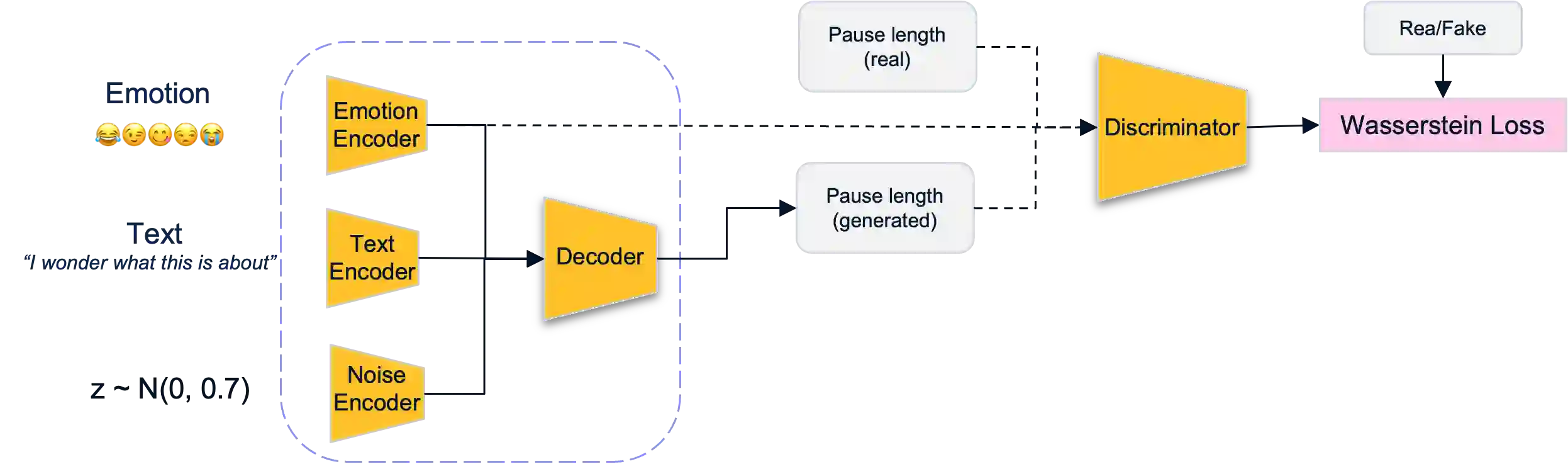
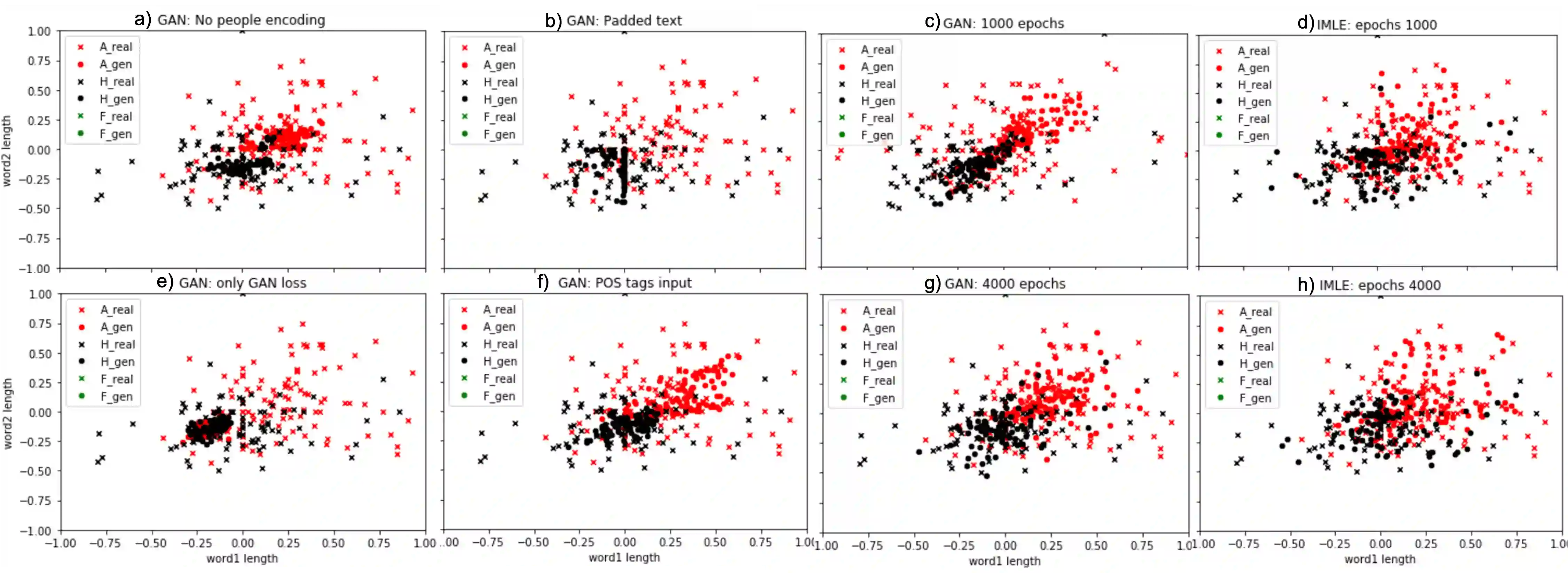
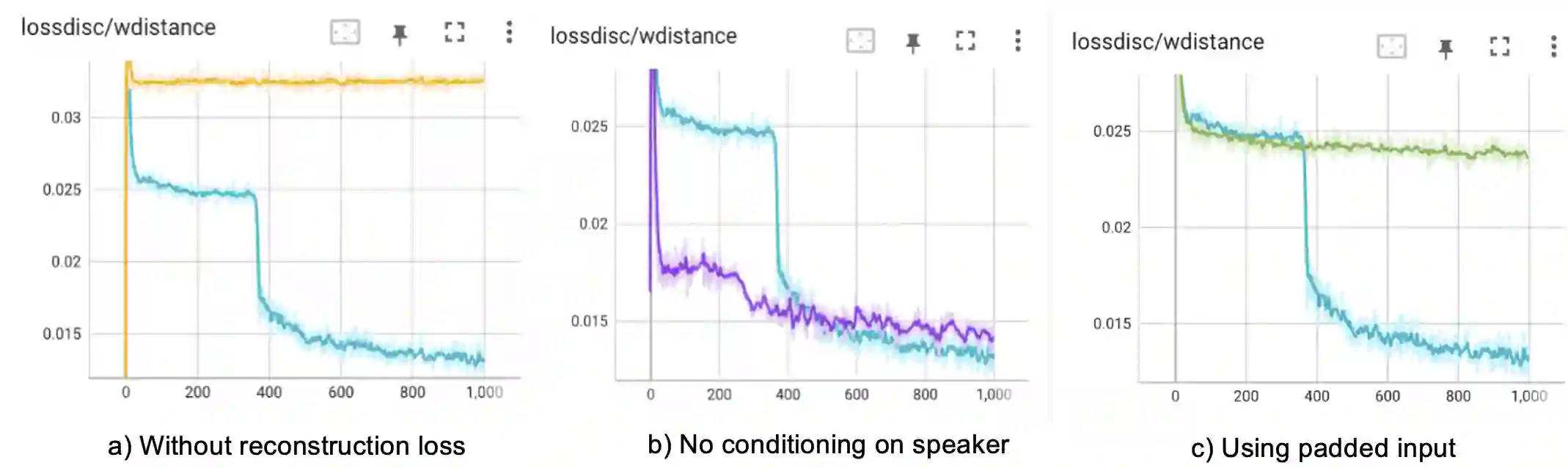
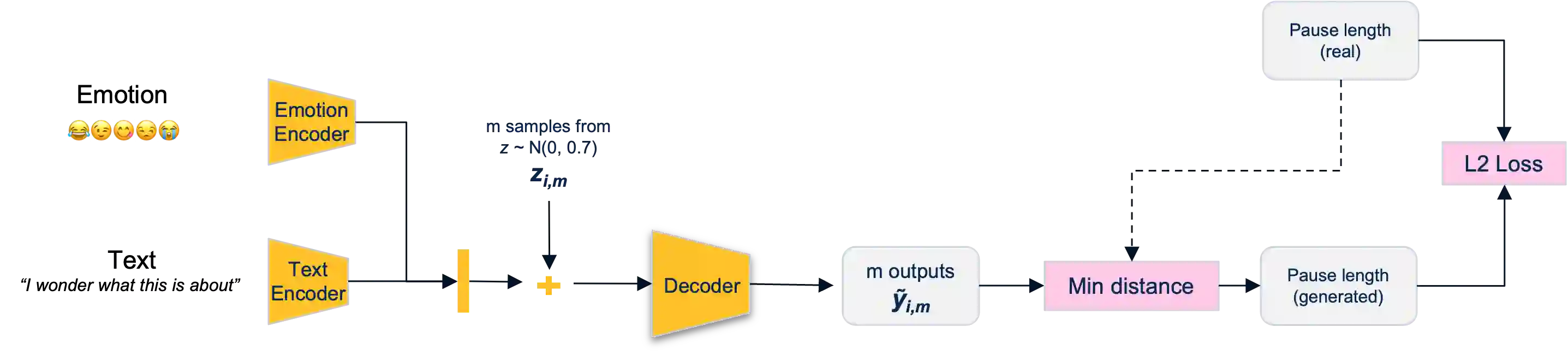
Voice synthesis has seen significant improvements in the past decade resulting in highly intelligible voices. Further investigations have resulted in models that can produce variable speech, including conditional emotional expression. The problem lies, however, in a focus on phrase-level modifications and prosodic vocal features. Using the CREMA-D dataset we have trained a GAN conditioned on emotion to generate worth lengths for a given input text. These word lengths are relative to neutral speech and can be provided, through speech synthesis markup language (SSML) to a text-to-speech (TTS) system to generate more expressive speech. Additionally, a generative model is also trained using implicit maximum likelihood estimation (IMLE) and a comparative analysis with GANs is included. We were able to achieve better performances on objective measures for neutral speech, and better time alignment for happy speech when compared to an out-of-box model. However, further investigation of subjective evaluation is required.
翻译:语音合成在过去十年间取得了显著进展,能够生成高度可理解的语音。进一步的研究产生了可生成可变语音的模型,包括条件性情感表达。然而,问题在于研究重点集中在短语层面的修改和韵律特征上。利用CREMA-D数据集,我们训练了一个以情感为条件的生成对抗网络(GAN),用于生成给定输入文本的单词时长。这些单词时长是相对于中性语音的,可通过语音合成标记语言(SSML)提供给文本到语音(TTS)系统,以生成更具表现力的语音。此外,还使用隐式最大似然估计(IMLE)训练了一个生成模型,并与GAN进行了对比分析。与开箱即用模型相比,我们在客观指标上实现了更好的中性语音性能,以及更优的快乐语音时间对齐。然而,仍需进一步开展主观评估研究。