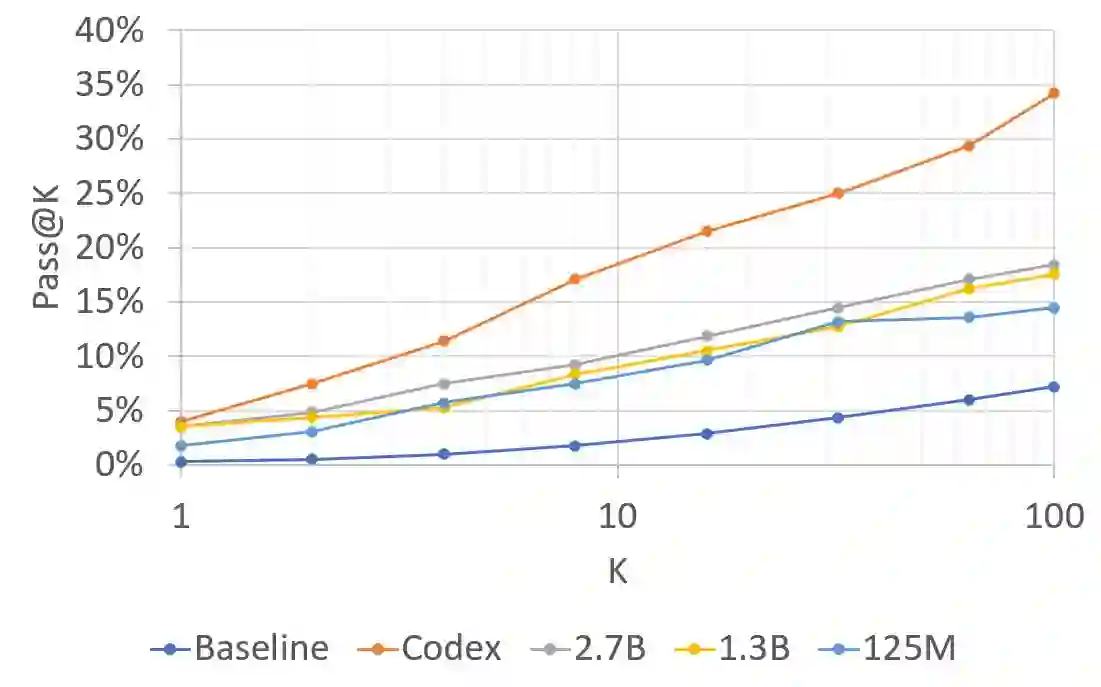
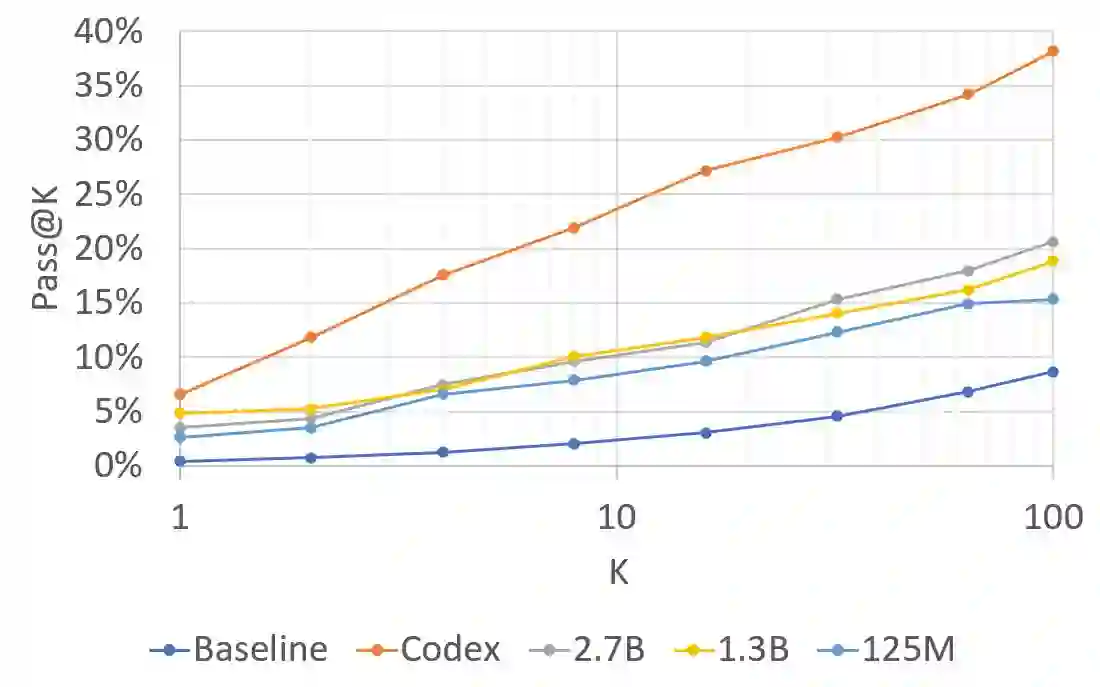
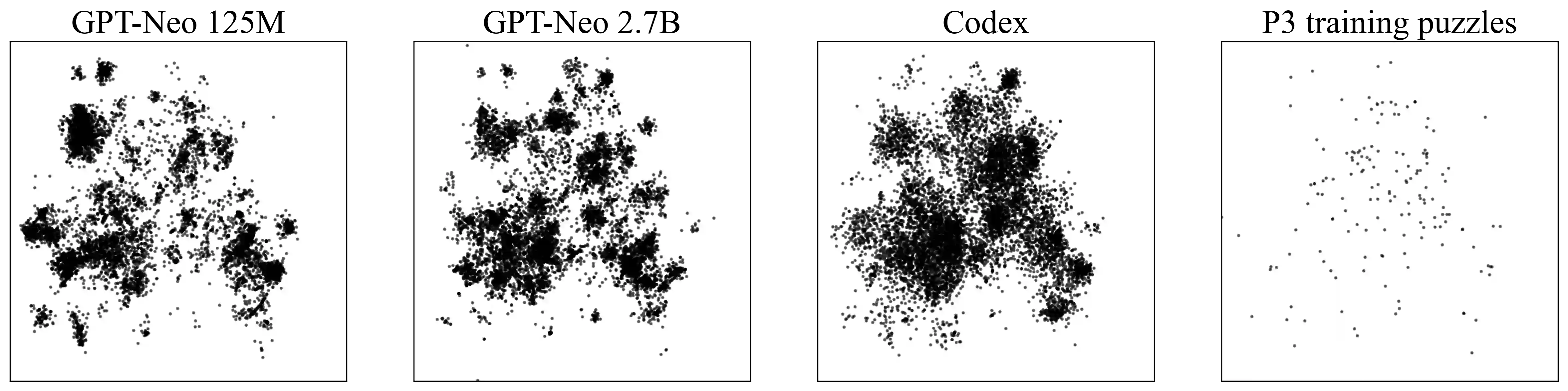
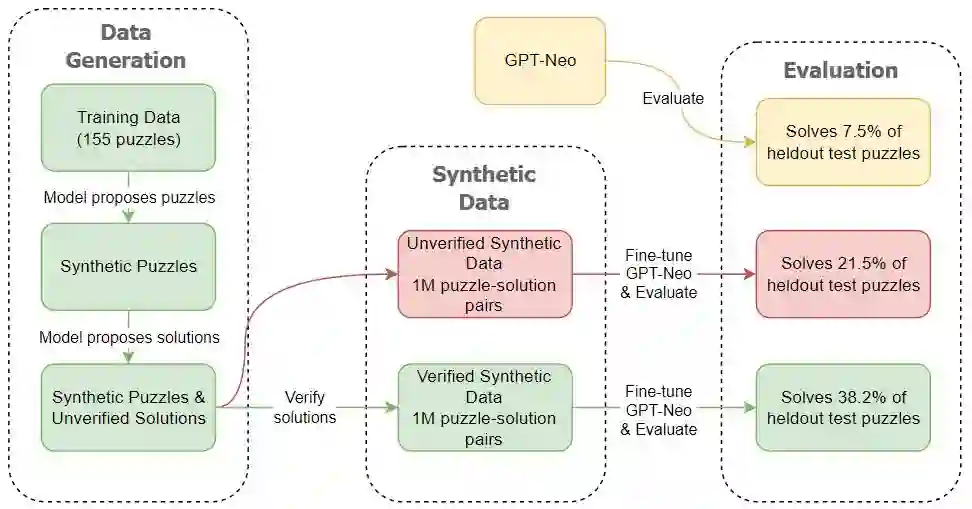
Recent Language Models (LMs) achieve breakthrough performance in code generation when trained on human-authored problems, even solving some competitive-programming problems. Self-play has proven useful in games such as Go, and thus it is natural to ask whether LMs can generate their own instructive programming problems to improve their performance. We show that it is possible for an LM to synthesize programming problems and solutions, which are filtered for correctness by a Python interpreter. The LM's performance is then seen to improve when it is fine-tuned on its own synthetic problems and verified solutions; thus the model 'improves itself' using the Python interpreter. Problems are specified formally as programming puzzles [Schuster et al., 2021], a code-based problem format where solutions can easily be verified for correctness by execution. In experiments on publicly-available LMs, test accuracy more than doubles. This work demonstrates the potential for code LMs, with an interpreter, to generate instructive problems and improve their own performance.
翻译:近期语言模型(LMs)在基于人类编写的题目进行训练后,于代码生成任务中取得突破性表现,甚至能解决部分竞赛编程问题。自我对弈机制在围棋等博弈任务中被证实有效,因此一个自然的问题是:语言模型能否自行生成具有指导意义的编程问题以提升自身性能?我们证明语言模型能够合成编程问题及其解答,并通过Python解释器筛选出正确结果。当模型在其生成的合成问题及已验证解答上进行微调后,其性能得到显著提升——即模型借助Python解释器实现了"自我改进"。问题采用编程谜题[Schuster等人,2021]的形式化规范,这种基于代码的问题格式可通过执行轻松验证解答的正确性。实验表明,在公开可用的语言模型上,测试准确率提升超过一倍。本工作揭示了代码语言模型结合解释器后,具备生成指导性问题并实现自我性能优化的潜力。