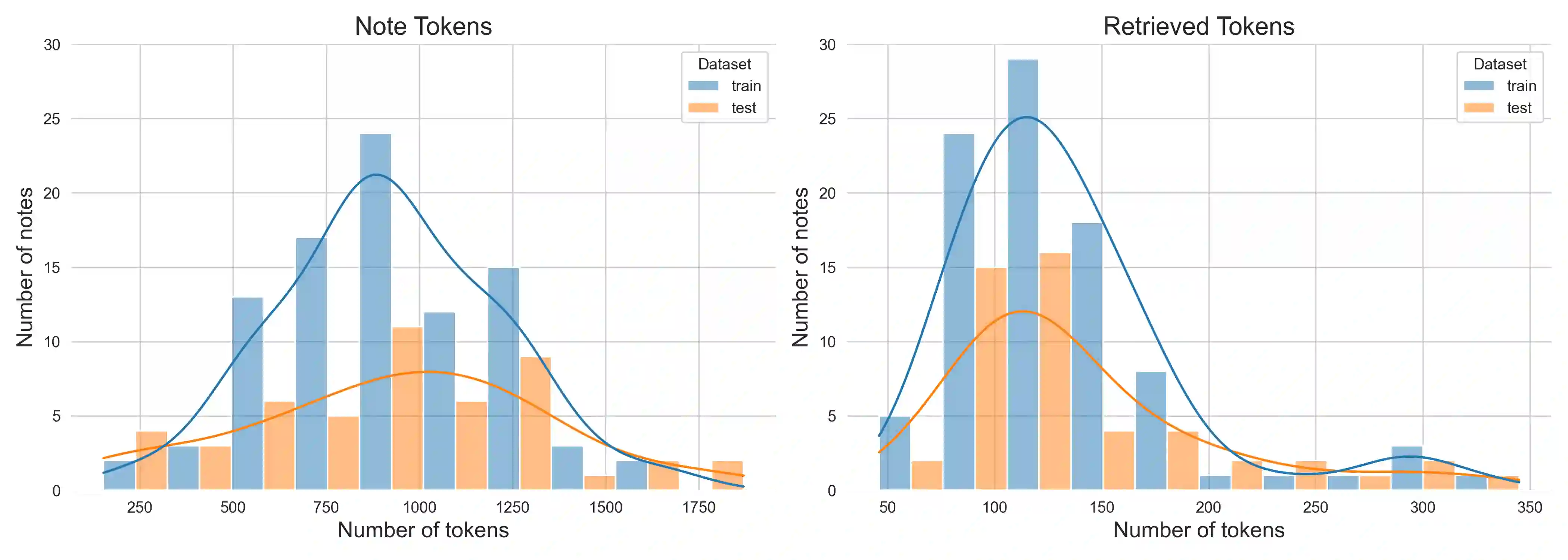
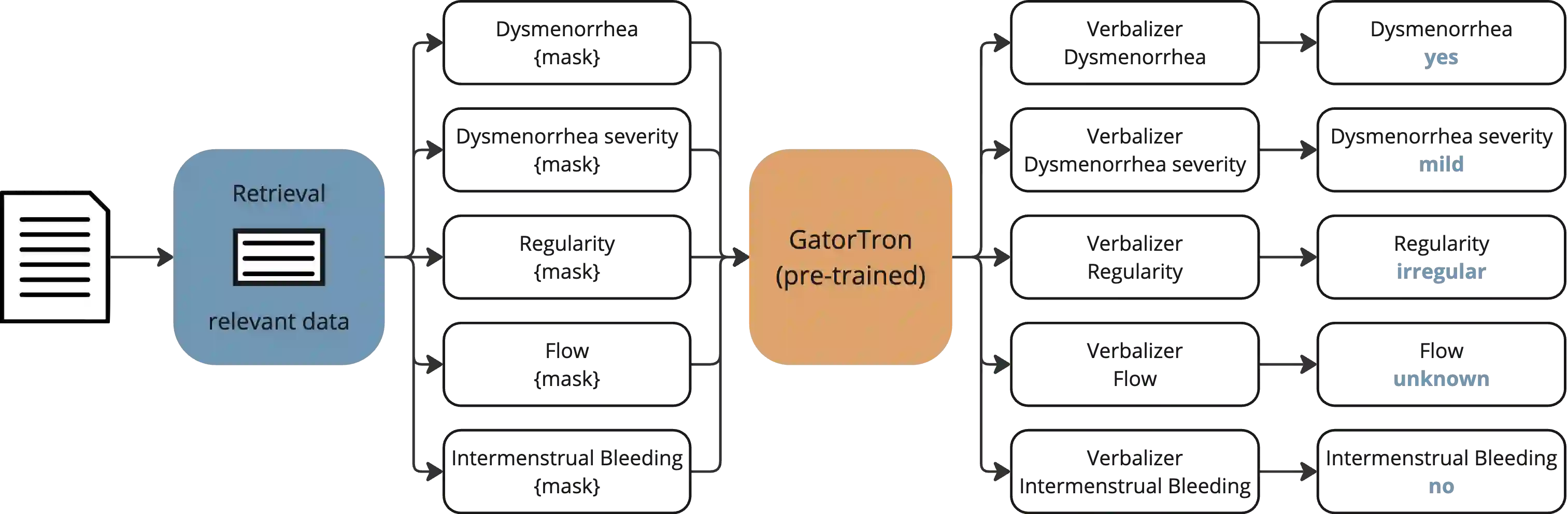
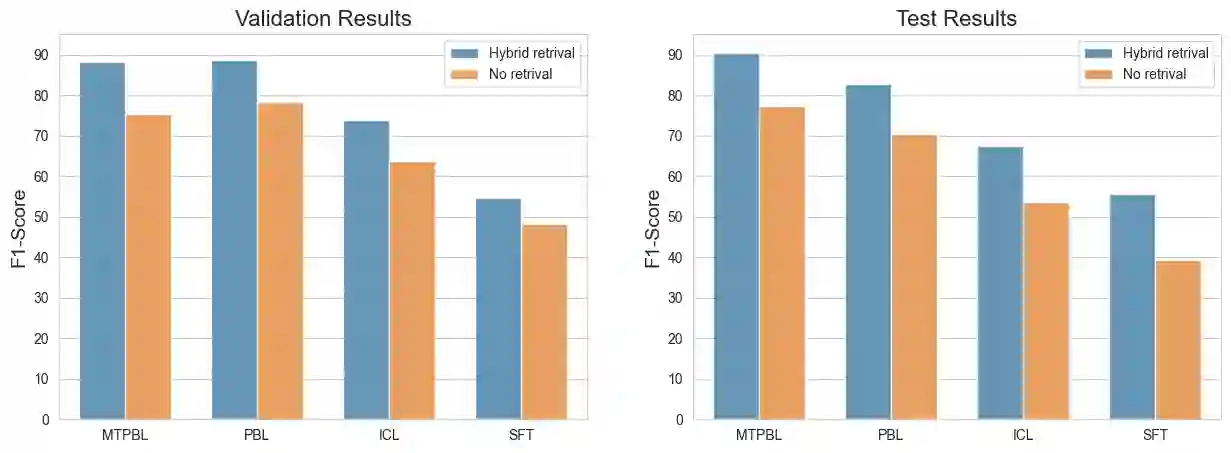
Menstrual health is a critical yet often overlooked aspect of women's healthcare. Despite its clinical relevance, detailed data on menstrual characteristics is rarely available in structured medical records. To address this gap, we propose a novel Natural Language Processing pipeline to extract key menstrual cycle attributes -- dysmenorrhea, regularity, flow volume, and intermenstrual bleeding. Our approach utilizes the GatorTron model with Multi-Task Prompt-based Learning, enhanced by a hybrid retrieval preprocessing step to identify relevant text segments. It out- performs baseline methods, achieving an average F1-score of 90% across all menstrual characteristics, despite being trained on fewer than 100 annotated clinical notes. The retrieval step consistently improves performance across all approaches, allowing the model to focus on the most relevant segments of lengthy clinical notes. These results show that combining multi-task learning with retrieval improves generalization and performance across menstrual charac- teristics, advancing automated extraction from clinical notes and supporting women's health research.
翻译:月经健康是女性医疗保健中至关重要却常被忽视的方面。尽管具有临床相关性,但关于月经特征的详细数据在结构化医疗记录中却很少见。为弥补这一差距,我们提出了一种新颖的自然语言处理流程,用于提取关键的月经周期属性——痛经、规律性、流量以及经间期出血。我们的方法利用GatorTron模型,结合基于提示的多任务学习,并通过混合检索预处理步骤来识别相关文本片段进行增强。该方法在仅使用不到100份标注临床记录进行训练的情况下,超越了基线方法,在所有月经特征上平均F1分数达到90%。检索步骤在所有方法中均能持续提升性能,使模型能够专注于冗长临床记录中最相关的部分。这些结果表明,将多任务学习与检索相结合,能提高模型在各项月经特征上的泛化能力和性能,从而推进从临床记录中自动提取信息,并支持女性健康研究。